 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Educational AI Agents
Mar 12, 2026While scaling laws for Large Language Models (LLMs) have been extensively studied along dimensions of model parameters, training data, and compute, the scaling behavior of LLM-based educational agents remains unexplored. We propose that educational agent capability scales not merely with the underlying model size, but through structured dimensions that we collectively term the Agent Scaling Law: role definition clarity, skill depth, tool completeness, runtime capability, and educator expertise injection. Central to this framework is AgentProfile, a structured JSON-based specification that serves as the mechanism enabling systematic capability growth of educational agents. We present EduClaw, a profile-driven multi-agent platform that operationalizes this scaling law, demonstrating its effectiveness through the construction and deployment of 330+ educational agent profiles encompassing 1,100+ skill modules across K-12 subjects. Our empirical observations suggest that educational agent performance scales predictably with profile structural richness. We identify two complementary scaling axes -- Tool Scaling and Skill Scaling -- as future directions, arguing that the path to more capable educational AI lies not solely in larger models, but in stronger structured capability systems.
Automating Skill Acquisition through Large-Scale Mining of Open-Source Agentic Repositories: A Framework for Multi-Agent Procedural Knowledge Extraction
Mar 12, 2026The transition from monolithic large language models (LLMs) to modular, skill-equipped agents represents a fundamental architectural shift in artificial intelligence deployment. While general-purpose models demonstrate remarkable breadth in declarative knowledge, their utility in autonomous workflows is frequently constrained by insufficient specialized procedural expertise. This report investigates a systematic framework for automated acquisition of high-quality agent skills through mining of open-source repositories on platforms such as GitHub. We focus on the extraction of visualization and educational capabilities from state-of-the-art systems including TheoremExplainAgent and Code2Video, both utilizing the Manim mathematical animation engine. The framework encompasses repository structural analysis, semantic skill identification through dense retrieval, and translation to the standardized SKILL.md format. We demonstrate that systematic extraction from agentic repositories, combined with rigorous security governance and multi-dimensional evaluation metrics, enables scalable acquisition of procedural knowledge that augments LLM capabilities without requiring model retraining. Our analysis reveals that agent-generated educational content can achieve 40\% gains in knowledge transfer efficiency while maintaining pedagogical quality comparable to human-crafted tutorials.
See and Remember: A Multimodal Agent for Web Traversal
Mar 03, 2026Autonomous web navigation requires agents to perceive complex visual environments and maintain long-term context, yet current Large Language Model (LLM) based agents often struggle with spatial disorientation and navigation loops. In this paper, we propose generally applicable V-GEMS(Visual Grounding and Explicit Memory System), a robust multimodal agent architecture designed for precise and resilient web traversal. Our agent integrates visual grounding to resolve ambiguous interactive elements and introduces an explicit memory stack with state tracking. This dual mechanism allows the agent to maintain a structured map of its traversal path, enabling valid backtracking and preventing cyclical failures in deep navigation tasks. We also introduce an updatable dynamic benchmark to rigorously evaluate adaptability. Experiments show V-GEMS significantly dominates the WebWalker baseline, achieving a substantial 28.7% performance gain. Code is available at https://github.com/Vaultttttttttttt/V-GEMS.
IB-GRPO: Aligning LLM-based Learning Path Recommendation with Educational Objectives via Indicator-Based Group Relative Policy Optimization
Jan 21, 2026Learning Path Recommendation (LPR) aims to generate personalized sequences of learning items that maximize long-term learning effect while respecting pedagogical principles and operational constraints. Although large language models (LLMs) offer rich semantic understanding for free-form recommendation, applying them to long-horizon LPR is challenging due to (i) misalignment with pedagogical objectives such as the Zone of Proximal Development (ZPD) under sparse, delayed feedback, (ii) scarce and costly expert demonstrations, and (iii) multi-objective interactions among learning effect, difficulty scheduling, length controllability, and trajectory diversity. To address these issues, we propose IB-GRPO (Indicator-Based Group Relative Policy Optimization), an indicator-guided alignment approach for LLM-based LPR. To mitigate data scarcity, we construct hybrid expert demonstrations via Genetic Algorithm search and teacher RL agents and warm-start the LLM with supervised fine-tuning. Building on this warm-start, we design a within-session ZPD alignment score for difficulty scheduling. IB-GRPO then uses the $I_{ε+}$ dominance indicator to compute group-relative advantages over multiple objectives, avoiding manual scalarization and improving Pareto trade-offs. Experiments on ASSIST09 and Junyi using the KES simulator with a Qwen2.5-7B backbone show consistent improvements over representative RL and LLM baselines.
