 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel Deep Learning approach for one-step Conformal Prediction approximation
Jul 29, 2022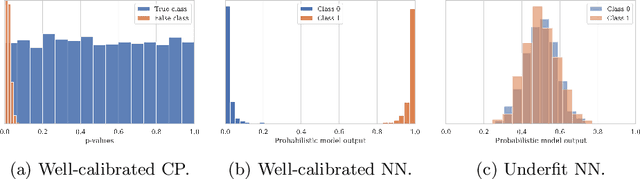


Deep Learning predictions with measurable confidence are increasingly desirable for real-world problems, especially in high-risk settings. The Conformal Prediction (CP) framework is a versatile solution that automatically guarantees a maximum error rate. However, CP suffers from computational inefficiencies that limit its application to large-scale datasets. In this paper, we propose a novel conformal loss function that approximates the traditionally two-step CP approach in a single step. By evaluating and penalising deviations from the stringent expected CP output distribution, a Deep Learning model may learn the direct relationship between input data and conformal p-values. Our approach achieves significant training time reductions up to 86% compared to Aggregated Conformal Prediction (ACP), an accepted CP approximation variant. In terms of approximate validity and predictive efficiency, we carry out a comprehensive empirical evaluation to show our novel loss function's competitiveness with ACP for binary and multi-class classification on the well-established MNIST dataset.
Anomaly Detection in Video Sequences: A Benchmark and Computational Model
Jun 16, 2021


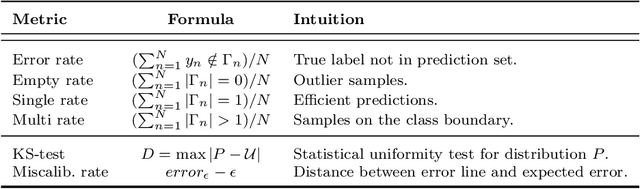
Anomaly detection has attracted considerable search attention. However, existing anomaly detection databases encounter two major problems. Firstly, they are limited in scale. Secondly, training sets contain only video-level labels indicating the existence of an abnormal event during the full video while lacking annotations of precise time durations. To tackle these problems, we contribute a new Large-scale Anomaly Detection (LAD) database as the benchmark for anomaly detection in video sequences, which is featured in two aspects. 1) It contains 2000 video sequences including normal and abnormal video clips with 14 anomaly categories including crash, fire, violence, etc. with large scene varieties, making it the largest anomaly analysis database to date. 2) It provides the annotation data, including video-level labels (abnormal/normal video, anomaly type) and frame-level labels (abnormal/normal video frame) to facilitate anomaly detection. Leveraging the above benefits from the LAD database, we further formulate anomaly detection as a fully-supervised learning problem and propose a multi-task deep neural network to solve it. We first obtain the local spatiotemporal contextual feature by using an Inflated 3D convolutional (I3D) network. Then we construct a recurrent convolutional neural network fed the local spatiotemporal contextual feature to extract the spatiotemporal contextual feature. With the global spatiotemporal contextual feature, the anomaly type and score can be computed simultaneously by a multi-task neural network. Experimental results show that the proposed method outperforms the state-of-the-art anomaly detection methods on our database and other public databases of anomaly detection. Codes are available at https://github.com/wanboyang/anomaly_detection_LAD2000.
