 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Graph Interaction Transformer with Dynamic Token Clustering for Camouflaged Object Detection
Aug 27, 2024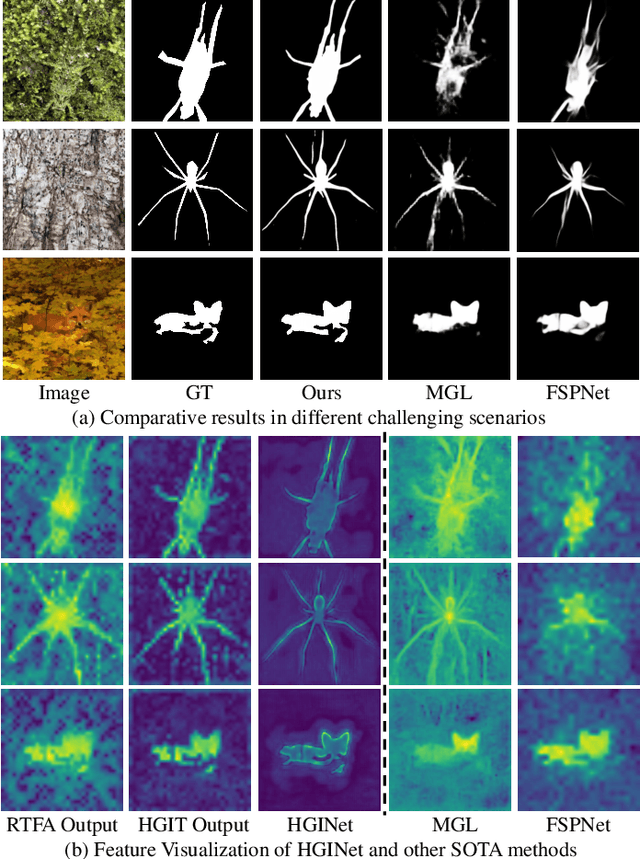
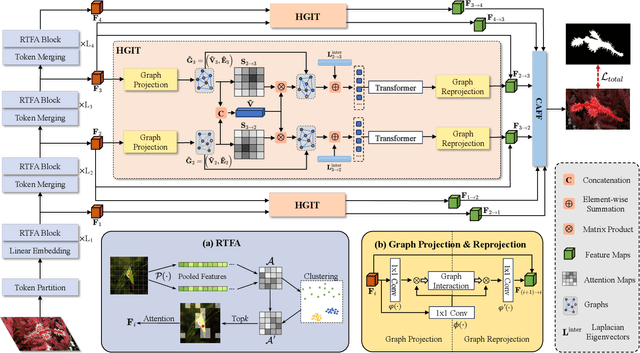
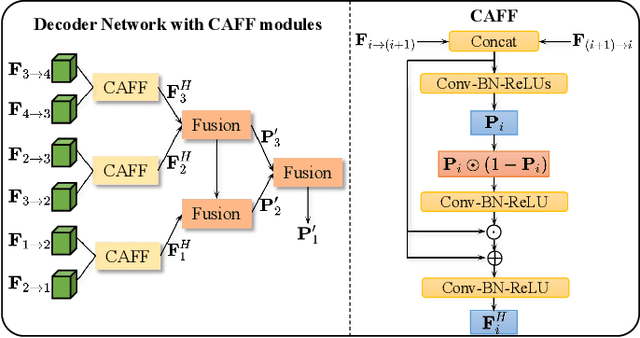

Camouflaged object detection (COD) aims to identify the objects that seamlessly blend into the surrounding backgrounds. Due to the intrinsic similarity between the camouflaged objects and the background region, it is extremely challenging to precisely distinguish the camouflaged objects by existing approaches. In this paper, we propose a hierarchical graph interaction network termed HGINet for camouflaged object detection, which is capable of discovering imperceptible objects via effective graph interaction among the hierarchical tokenized features. Specifically, we first design a region-aware token focusing attention (RTFA) with dynamic token clustering to excavate the potentially distinguishable tokens in the local region. Afterwards, a hierarchical graph interaction transformer (HGIT) is proposed to construct bi-directional aligned communication between hierarchical features in the latent interaction space for visual semantics enhancement. Furthermore, we propose a decoder network with confidence aggregated feature fusion (CAFF) modules, which progressively fuses the hierarchical interacted features to refine the local detail in ambiguous regions. Extensive experiments conducted on the prevalent datasets, i.e. COD10K, CAMO, NC4K and CHAMELEON demonstrate the superior performance of HGINet compared to existing state-of-the-art methods. Our code is available at https://github.com/Garyson1204/HGINet.