AutoSynth: Automated Workflow Optimization for High-Quality Synthetic Dataset Generation via Monte Carlo Tree Search
Nov 12, 2025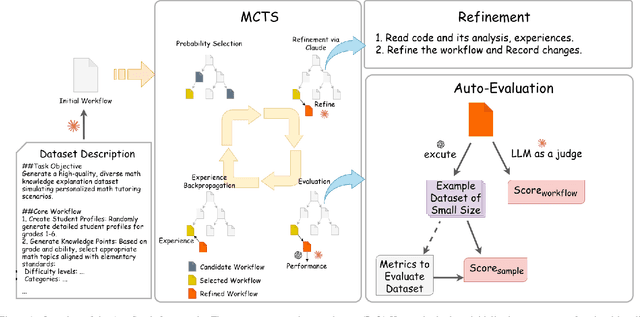


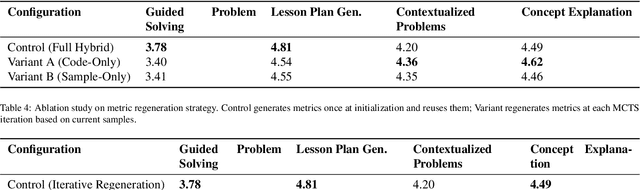
Supervised fine-tuning (SFT) of large language models (LLMs) for specialized tasks requires high-quality datasets, but manual curation is prohibitively expensive. Synthetic data generation offers scalability, but its effectiveness relies on complex, multi-stage workflows, integrating prompt engineering and model orchestration. Existing automated workflow methods face a cold start problem: they require labeled datasets for reward modeling, which is especially problematic for subjective, open-ended tasks with no objective ground truth. We introduce AutoSynth, a framework that automates workflow discovery and optimization without reference datasets by reframing the problem as a Monte Carlo Tree Search guided by a novel dataset-free hybrid reward. This reward enables meta-learning through two LLM-as-judge components: one evaluates sample quality using dynamically generated task-specific metrics, and another assesses workflow code and prompt quality. Experiments on subjective educational tasks show that while expert-designed workflows achieve higher human preference rates (96-99% win rates vs. AutoSynth's 40-51%), models trained on AutoSynth-generated data dramatically outperform baselines (40-51% vs. 2-5%) and match or surpass expert workflows on certain metrics, suggesting discovery of quality dimensions beyond human intuition. These results are achieved while reducing human effort from 5-7 hours to just 30 minutes (>90% reduction). AutoSynth tackles the cold start issue in data-centric AI, offering a scalable, cost-effective method for subjective LLM tasks. Code: https://github.com/bisz9918-maker/AutoSynth.