Audio feature ranking for sound-based COVID-19 patient detection
Apr 14, 2021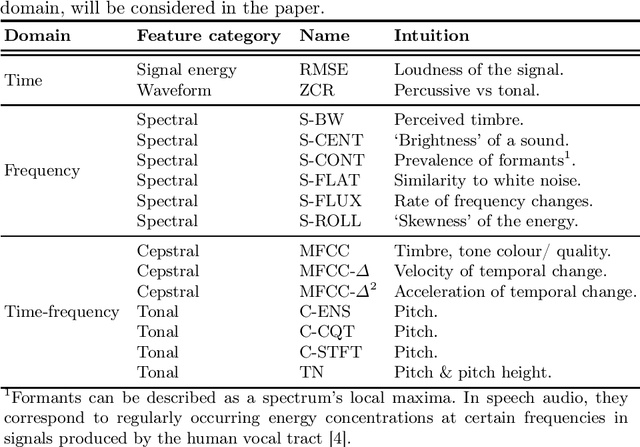
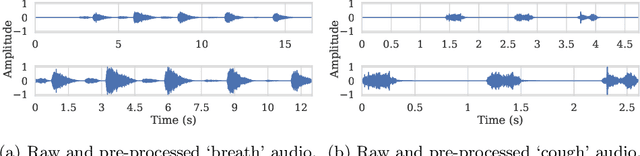
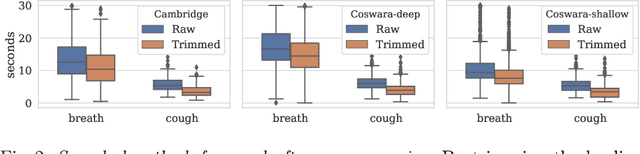
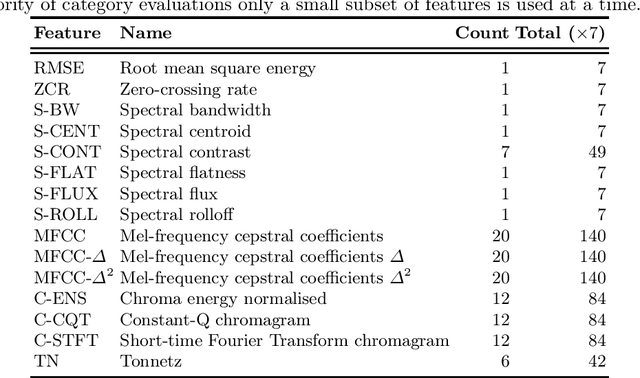
Audio classification using breath and cough samples has recently emerged as a low-cost, non-invasive, and accessible COVID-19 screening method. However, no application has been approved for official use at the time of writing due to the stringent reliability and accuracy requirements of the critical healthcare setting. To support the development of the Machine Learning classification models, we performed an extensive comparative investigation and ranking of 15 audio features, including less well-known ones. The results were verified on two independent COVID-19 sound datasets. By using the identified top-performing features, we have increased the COVID-19 classification accuracy by up to 17% on the Cambridge dataset, and up to 10% on the Coswara dataset, compared to the original baseline accuracy without our feature ranking.
Boost AI Power: Data Augmentation Strategies with unlabelled Data and Conformal Prediction, a Case in Alternative Herbal Medicine Discrimination with Electronic Nose
Feb 05, 2021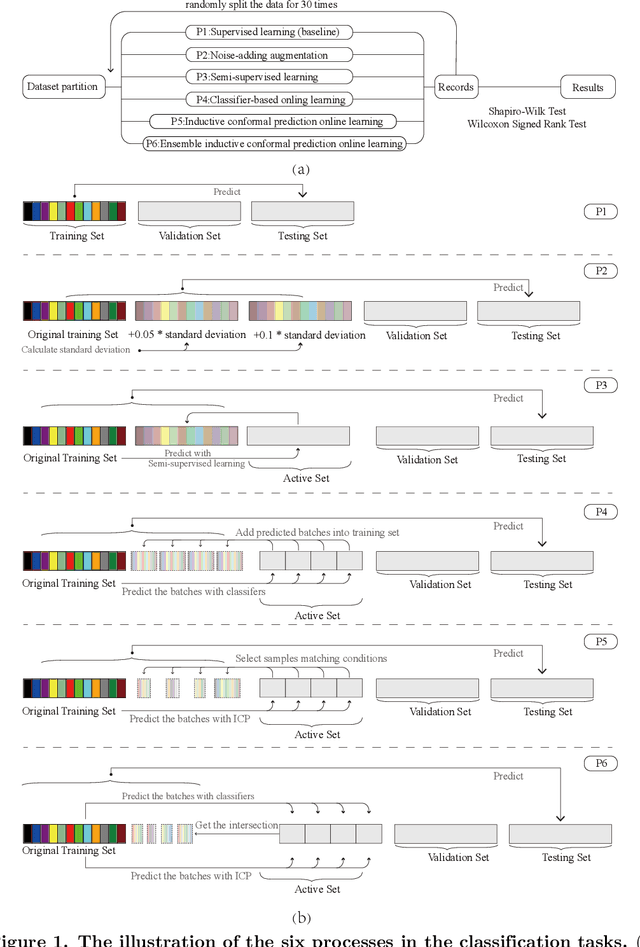
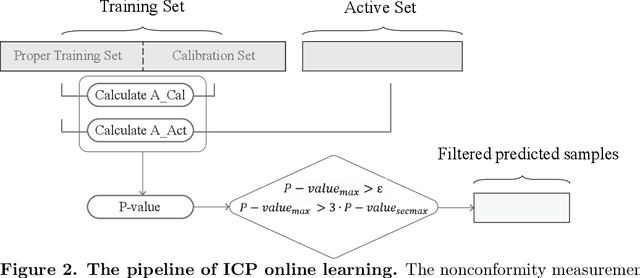
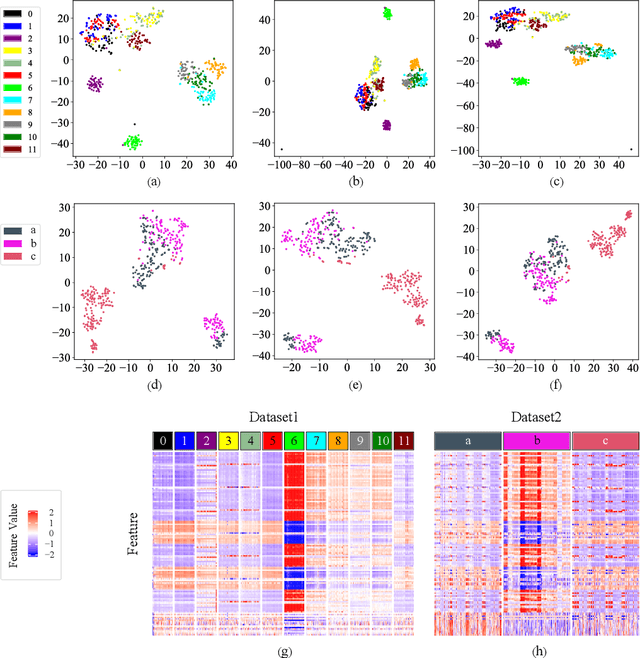
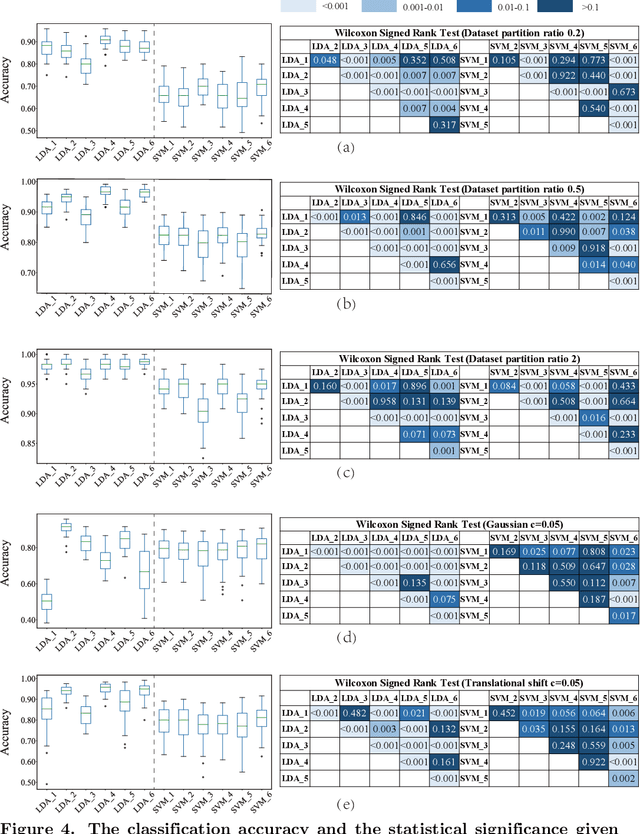
