 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIFSplat: Generative Prior-Guided Iterative Feed-Forward 3D Gaussian Splatting from Sparse Views
Feb 26, 2026Feed-forward 3D reconstruction offers substantial runtime advantages over per-scene optimization, which remains slow at inference and often fragile under sparse views. However, existing feed-forward methods still have potential for further performance gains, especially for out-of-domain data, and struggle to retain second-level inference time once a generative prior is introduced. These limitations stem from the one-shot prediction paradigm in existing feed-forward pipeline: models are strictly bounded by capacity, lack inference-time refinement, and are ill-suited for continuously injecting generative priors. We introduce GIFSplat, a purely feed-forward iterative refinement framework for 3D Gaussian Splatting from sparse unposed views. A small number of forward-only residual updates progressively refine current 3D scene using rendering evidence, achieve favorable balance between efficiency and quality. Furthermore, we distill a frozen diffusion prior into Gaussian-level cues from enhanced novel renderings without gradient backpropagation or ever-increasing view-set expansion, thereby enabling per-scene adaptation with generative prior while preserving feed-forward efficiency. Across DL3DV, RealEstate10K, and DTU, GIFSplat consistently outperforms state-of-the-art feed-forward baselines, improving PSNR by up to +2.1 dB, and it maintains second-scale inference time without requiring camera poses or any test-time gradient optimization.
Spectrally Distilled Representations Aligned with Instruction-Augmented LLMs for Satellite Imagery
Feb 26, 2026Vision-language foundation models (VLFMs) promise zero-shot and retrieval understanding for Earth observation. While operational satellite systems often lack full multi-spectral coverage, making RGB-only inference highly desirable for scalable deployment, the adoption of VLFMs for satellite imagery remains hindered by two factors: (1) multi-spectral inputs are informative but difficult to exploit consistently due to band redundancy and misalignment; and (2) CLIP-style text encoders limit semantic expressiveness and weaken fine-grained alignment. We present SATtxt, a spectrum-aware VLFM that operates with RGB inputs only at inference while retaining spectral cues learned during training. Our framework comprises two stages. First, Spectral Representation Distillation transfers spectral priors from a frozen multi-spectral teacher to an RGB student via a lightweight projector. Second, Spectrally Grounded Alignment with Instruction-Augmented LLMs bridges the distilled visual space and an expressive LLM embedding space. Across EuroSAT, BigEarthNet, and ForestNet, SATtxt improves zero-shot classification on average by 4.2%, retrieval by 5.9%, and linear probing by 2.7% over baselines, showing an efficient path toward spectrum-aware vision-language learning for Earth observation. Project page: https://ikhado.github.io/sattxt/
SwiftNDC: Fast Neural Depth Correction for High-Fidelity 3D Reconstruction
Feb 26, 2026Depth-guided 3D reconstruction has gained popularity as a fast alternative to optimization-heavy approaches, yet existing methods still suffer from scale drift, multi-view inconsistencies, and the need for substantial refinement to achieve high-fidelity geometry. Here, we propose SwiftNDC, a fast and general framework built around a Neural Depth Correction field that produces cross-view consistent depth maps. From these refined depths, we generate a dense point cloud through back-projection and robust reprojection-error filtering, obtaining a clean and uniformly distributed geometric initialization for downstream reconstruction. This reliable dense geometry substantially accelerates 3D Gaussian Splatting (3DGS) for mesh reconstruction, enabling high-quality surfaces with significantly fewer optimization iterations. For novel-view synthesis, SwiftNDC can also improve 3DGS rendering quality, highlighting the benefits of strong geometric initialization. We conduct a comprehensive study across five datasets, including two for mesh reconstruction, as well as three for novel-view synthesis. SwiftNDC consistently reduces running time for accurate mesh reconstruction and boosts rendering fidelity for view synthesis, demonstrating the effectiveness of combining neural depth refinement with robust geometric initialization for high-fidelity and efficient 3D reconstruction.
Degradation-Aware Self-Attention Based Transformer for Blind Image Super-Resolution
Oct 06, 2023