Adaptive Guidance Learning for Camouflaged Object Detection
May 07, 2024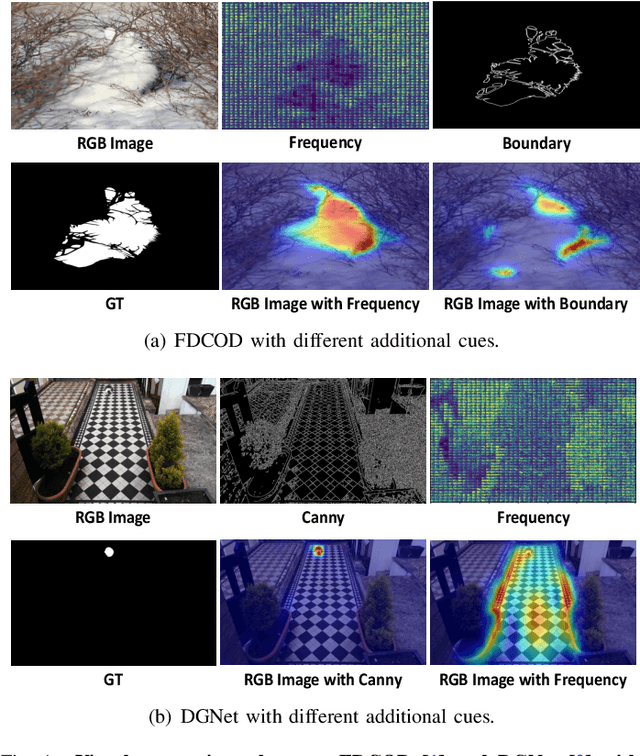
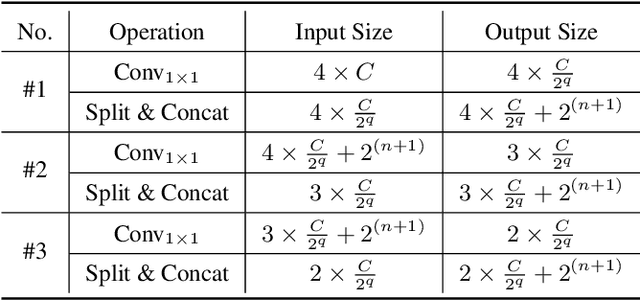

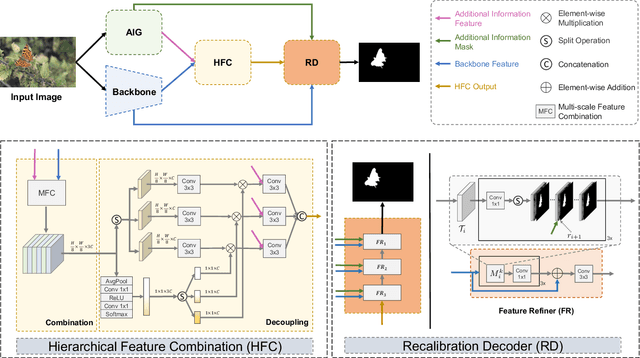
Camouflaged object detection (COD) aims to segment objects visually embedded in their surroundings, which is a very challenging task due to the high similarity between the objects and the background. To address it, most methods often incorporate additional information (e.g., boundary, texture, and frequency clues) to guide feature learning for better detecting camouflaged objects from the background. Although progress has been made, these methods are basically individually tailored to specific auxiliary cues, thus lacking adaptability and not consistently achieving high segmentation performance. To this end, this paper proposes an adaptive guidance learning network, dubbed \textit{AGLNet}, which is a unified end-to-end learnable model for exploring and adapting different additional cues in CNN models to guide accurate camouflaged feature learning. Specifically, we first design a straightforward additional information generation (AIG) module to learn additional camouflaged object cues, which can be adapted for the exploration of effective camouflaged features. Then we present a hierarchical feature combination (HFC) module to deeply integrate additional cues and image features to guide camouflaged feature learning in a multi-level fusion manner.Followed by a recalibration decoder (RD), different features are further aggregated and refined for accurate object prediction. Extensive experiments on three widely used COD benchmark datasets demonstrate that the proposed method achieves significant performance improvements under different additional cues, and outperforms the recent 20 state-of-the-art methods by a large margin. Our code will be made publicly available at: \textcolor{blue}{{https://github.com/ZNan-Chen/AGLNet}}.
