 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoomNeXt: A Unified Collaborative Pyramid Network for Camouflaged Object Detection
Paper and Code
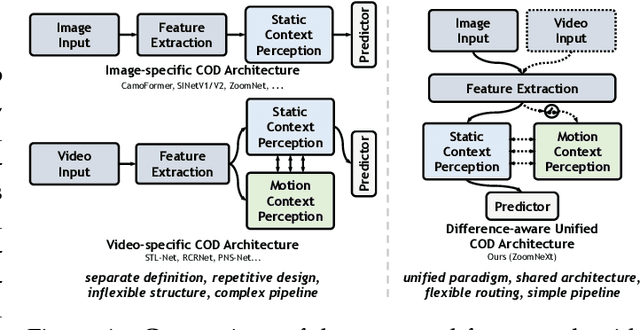

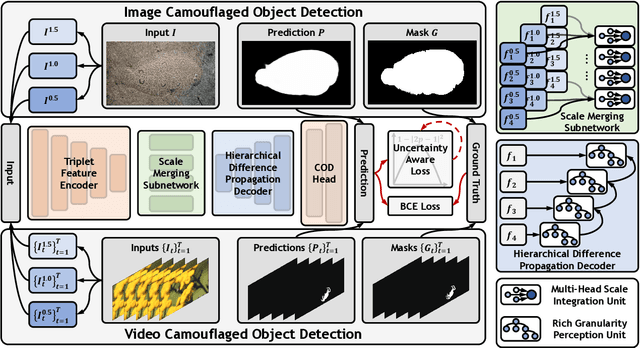

Recent camouflaged object detection (COD) attempts to segment objects visually blended into their surroundings, which is extremely complex and difficult in real-world scenarios. Apart from the high intrinsic similarity between camouflaged objects and their background, objects are usually diverse in scale, fuzzy in appearance, and even severely occluded. To this end, we propose an effective unified collaborative pyramid network which mimics human behavior when observing vague images and videos, \textit{i.e.}, zooming in and out. Specifically, our approach employs the zooming strategy to learn discriminative mixed-scale semantics by the multi-head scale integration and rich granularity perception units, which are designed to fully explore imperceptible clues between candidate objects and background surroundings. The former's intrinsic multi-head aggregation provides more diverse visual patterns. The latter's routing mechanism can effectively propagate inter-frame difference in spatiotemporal scenarios and adaptively ignore static representations. They provides a solid foundation for realizing a unified architecture for static and dynamic COD. Moreover, considering the uncertainty and ambiguity derived from indistinguishable textures, we construct a simple yet effective regularization, uncertainty awareness loss, to encourage predictions with higher confidence in candidate regions. Our highly task-friendly framework consistently outperforms existing state-of-the-art methods in image and video COD benchmarks. The code will be available at \url{https://github.com/lartpang/ZoomNeXt}.