SID: Benchmarking Guided Instruction Capabilities in STEM Education with a Socratic Interdisciplinary Dialogues Dataset
Aug 06, 2025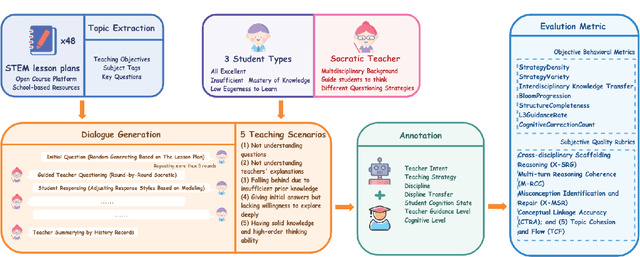
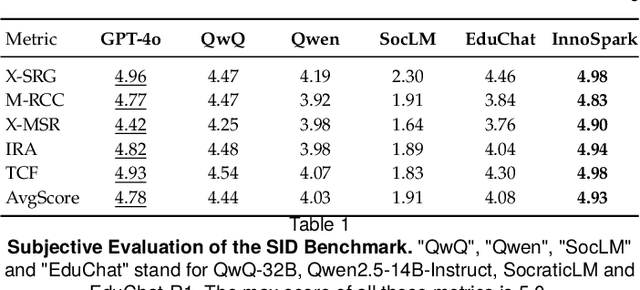
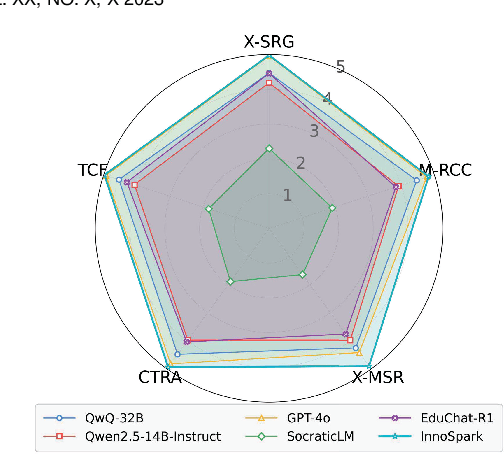
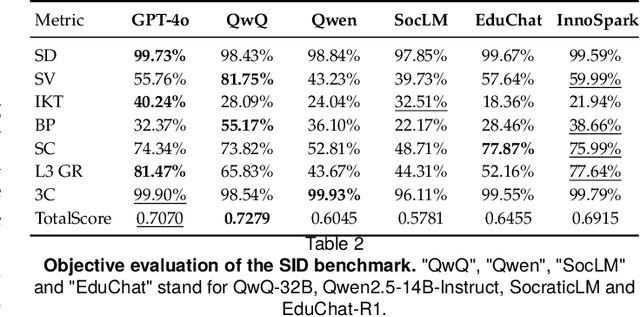
Fostering students' abilities for knowledge integration and transfer in complex problem-solving scenarios is a core objective of modern education, and interdisciplinary STEM is a key pathway to achieve this, yet it requires expert guidance that is difficult to scale. While LLMs offer potential in this regard, their true capability for guided instruction remains unclear due to the lack of an effective evaluation benchmark. To address this, we introduce SID, the first benchmark designed to systematically evaluate the higher-order guidance capabilities of LLMs in multi-turn, interdisciplinary Socratic dialogues. Our contributions include a large-scale dataset of 10,000 dialogue turns across 48 complex STEM projects, a novel annotation schema for capturing deep pedagogical features, and a new suite of evaluation metrics (e.g., X-SRG). Baseline experiments confirm that even state-of-the-art LLMs struggle to execute effective guided dialogues that lead students to achieve knowledge integration and transfer. This highlights the critical value of our benchmark in driving the development of more pedagogically-aware LLMs.