ZoomNeXt: A Unified Collaborative Pyramid Network for Camouflaged Object Detection
Oct 31, 2023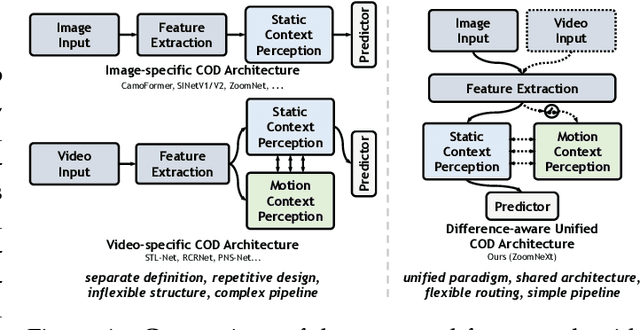

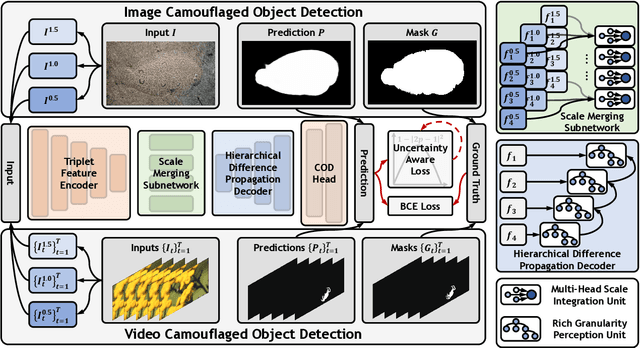

Recent camouflaged object detection (COD) attempts to segment objects visually blended into their surroundings, which is extremely complex and difficult in real-world scenarios. Apart from the high intrinsic similarity between camouflaged objects and their background, objects are usually diverse in scale, fuzzy in appearance, and even severely occluded. To this end, we propose an effective unified collaborative pyramid network which mimics human behavior when observing vague images and videos, \textit{i.e.}, zooming in and out. Specifically, our approach employs the zooming strategy to learn discriminative mixed-scale semantics by the multi-head scale integration and rich granularity perception units, which are designed to fully explore imperceptible clues between candidate objects and background surroundings. The former's intrinsic multi-head aggregation provides more diverse visual patterns. The latter's routing mechanism can effectively propagate inter-frame difference in spatiotemporal scenarios and adaptively ignore static representations. They provides a solid foundation for realizing a unified architecture for static and dynamic COD. Moreover, considering the uncertainty and ambiguity derived from indistinguishable textures, we construct a simple yet effective regularization, uncertainty awareness loss, to encourage predictions with higher confidence in candidate regions. Our highly task-friendly framework consistently outperforms existing state-of-the-art methods in image and video COD benchmarks. The code will be available at \url{https://github.com/lartpang/ZoomNeXt}.