Compared to CNN-based methods, Transformer-based methods achieve impressive image restoration outcomes due to their abilities to model remote dependencies. However, how to apply Transformer-based methods to the field of blind super-resolution (SR) and further make an SR network adaptive to degradation information is still an open problem. In this paper, we propose a new degradation-aware self-attention-based Transformer model, where we incorporate contrastive learning into the Transformer network for learning the degradation representations of input images with unknown noise. In particular, we integrate both CNN and Transformer components into the SR network, where we first use the CNN modulated by the degradation information to extract local features, and then employ the degradation-aware Transformer to extract global semantic features. We apply our proposed model to several popular large-scale benchmark datasets for testing, and achieve the state-of-the-art performance compared to existing methods. In particular, our method yields a PSNR of 32.43 dB on the Urban100 dataset at $\times$2 scale, 0.94 dB higher than DASR, and 26.62 dB on the Urban100 dataset at $\times$4 scale, 0.26 dB improvement over KDSR, setting a new benchmark in this area. Source code is available at: https://github.com/I2-Multimedia-Lab/DSAT/tree/main.
Edit-DiffNeRF: Editing 3D Neural Radiance Fields using 2D Diffusion Model
Jun 15, 2023Recent research has demonstrated that the combination of pretrained diffusion models with neural radiance fields (NeRFs) has emerged as a promising approach for text-to-3D generation. Simply coupling NeRF with diffusion models will result in cross-view inconsistency and degradation of stylized view syntheses. To address this challenge, we propose the Edit-DiffNeRF framework, which is composed of a frozen diffusion model, a proposed delta module to edit the latent semantic space of the diffusion model, and a NeRF. Instead of training the entire diffusion for each scene, our method focuses on editing the latent semantic space in frozen pretrained diffusion models by the delta module. This fundamental change to the standard diffusion framework enables us to make fine-grained modifications to the rendered views and effectively consolidate these instructions in a 3D scene via NeRF training. As a result, we are able to produce an edited 3D scene that faithfully aligns to input text instructions. Furthermore, to ensure semantic consistency across different viewpoints, we propose a novel multi-view semantic consistency loss that extracts a latent semantic embedding from the input view as a prior, and aim to reconstruct it in different views. Our proposed method has been shown to effectively edit real-world 3D scenes, resulting in 25% improvement in the alignment of the performed 3D edits with text instructions compared to prior work.
Volume Feature Rendering for Fast Neural Radiance Field Reconstruction
May 31, 2023

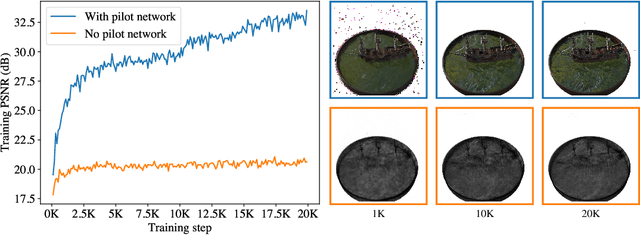

Neural radiance fields (NeRFs) are able to synthesize realistic novel views from multi-view images captured from distinct positions and perspectives. In NeRF's rendering pipeline, neural networks are used to represent a scene independently or transform queried learnable feature vector of a point to the expected color or density. With the aid of geometry guides either in occupancy grids or proposal networks, the number of neural network evaluations can be reduced from hundreds to dozens in the standard volume rendering framework. Instead of rendering yielded color after neural network evaluation, we propose to render the queried feature vectors of a ray first and then transform the rendered feature vector to the final pixel color by a neural network. This fundamental change to the standard volume rendering framework requires only one single neural network evaluation to render a pixel, which substantially lowers the high computational complexity of the rendering framework attributed to a large number of neural network evaluations. Consequently, we can use a comparably larger neural network to achieve a better rendering quality while maintaining the same training and rendering time costs. Our model achieves the state-of-the-art rendering quality on both synthetic and real-world datasets while requiring a training time of several minutes.
Multiscale Tensor Decomposition and Rendering Equation Encoding for View Synthesis
Mar 07, 2023

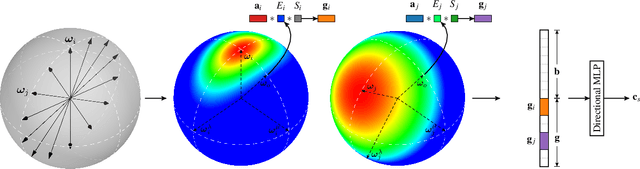
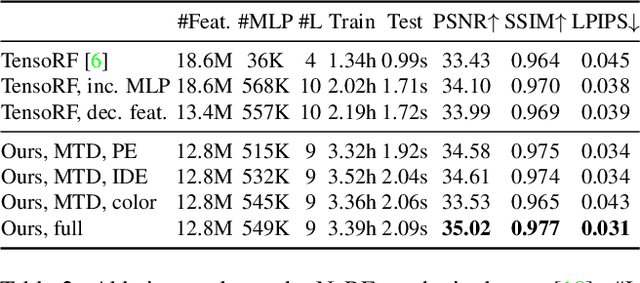
Rendering novel views from captured multi-view images has made considerable progress since the emergence of the neural radiance field. This paper aims to further advance the quality of view rendering by proposing a novel approach dubbed the neural radiance feature field (NRFF) which represents scenes in the feature space. We first propose a multiscale tensor decomposition scheme to organize learnable features so as to represent scenes from coarse to fine scales. We demonstrate many benefits of the proposed multiscale representation, including more accurate scene shape and appearance reconstruction, and faster convergence compared with the single-scale representation. Instead of encoding view directions to model view-dependent effects, we further propose to encode the rendering equation in the feature space by employing the anisotropic spherical Gaussian mixture predicted from the proposed multiscale representation. The proposed NRFF improves state-of-the-art rendering results by over 1 dB in PSNR on both the NeRF and NSVF synthetic datasets. A significant improvement has also been observed on the real-world Tanks and Temples dataset.
Deep Spatial Regression Model for Image Crowd Counting
Oct 26, 2017

