 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDFormer:When Degradation Prediction Embraces Diffusion Model for Blind Image Super-Resolution
May 13, 2024

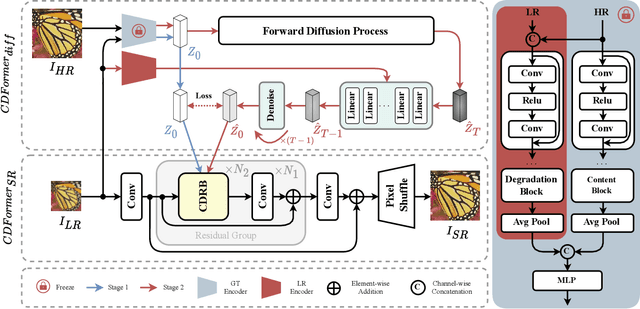

Existing Blind image Super-Resolution (BSR) methods focus on estimating either kernel or degradation information, but have long overlooked the essential content details. In this paper, we propose a novel BSR approach, Content-aware Degradation-driven Transformer (CDFormer), to capture both degradation and content representations. However, low-resolution images cannot provide enough content details, and thus we introduce a diffusion-based module $CDFormer_{diff}$ to first learn Content Degradation Prior (CDP) in both low- and high-resolution images, and then approximate the real distribution given only low-resolution information. Moreover, we apply an adaptive SR network $CDFormer_{SR}$ that effectively utilizes CDP to refine features. Compared to previous diffusion-based SR methods, we treat the diffusion model as an estimator that can overcome the limitations of expensive sampling time and excessive diversity. Experiments show that CDFormer can outperform existing methods, establishing a new state-of-the-art performance on various benchmarks under blind settings. Codes and models will be available at \href{https://github.com/I2-Multimedia-Lab/CDFormer}{https://github.com/I2-Multimedia-Lab/CDFormer}.
Degradation-Aware Self-Attention Based Transformer for Blind Image Super-Resolution
Oct 06, 2023



Compared to CNN-based methods, Transformer-based methods achieve impressive image restoration outcomes due to their abilities to model remote dependencies. However, how to apply Transformer-based methods to the field of blind super-resolution (SR) and further make an SR network adaptive to degradation information is still an open problem. In this paper, we propose a new degradation-aware self-attention-based Transformer model, where we incorporate contrastive learning into the Transformer network for learning the degradation representations of input images with unknown noise. In particular, we integrate both CNN and Transformer components into the SR network, where we first use the CNN modulated by the degradation information to extract local features, and then employ the degradation-aware Transformer to extract global semantic features. We apply our proposed model to several popular large-scale benchmark datasets for testing, and achieve the state-of-the-art performance compared to existing methods. In particular, our method yields a PSNR of 32.43 dB on the Urban100 dataset at $\times$2 scale, 0.94 dB higher than DASR, and 26.62 dB on the Urban100 dataset at $\times$4 scale, 0.26 dB improvement over KDSR, setting a new benchmark in this area. Source code is available at: https://github.com/I2-Multimedia-Lab/DSAT/tree/main.