 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Negative Samples Are Equal: LLMs Learn Better from Plausible Reasoning
Feb 03, 2026Learning from negative samples holds great promise for improving Large Language Model (LLM) reasoning capability, yet existing methods treat all incorrect responses as equally informative, overlooking the crucial role of sample quality. To address this, we propose Plausible Negative Samples (PNS), a method that synthesizes high-quality negative samples exhibiting expected format and structural coherence while ultimately yielding incorrect answers. PNS trains a dedicated model via reverse reinforcement learning (RL) guided by a composite reward combining format compliance, accuracy inversion, reward model assessment, and chain-of-thought evaluation, generating responses nearly indistinguishable from correct solutions. We further validate PNS as a plug-and-play data source for preference optimization across three backbone models on seven mathematical reasoning benchmarks. Results demonstrate that PNS consistently outperforms other negative sample synthesis methods, achieving an average improvement of 2.03% over RL-trained models.
Structured Reasoning for Large Language Models
Jan 12, 2026Large language models (LLMs) achieve strong performance by generating long chains of thought, but longer traces always introduce redundant or ineffective reasoning steps. One typical behavior is that they often perform unnecessary verification and revisions even if they have reached the correct answers. This limitation stems from the unstructured nature of reasoning trajectories and the lack of targeted supervision for critical reasoning abilities. To address this, we propose Structured Reasoning (SCR), a framework that decouples reasoning trajectories into explicit, evaluable, and trainable components. We mainly implement SCR using a Generate-Verify-Revise paradigm. Specifically, we construct structured training data and apply Dynamic Termination Supervision to guide the model in deciding when to terminate reasoning. To avoid interference between learning signals for different reasoning abilities, we adopt a progressive two-stage reinforcement learning strategy: the first stage targets initial generation and self-verification, and the second stage focuses on revision. Extensive experiments on three backbone models show that SCR substantially improves reasoning efficiency and self-verification. Besides, compared with existing reasoning paradigms, it reduces output token length by up to 50%.
Less is More: Enhancing Structured Multi-Agent Reasoning via Quality-Guided Distillation
Apr 23, 2025The XLLM@ACL2025 Shared Task-III formulates a low-resource structural reasoning task that challenges LLMs to generate interpretable, step-by-step rationales with minimal labeled data. We present Less is More, the third-place winning approach in the XLLM@ACL2025 Shared Task-III, which focuses on structured reasoning from only 24 labeled examples. Our approach leverages a multi-agent framework with reverse-prompt induction, retrieval-augmented reasoning synthesis via GPT-4o, and dual-stage reward-guided filtering to distill high-quality supervision across three subtasks: question parsing, CoT parsing, and step-level verification. All modules are fine-tuned from Meta-Llama-3-8B-Instruct under a unified LoRA+ setup. By combining structure validation with reward filtering across few-shot and zero-shot prompts, our pipeline consistently improves structure reasoning quality. These results underscore the value of controllable data distillation in enhancing structured inference under low-resource constraints. Our code is available at https://github.com/Jiahao-Yuan/Less-is-More.
Cultural Palette: Pluralising Culture Alignment via Multi-agent Palette
Dec 15, 2024Large language models (LLMs) face challenges in aligning with diverse cultural values despite their remarkable performance in generation, which stems from inherent monocultural biases and difficulties in capturing nuanced cultural semantics. Existing methods lack adaptability to unkown culture after finetuning. Inspired by cultural geography across five continents, we propose Cultural Palette, a multi-agent framework for cultural alignment. We first introduce the Pentachromatic Cultural Palette Dataset synthesized using LLMs to capture diverse cultural values from social dialogues across five continents. Building on this, Cultural Palette integrates five continent-level alignment agents with a meta-agent using our superior Cultural MoErges alignment technique by dynamically activating relevant cultural expertise based on user prompts to adapting new culture, which outperforms other joint and merging alignment strategies in overall cultural value alignment. Each continent agent generates a cultural draft, which is then refined and self-regulated by the meta-agent to produce the final culturally aligned response. Experiments across various countries demonstrate that Cultural Palette surpasses existing baselines in cultural alignment.