Electronic nose proves its effectiveness in alternativeherbal medicine classification, but due to the supervised learn-ing nature, previous research relies on the labelled training data,which are time-costly and labor-intensive to collect. Consideringthe training data inadequacy in real-world applications, this studyaims to improve classification accuracy via data augmentationstrategies. We stimulated two scenarios to investigate the effective-ness of five data augmentation strategies under different trainingdata inadequacy: in the noise-free scenario, different availability ofunlabelled data were simulated, and in the noisy scenario, differentlevels of Gaussian noises and translational shifts were added tosimulate sensor drifts. The augmentation strategies: noise-addingdata augmentation, semi-supervised learning, classifier-based online learning, inductive conformal prediction (ICP) onlinelearning and the novel ensemble ICP online learning proposed in this study, were compared against supervised learningbaseline, with Linear Discriminant Analysis (LDA) and Support Vector Machine (SVM) as the classifiers. We found thatat least one strategies significantly improved the classification accuracy with LDA(p<=0.05) and showed non-decreasingclassification accuracy with SVM in each tasks. Moreover, our novel strategy: ensemble ICP online learning outperformedthe others by showing non-decreasing classification accuracy on all tasks and significant improvement on most tasks(25/36 tasks,p<=0.05). This study provides a systematic analysis over augmentation strategies, and we provided userswith recommended strategies under specific circumstances. Furthermore, our newly proposed strategy showed botheffectiveness and robustness in boosting the classification model generalizability, which can also be further employed inother machine learning applications.