Collaborative Camouflaged Object Detection: A Large-Scale Dataset and Benchmark
Oct 06, 2023
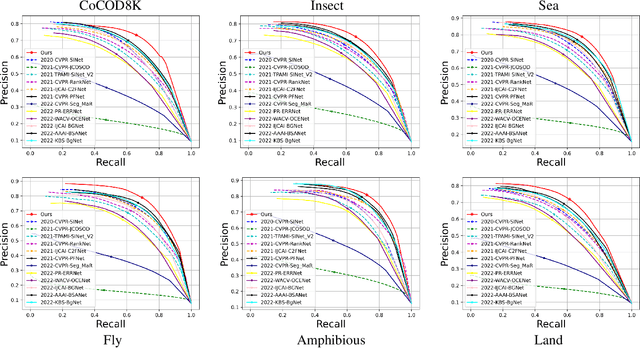

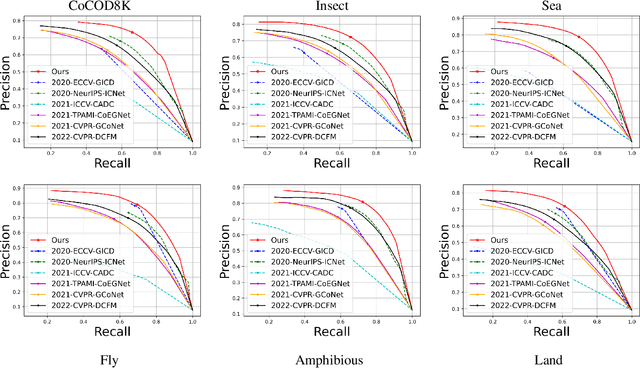
In this paper, we provide a comprehensive study on a new task called collaborative camouflaged object detection (CoCOD), which aims to simultaneously detect camouflaged objects with the same properties from a group of relevant images. To this end, we meticulously construct the first large-scale dataset, termed CoCOD8K, which consists of 8,528 high-quality and elaborately selected images with object mask annotations, covering 5 superclasses and 70 subclasses. The dataset spans a wide range of natural and artificial camouflage scenes with diverse object appearances and backgrounds, making it a very challenging dataset for CoCOD. Besides, we propose the first baseline model for CoCOD, named bilateral-branch network (BBNet), which explores and aggregates co-camouflaged cues within a single image and between images within a group, respectively, for accurate camouflaged object detection in given images. This is implemented by an inter-image collaborative feature exploration (CFE) module, an intra-image object feature search (OFS) module, and a local-global refinement (LGR) module. We benchmark 18 state-of-the-art models, including 12 COD algorithms and 6 CoSOD algorithms, on the proposed CoCOD8K dataset under 5 widely used evaluation metrics. Extensive experiments demonstrate the effectiveness of the proposed method and the significantly superior performance compared to other competitors. We hope that our proposed dataset and model will boost growth in the COD community. The dataset, model, and results will be available at: https://github.com/zc199823/BBNet--CoCOD.
A Unified Query-based Paradigm for Camouflaged Instance Segmentation
Aug 29, 2023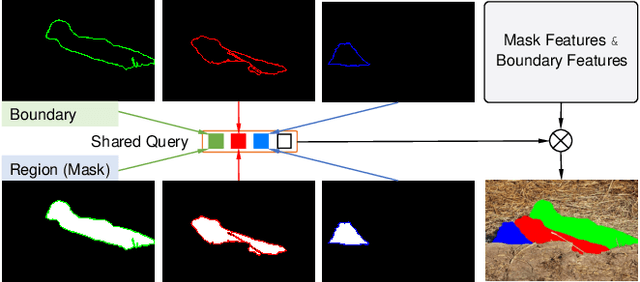
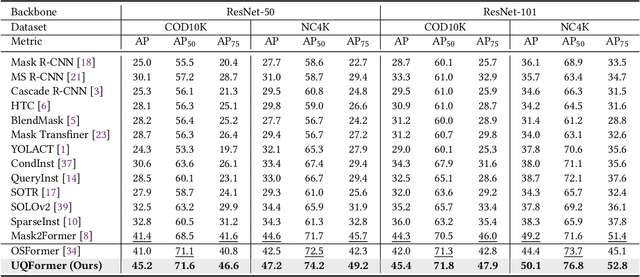
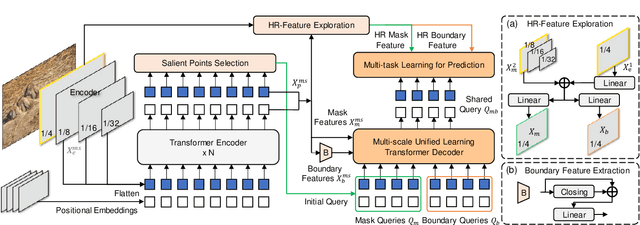

Due to the high similarity between camouflaged instances and the background, the recently proposed camouflaged instance segmentation (CIS) faces challenges in accurate localization and instance segmentation. To this end, inspired by query-based transformers, we propose a unified query-based multi-task learning framework for camouflaged instance segmentation, termed UQFormer, which builds a set of mask queries and a set of boundary queries to learn a shared composed query representation and efficiently integrates global camouflaged object region and boundary cues, for simultaneous instance segmentation and instance boundary detection in camouflaged scenarios. Specifically, we design a composed query learning paradigm that learns a shared representation to capture object region and boundary features by the cross-attention interaction of mask queries and boundary queries in the designed multi-scale unified learning transformer decoder. Then, we present a transformer-based multi-task learning framework for simultaneous camouflaged instance segmentation and camouflaged instance boundary detection based on the learned composed query representation, which also forces the model to learn a strong instance-level query representation. Notably, our model views the instance segmentation as a query-based direct set prediction problem, without other post-processing such as non-maximal suppression. Compared with 14 state-of-the-art approaches, our UQFormer significantly improves the performance of camouflaged instance segmentation. Our code will be available at https://github.com/dongbo811/UQFormer.