Cultivating Helpful, Personalized, and Creative AI Tutors: A Framework for Pedagogical Alignment using Reinforcement Learning
Jul 27, 2025
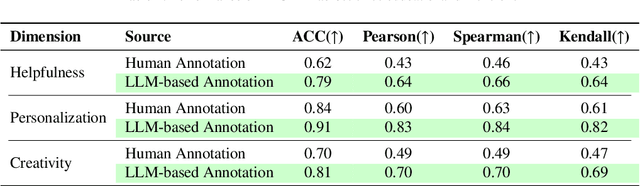

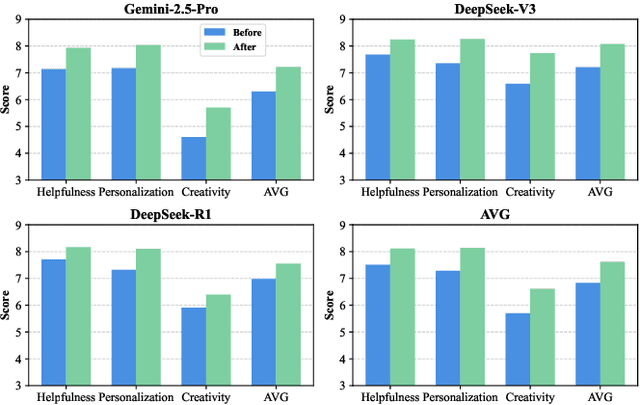
The integration of large language models (LLMs) into education presents unprecedented opportunities for scalable personalized learning. However, standard LLMs often function as generic information providers, lacking alignment with fundamental pedagogical principles such as helpfulness, student-centered personalization, and creativity cultivation. To bridge this gap, we propose EduAlign, a novel framework designed to guide LLMs toward becoming more effective and responsible educational assistants. EduAlign consists of two main stages. In the first stage, we curate a dataset of 8k educational interactions and annotate them-both manually and automatically-along three key educational dimensions: Helpfulness, Personalization, and Creativity (HPC). These annotations are used to train HPC-RM, a multi-dimensional reward model capable of accurately scoring LLM outputs according to these educational principles. We further evaluate the consistency and reliability of this reward model. In the second stage, we leverage HPC-RM as a reward signal to fine-tune a pre-trained LLM using Group Relative Policy Optimization (GRPO) on a set of 2k diverse prompts. We then assess the pre- and post-finetuning models on both educational and general-domain benchmarks across the three HPC dimensions. Experimental results demonstrate that the fine-tuned model exhibits significantly improved alignment with pedagogical helpfulness, personalization, and creativity stimulation. This study presents a scalable and effective approach to aligning LLMs with nuanced and desirable educational traits, paving the way for the development of more engaging, pedagogically aligned AI tutors.
Un-evaluated Solutions May Be Valuable in Expensive Optimization
Dec 05, 2024Expensive optimization problems (EOPs) are prevalent in real-world applications, where the evaluation of a single solution requires a significant amount of resources. In our study of surrogate-assisted evolutionary algorithms (SAEAs) in EOPs, we discovered an intriguing phenomenon. Because only a limited number of solutions are evaluated in each iteration, relying solely on these evaluated solutions for evolution can lead to reduced disparity in successive populations. This, in turn, hampers the reproduction operators' ability to generate superior solutions, thereby reducing the algorithm's convergence speed. To address this issue, we propose a strategic approach that incorporates high-quality, un-evaluated solutions predicted by surrogate models during the selection phase. This approach aims to improve the distribution of evaluated solutions, thereby generating a superior next generation of solutions. This work details specific implementations of this concept across various reproduction operators and validates its effectiveness using multiple surrogate models. Experimental results demonstrate that the proposed strategy significantly enhances the performance of surrogate-assisted evolutionary algorithms. Compared to mainstream SAEAs and Bayesian optimization algorithms, our approach incorporating the un-evaluated solution strategy shows a marked improvement.