A review of smartphones based indoor positioning: challenges and applications
Jun 03, 2020
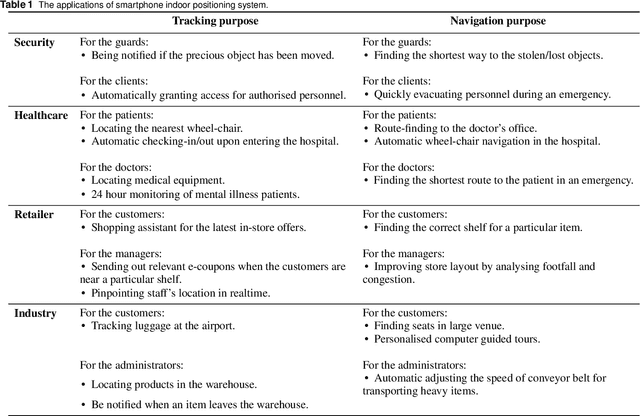
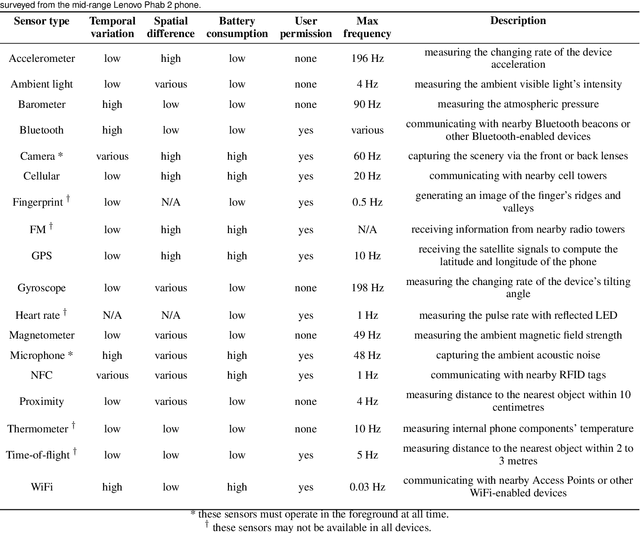
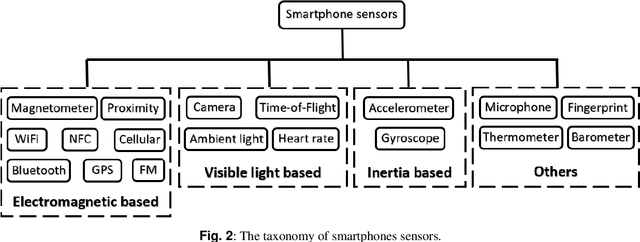
The continual proliferation of mobile devices has encouraged much effort in using the smartphones for indoor positioning. This article is dedicated to review the most recent and interesting smartphones based indoor navigation systems, ranging from electromagnetic to inertia to visible light ones, with an emphasis on their unique challenges and potential real-world applications. A taxonomy of smartphones sensors will be introduced, which serves as the basis to categorise different positioning systems for reviewing. A set of criteria to be used for the evaluation purpose will be devised. For each sensor category, the most recent, interesting and practical systems will be examined, with detailed discussion on the open research questions for the academics, and the practicality for the potential clients.