Diffusion Model for Camouflaged Object Detection
Aug 05, 2023



Camouflaged object detection is a challenging task that aims to identify objects that are highly similar to their background. Due to the powerful noise-to-image denoising capability of denoising diffusion models, in this paper, we propose a diffusion-based framework for camouflaged object detection, termed diffCOD, a new framework that considers the camouflaged object segmentation task as a denoising diffusion process from noisy masks to object masks. Specifically, the object mask diffuses from the ground-truth masks to a random distribution, and the designed model learns to reverse this noising process. To strengthen the denoising learning, the input image prior is encoded and integrated into the denoising diffusion model to guide the diffusion process. Furthermore, we design an injection attention module (IAM) to interact conditional semantic features extracted from the image with the diffusion noise embedding via the cross-attention mechanism to enhance denoising learning. Extensive experiments on four widely used COD benchmark datasets demonstrate that the proposed method achieves favorable performance compared to the existing 11 state-of-the-art methods, especially in the detailed texture segmentation of camouflaged objects. Our code will be made publicly available at: https://github.com/ZNan-Chen/diffCOD.
Feature Shrinkage Pyramid for Camouflaged Object Detection with Transformers
Mar 26, 2023



Vision transformers have recently shown strong global context modeling capabilities in camouflaged object detection. However, they suffer from two major limitations: less effective locality modeling and insufficient feature aggregation in decoders, which are not conducive to camouflaged object detection that explores subtle cues from indistinguishable backgrounds. To address these issues, in this paper, we propose a novel transformer-based Feature Shrinkage Pyramid Network (FSPNet), which aims to hierarchically decode locality-enhanced neighboring transformer features through progressive shrinking for camouflaged object detection. Specifically, we propose a nonlocal token enhancement module (NL-TEM) that employs the non-local mechanism to interact neighboring tokens and explore graph-based high-order relations within tokens to enhance local representations of transformers. Moreover, we design a feature shrinkage decoder (FSD) with adjacent interaction modules (AIM), which progressively aggregates adjacent transformer features through a layer-bylayer shrinkage pyramid to accumulate imperceptible but effective cues as much as possible for object information decoding. Extensive quantitative and qualitative experiments demonstrate that the proposed model significantly outperforms the existing 24 competitors on three challenging COD benchmark datasets under six widely-used evaluation metrics. Our code is publicly available at https://github.com/ZhouHuang23/FSPNet.
