 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery via Quantile Partial Effect
Sep 16, 2025



Quantile Partial Effect (QPE) is a statistic associated with conditional quantile regression, measuring the effect of covariates at different levels. Our theory demonstrates that when the QPE of cause on effect is assumed to lie in a finite linear span, cause and effect are identifiable from their observational distribution. This generalizes previous identifiability results based on Functional Causal Models (FCMs) with additive, heteroscedastic noise, etc. Meanwhile, since QPE resides entirely at the observational level, this parametric assumption does not require considering mechanisms, noise, or even the Markov assumption, but rather directly utilizes the asymmetry of shape characteristics in the observational distribution. By performing basis function tests on the estimated QPE, causal directions can be distinguished, which is empirically shown to be effective in experiments on a large number of bivariate causal discovery datasets. For multivariate causal discovery, leveraging the close connection between QPE and score functions, we find that Fisher Information is sufficient as a statistical measure to determine causal order when assumptions are made about the second moment of QPE. We validate the feasibility of using Fisher Information to identify causal order on multiple synthetic and real-world multivariate causal discovery datasets.
Exogenous Isomorphism for Counterfactual Identifiability
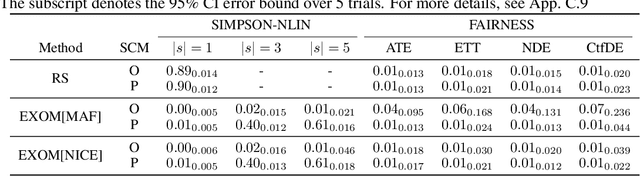
May 04, 2025This paper investigates $\sim_{\mathcal{L}_3}$-identifiability, a form of complete counterfactual identifiability within the Pearl Causal Hierarchy (PCH) framework, ensuring that all Structural Causal Models (SCMs) satisfying the given assumptions provide consistent answers to all causal questions. To simplify this problem, we introduce exogenous isomorphism and propose $\sim_{\mathrm{EI}}$-identifiability, reflecting the strength of model identifiability required for $\sim_{\mathcal{L}_3}$-identifiability. We explore sufficient assumptions for achieving $\sim_{\mathrm{EI}}$-identifiability in two special classes of SCMs: Bijective SCMs (BSCMs), based on counterfactual transport, and Triangular Monotonic SCMs (TM-SCMs), which extend $\sim_{\mathcal{L}_2}$-identifiability. Our results unify and generalize existing theories, providing theoretical guarantees for practical applications. Finally, we leverage neural TM-SCMs to address the consistency problem in counterfactual reasoning, with experiments validating both the effectiveness of our method and the correctness of the theory.
Exogenous Matching: Learning Good Proposals for Tractable Counterfactual Estimation
Oct 24, 2024


We propose an importance sampling method for tractable and efficient estimation of counterfactual expressions in general settings, named Exogenous Matching. By minimizing a common upper bound of counterfactual estimators, we transform the variance minimization problem into a conditional distribution learning problem, enabling its integration with existing conditional distribution modeling approaches. We validate the theoretical results through experiments under various types and settings of Structural Causal Models (SCMs) and demonstrate the outperformance on counterfactual estimation tasks compared to other existing importance sampling methods. We also explore the impact of injecting structural prior knowledge (counterfactual Markov boundaries) on the results. Finally, we apply this method to identifiable proxy SCMs and demonstrate the unbiasedness of the estimates, empirically illustrating the applicability of the method to practical scenarios.
CIER: A Novel Experience Replay Approach with Causal Inference in Deep Reinforcement Learning
May 14, 2024In the training process of Deep Reinforcement Learning (DRL), agents require repetitive interactions with the environment. With an increase in training volume and model complexity, it is still a challenging problem to enhance data utilization and explainability of DRL training. This paper addresses these challenges by focusing on the temporal correlations within the time dimension of time series. We propose a novel approach to segment multivariate time series into meaningful subsequences and represent the time series based on these subsequences. Furthermore, the subsequences are employed for causal inference to identify fundamental causal factors that significantly impact training outcomes. We design a module to provide feedback on the causality during DRL training. Several experiments demonstrate the feasibility of our approach in common environments, confirming its ability to enhance the effectiveness of DRL training and impart a certain level of explainability to the training process. Additionally, we extended our approach with priority experience replay algorithm, and experimental results demonstrate the continued effectiveness of our approach.