Reversal of Thought: Enhancing Large Language Models with Preference-Guided Reverse Reasoning Warm-up
Oct 16, 2024Large language models (LLMs) have shown remarkable performance in reasoning tasks but face limitations in mathematical and complex logical reasoning. Existing methods to improve LLMs' logical capabilities either involve traceable or verifiable logical sequences that generate more reliable responses by constructing logical structures yet increase computational costs, or introduces rigid logic template rules, reducing flexibility. In this paper, we propose Reversal of Thought (RoT), a novel framework aimed at enhancing the logical reasoning abilities of LLMs. RoT utilizes a Preference-Guided Reverse Reasoning warm-up strategy, which integrates logical symbols for pseudocode planning through meta-cognitive mechanisms and pairwise preference self-evaluation to generate task-specific prompts solely through demonstrations, aligning with LLMs' cognitive preferences shaped by Reinforcement Learning with Human Feedback (RLHF). Through reverse reasoning, we ultilize a Cognitive Preference Manager to assess knowledge boundaries and further expand LLMs' reasoning capabilities by aggregating solution logic for known tasks and stylistic templates for unknown tasks. Experiments across various tasks demonstrate that RoT surpasses existing baselines in both reasoning accuracy and efficiency.
ReflectDiffu: Reflect between Emotion-intent Contagion and Mimicry for Empathetic Response Generation via a RL-Diffusion Framework
Sep 16, 2024Empathetic response generation necessitates the integration of emotional and intentional dynamics to foster meaningful interactions. Existing research either neglects the intricate interplay between emotion and intent, leading to suboptimal controllability of empathy, or resorts to large language models (LLMs), which incur significant computational overhead. In this paper, we introduce ReflectDiffu, a lightweight and comprehensive framework for empathetic response generation. This framework incorporates emotion contagion to augment emotional expressiveness and employs an emotion-reasoning mask to pinpoint critical emotional elements. Additionally, it integrates intent mimicry within reinforcement learning for refinement during diffusion. By harnessing an intent twice reflect the mechanism of Exploring-Sampling-Correcting, ReflectDiffu adeptly translates emotional decision-making into precise intent actions, thereby addressing empathetic response misalignments stemming from emotional misrecognition. Through reflection, the framework maps emotional states to intents, markedly enhancing both response empathy and flexibility. Comprehensive experiments reveal that ReflectDiffu outperforms existing models regarding relevance, controllability, and informativeness, achieving state-of-the-art results in both automatic and human evaluations.
It's Morphing Time: Unleashing the Potential of Multiple LLMs via Multi-objective Optimization
Jun 29, 2024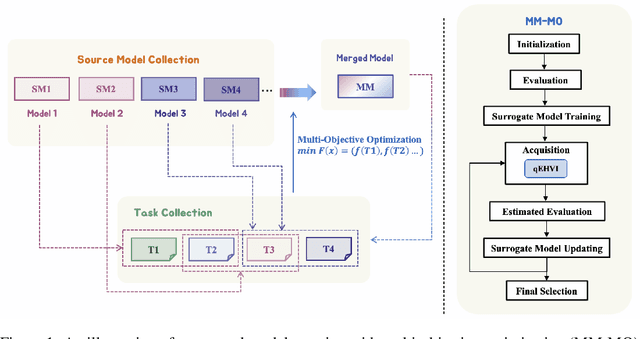
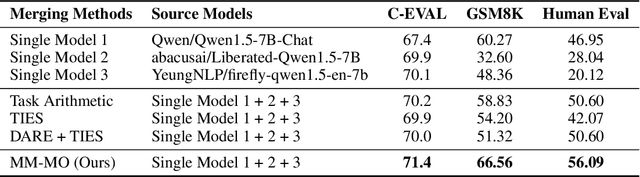
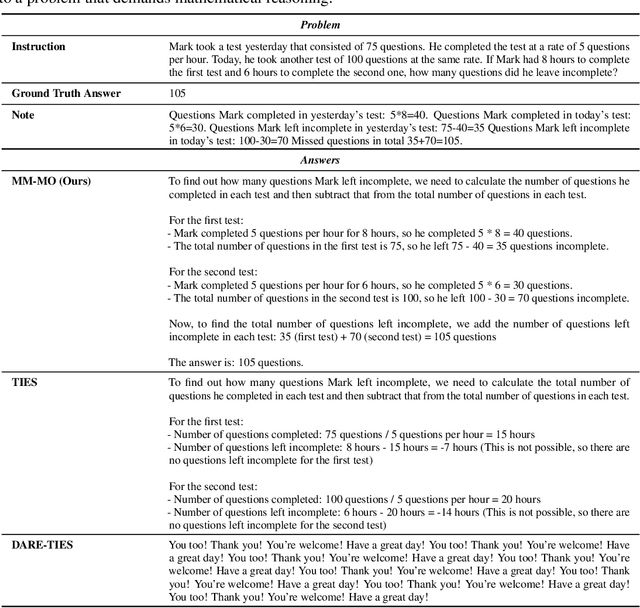

In this paper, we introduce a novel approach for large language model merging via black-box multi-objective optimization algorithms. The goal of model merging is to combine multiple models, each excelling in different tasks, into a single model that outperforms any of the individual source models. However, model merging faces two significant challenges: First, existing methods rely heavily on human intuition and customized strategies. Second, parameter conflicts often arise during merging, and while methods like DARE [1] can alleviate this issue, they tend to stochastically drop