It's Morphing Time: Unleashing the Potential of Multiple LLMs via Multi-objective Optimization
Jun 29, 2024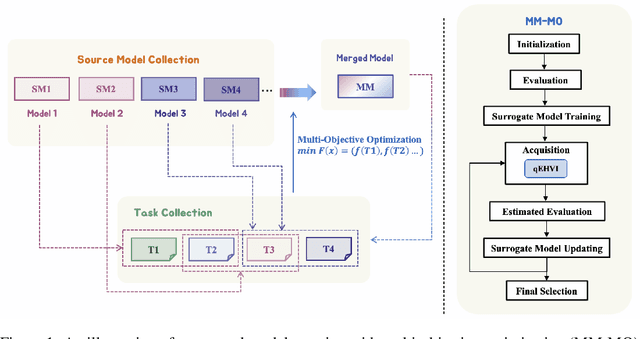
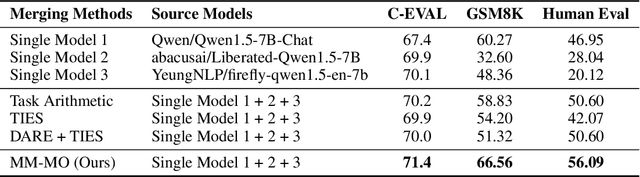
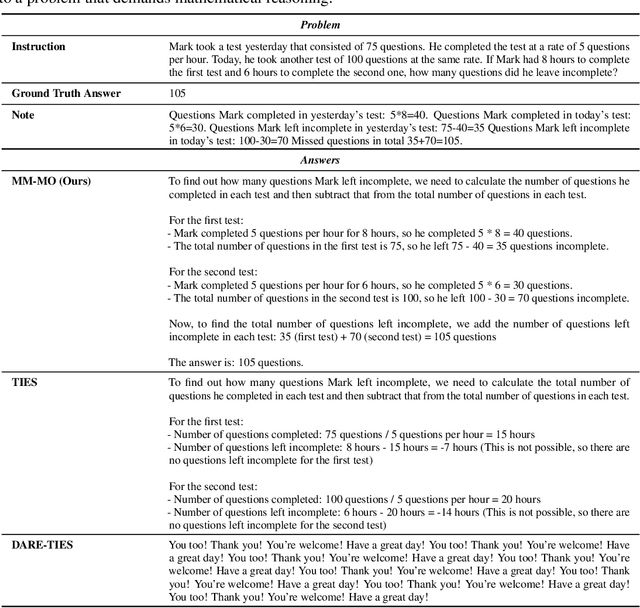

In this paper, we introduce a novel approach for large language model merging via black-box multi-objective optimization algorithms. The goal of model merging is to combine multiple models, each excelling in different tasks, into a single model that outperforms any of the individual source models. However, model merging faces two significant challenges: First, existing methods rely heavily on human intuition and customized strategies. Second, parameter conflicts often arise during merging, and while methods like DARE [1] can alleviate this issue, they tend to stochastically drop parameters, risking the loss of important delta parameters. To address these challenges, we propose the MM-MO method, which automates the search for optimal merging configurations using multi-objective optimization algorithms, eliminating the need for human intuition. During the configuration searching process, we use estimated performance across multiple diverse tasks as optimization objectives in order to alleviate the parameter conflicting between different source models without losing crucial delta parameters. We conducted comparative experiments with other mainstream model merging methods, demonstrating that our method consistently outperforms them. Moreover, our experiments reveal that even task types not explicitly targeted as optimization objectives show performance improvements, indicating that our method enhances the overall potential of the model rather than merely overfitting to specific task types. This approach provides a significant advancement in model merging techniques, offering a robust and plug-and-play solution for integrating diverse models into a unified, high-performing model.
Large Language Models as Surrogate Models in Evolutionary Algorithms: A Preliminary Study
Jun 15, 2024



Large Language Models (LLMs) have achieved significant progress across various fields and have exhibited strong potential in evolutionary computation, such as generating new solutions and automating algorithm design. Surrogate-assisted selection is a core step in evolutionary algorithms to solve expensive optimization problems by reducing the number of real evaluations. Traditionally, this has relied on conventional machine learning methods, leveraging historical evaluated evaluations to predict the performance of new solutions. In this work, we propose a novel surrogate model based purely on LLM inference capabilities, eliminating the need for training. Specifically, we formulate model-assisted selection as a classification and regression problem, utilizing LLMs to directly evaluate the quality of new solutions based on historical data. This involves predicting whether a solution is good or bad, or approximating its value. This approach is then integrated into evolutionary algorithms, termed LLM-assisted EA (LAEA). Detailed experiments compared the visualization results of 2D data from 9 mainstream LLMs, as well as their performance on optimization problems. The experimental results demonstrate that LLMs have significant potential as surrogate models in evolutionary computation, achieving performance comparable to traditional surrogate models only using inference. This work offers new insights into the application of LLMs in evolutionary computation. Code is available at: https://github.com/hhyqhh/LAEA.git