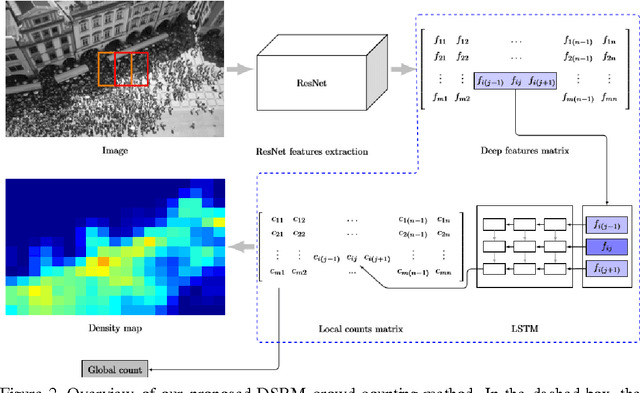

Computer vision techniques have been used to produce accurate and generic crowd count estimators in recent years. Due to severe occlusions, appearance variations, perspective distortions and illumination conditions, crowd counting is a very challenging task. To this end, we propose a deep spatial regression model(DSRM) for counting the number of individuals present in a still image with arbitrary perspective and arbitrary resolution. Our proposed model is based on Convolutional Neural Network (CNN) and long short term memory (LSTM). First, we put the images into a pretrained CNN to extract a set of high-level features. Then the features in adjacent regions are used to regress the local counts with a LSTM structure which takes the spatial information into consideration. The final global count is obtained by a sum of the local patches. We apply our framework on several challenging crowd counting datasets, and the experiment results illustrate that our method on the crowd counting and density estimation problem outperforms state-of-the-art methods in terms of reliability and effectiveness.
Image Crowd Counting Using Convolutional Neural Network and Markov Random Field
Oct 17, 2017
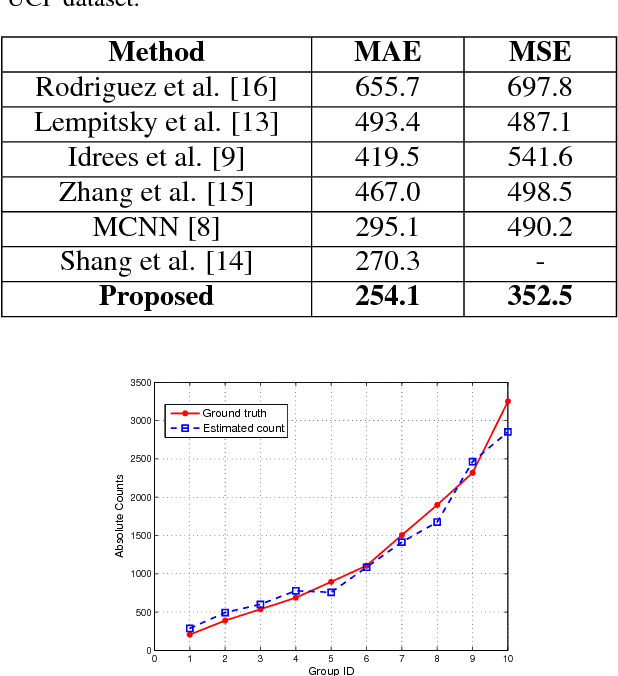
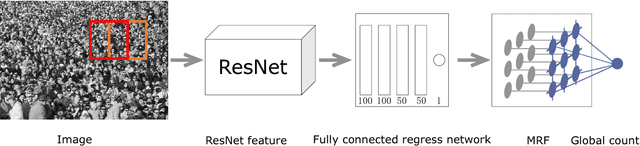
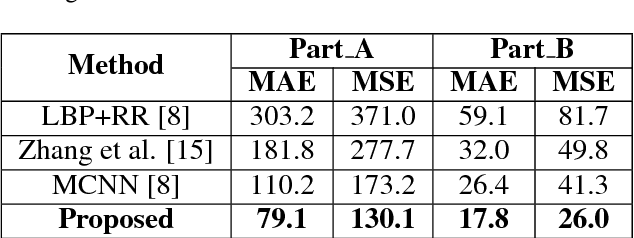
In this paper, we propose a method called Convolutional Neural Network-Markov Random Field (CNN-MRF) to estimate the crowd count in a still image. We first divide the dense crowd visible image into overlapping patches and then use a deep convolutional neural network to extract features from each patch image, followed by a fully connected neural network to regress the local patch crowd count. Since the local patches have overlapping portions, the crowd count of the adjacent patches has a high correlation. We use this correlation and the Markov random field to smooth the counting results of the local patches. Experiments show that our approach significantly outperforms the state-of-the-art methods on UCF and Shanghaitech crowd counting datasets.
* 6 pages, 6 figures, JACIII Vol.21 No.4