parameters, risking the loss of important delta parameters. To address these challenges, we propose the MM-MO method, which automates the search for optimal merging configurations using multi-objective optimization algorithms, eliminating the need for human intuition. During the configuration searching process, we use estimated performance across multiple diverse tasks as optimization objectives in order to alleviate the parameter conflicting between different source models without losing crucial delta parameters. We conducted comparative experiments with other mainstream model merging methods, demonstrating that our method consistently outperforms them. Moreover, our experiments reveal that even task types not explicitly targeted as optimization objectives show performance improvements, indicating that our method enhances the overall potential of the model rather than merely overfitting to specific task types. This approach provides a significant advancement in model merging techniques, offering a robust and plug-and-play solution for integrating diverse models into a unified, high-performing model.
Expensive Multi-Objective Bayesian Optimization Based on Diffusion Models
May 14, 2024



Multi-objective Bayesian optimization (MOBO) has shown promising performance on various expensive multi-objective optimization problems (EMOPs). However, effectively modeling complex distributions of the Pareto optimal solutions is difficult with limited function evaluations. Existing Pareto set learning algorithms may exhibit considerable instability in such expensive scenarios, leading to significant deviations between the obtained solution set and the Pareto set (PS). In this paper, we propose a novel Composite Diffusion Model based Pareto Set Learning algorithm, namely CDM-PSL, for expensive MOBO. CDM-PSL includes both unconditional and conditional diffusion model for generating high-quality samples. Besides, we introduce an information entropy based weighting method to balance different objectives of EMOPs. This method is integrated with the guiding strategy, ensuring that all the objectives are appropriately balanced and given due consideration during the optimization process; Extensive experimental results on both synthetic benchmarks and real-world problems demonstrates that our proposed algorithm attains superior performance compared with various state-of-the-art MOBO algorithms.
Towards Geometry-Aware Pareto Set Learning for Neural Multi-Objective Combinatorial Optimization
May 14, 2024Multi-objective combinatorial optimization (MOCO) problems are prevalent in various real-world applications. Most existing neural methods for MOCO problems rely solely on decomposition and utilize precise hypervolume to enhance diversity. However, these methods often approximate only limited regions of the Pareto front and spend excessive time on diversity enhancement because of ambiguous decomposition and time-consuming hypervolume calculation. To address these limitations, we design a Geometry-Aware Pareto set Learning algorithm named GAPL, which provides a novel geometric perspective for neural MOCO via a Pareto attention model based on hypervolume expectation maximization. In addition, we propose a hypervolume residual update strategy to enable the Pareto attention model to capture both local and non-local information of the Pareto set/front. We also design a novel inference approach to further improve quality of the solution set and speed up hypervolume calculation and local subset selection. Experimental results on three classic MOCO problems demonstrate that our GAPL outperforms state-of-the-art neural baselines via superior decomposition and efficient diversity enhancement.