 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Constrained Deconvolutional Networks for Road Scene Semantic Segmentation
Paper and Code
Apr 06, 2016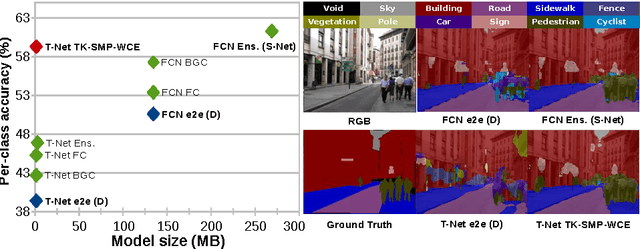
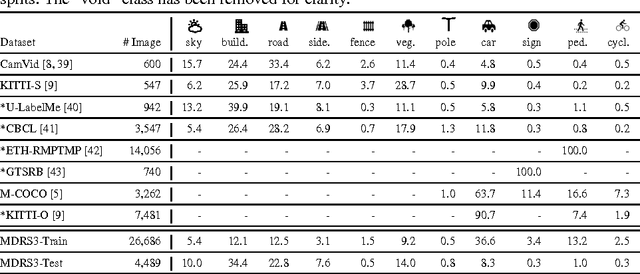

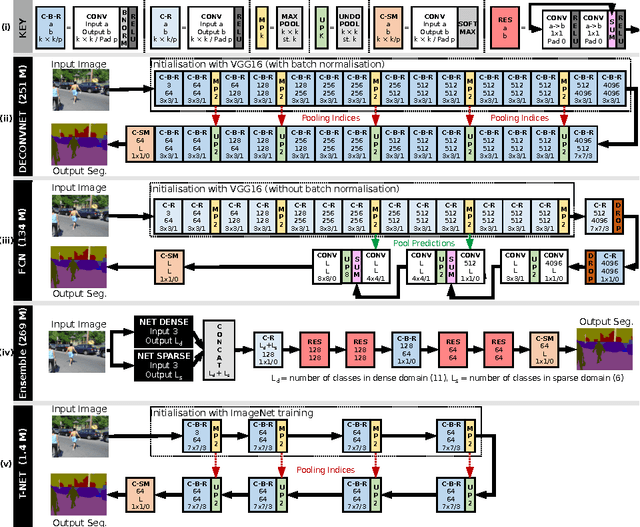
In this work we investigate the problem of road scene semantic segmentation using Deconvolutional Networks (DNs). Several constraints limit the practical performance of DNs in this context: firstly, the paucity of existing pixel-wise labelled training data, and secondly, the memory constraints of embedded hardware, which rule out the practical use of state-of-the-art DN architectures such as fully convolutional networks (FCN). To address the first constraint, we introduce a Multi-Domain Road Scene Semantic Segmentation (MDRS3) dataset, aggregating data from six existing densely and sparsely labelled datasets for training our models, and two existing, separate datasets for testing their generalisation performance. We show that, while MDRS3 offers a greater volume and variety of data, end-to-end training of a memory efficient DN does not yield satisfactory performance. We propose a new training strategy to overcome this, based on (i) the creation of a best-possible source network (S-Net) from the aggregated data, ignoring time and memory constraints; and (ii) the transfer of knowledge from S-Net to the memory-efficient target network (T-Net). We evaluate different techniques for S-Net creation and T-Net transferral, and demonstrate that training a constrained deconvolutional network in this manner can unlock better performance than existing training approaches. Specifically, we show that a target network can be trained to achieve improved accuracy versus an FCN despite using less than 1\% of the memory. We believe that our approach can be useful beyond automotive scenarios where labelled data is similarly scarce or fragmented and where practical constraints exist on the desired model size. We make available our network models and aggregated multi-domain dataset for reproducibility.