Memory-aided Contrastive Consensus Learning for Co-salient Object Detection
Mar 11, 2023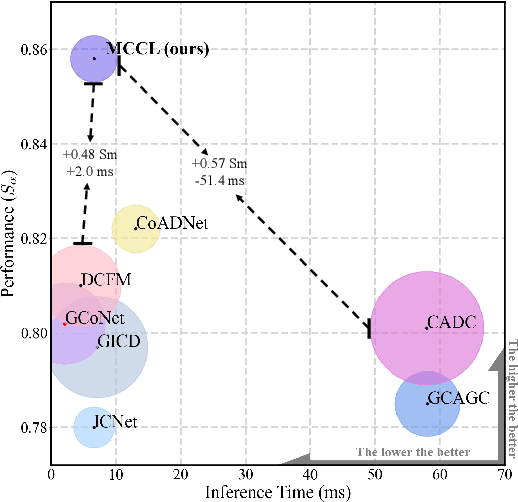
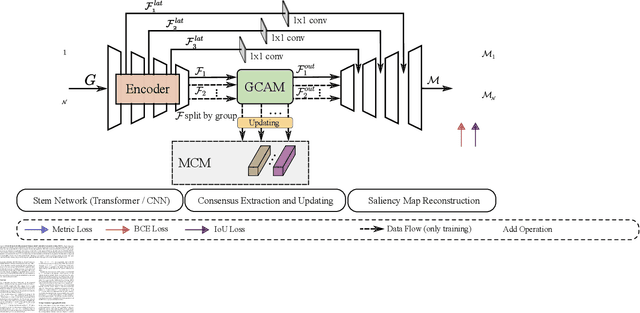

Co-Salient Object Detection (CoSOD) aims at detecting common salient objects within a group of relevant source images. Most of the latest works employ the attention mechanism for finding common objects. To achieve accurate CoSOD results with high-quality maps and high efficiency, we propose a novel Memory-aided Contrastive Consensus Learning (MCCL) framework, which is capable of effectively detecting co-salient objects in real time (~150 fps). To learn better group consensus, we propose the Group Consensus Aggregation Module (GCAM) to abstract the common features of each image group; meanwhile, to make the consensus representation more discriminative, we introduce the Memory-based Contrastive Module (MCM), which saves and updates the consensus of images from different groups in a queue of memories. Finally, to improve the quality and integrity of the predicted maps, we develop an Adversarial Integrity Learning (AIL) strategy to make the segmented regions more likely composed of complete objects with less surrounding noise. Extensive experiments on all the latest CoSOD benchmarks demonstrate that our lite MCCL outperforms 13 cutting-edge models, achieving the new state of the art (~5.9% and ~6.2% improvement in S-measure on CoSOD3k and CoSal2015, respectively). Our source codes, saliency maps, and online demos are publicly available at https://github.com/ZhengPeng7/MCCL.
Trichomonas Vaginalis Segmentation in Microscope Images
Jul 03, 2022

Trichomoniasis is a common infectious disease with high incidence caused by the parasite Trichomonas vaginalis, increasing the risk of getting HIV in humans if left untreated. Automated detection of Trichomonas vaginalis from microscopic images can provide vital information for the diagnosis of trichomoniasis. However, accurate Trichomonas vaginalis segmentation (TVS) is a challenging task due to the high appearance similarity between the Trichomonas and other cells (e.g., leukocyte), the large appearance variation caused by their motility, and, most importantly, the lack of large-scale annotated data for deep model training. To address these challenges, we elaborately collected the first large-scale Microscopic Image dataset of Trichomonas Vaginalis, named TVMI3K, which consists of 3,158 images covering Trichomonas of various appearances in diverse backgrounds, with high-quality annotations including object-level mask labels, object boundaries, and challenging attributes. Besides, we propose a simple yet effective baseline, termed TVNet, to automatically segment Trichomonas from microscopic images, including high-resolution fusion and foreground-background attention modules. Extensive experiments demonstrate that our model achieves superior segmentation performance and outperforms various cutting-edge object detection models both quantitatively and qualitatively, making it a promising framework to promote future research in TVS tasks. The dataset and results will be publicly available at: https://github.com/CellRecog/cellRecog.
* Accepted by MICCAI2022
Boundary-Guided Camouflaged Object Detection
Jul 02, 2022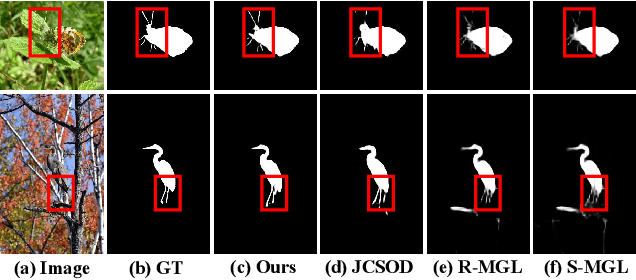
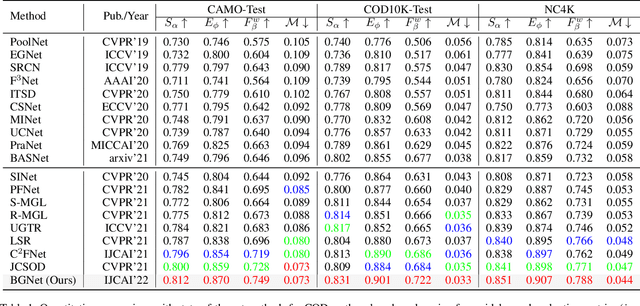
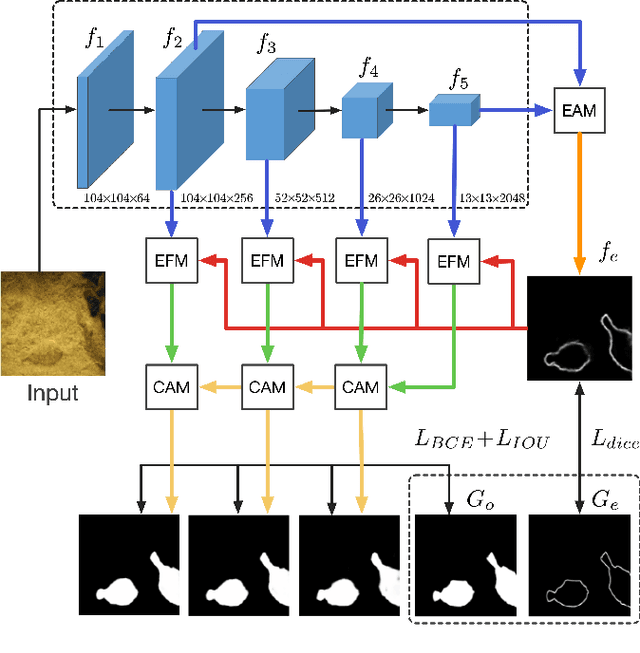

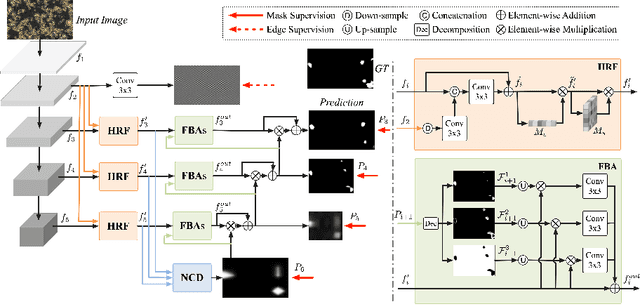
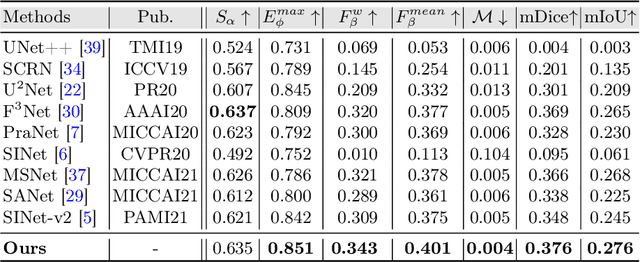
Camouflaged object detection (COD), segmenting objects that are elegantly blended into their surroundings, is a valuable yet challenging task. Existing deep-learning methods often fall into the difficulty of accurately identifying the camouflaged object with complete and fine object structure. To this end, in this paper, we propose a novel boundary-guided network (BGNet) for camouflaged object detection. Our method explores valuable and extra object-related edge semantics to guide representation learning of COD, which forces the model to generate features that highlight object structure, thereby promoting camouflaged object detection of accurate boundary localization. Extensive experiments on three challenging benchmark datasets demonstrate that our BGNet significantly outperforms the existing 18 state-of-the-art methods under four widely-used evaluation metrics. Our code is publicly available at: https://github.com/thograce/BGNet.
* Accepted by IJCAI2022