Recurrent Auto-Encoder Model for Large-Scale Industrial Sensor Signal Analysis
Jul 10, 2018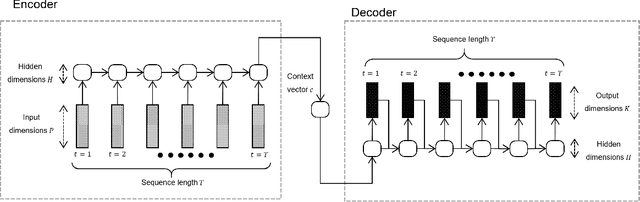
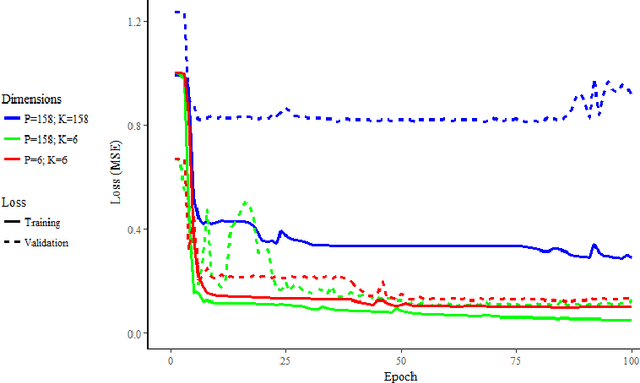
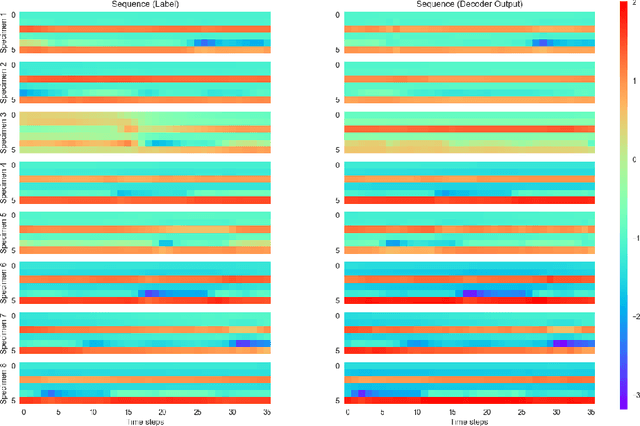
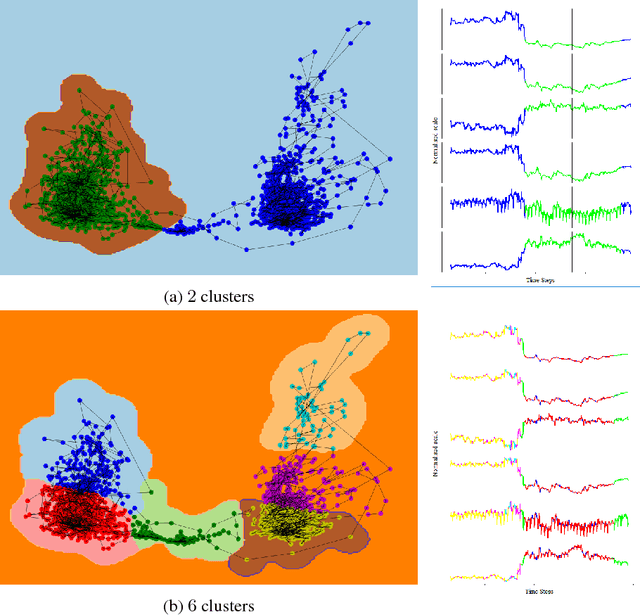
Recurrent auto-encoder model summarises sequential data through an encoder structure into a fixed-length vector and then reconstructs the original sequence through the decoder structure. The summarised vector can be used to represent time series features. In this paper, we propose relaxing the dimensionality of the decoder output so that it performs partial reconstruction. The fixed-length vector therefore represents features in the selected dimensions only. In addition, we propose using rolling fixed window approach to generate training samples from unbounded time series data. The change of time series features over time can be summarised as a smooth trajectory path. The fixed-length vectors are further analysed using additional visualisation and unsupervised clustering techniques. The proposed method can be applied in large-scale industrial processes for sensors signal analysis purpose, where clusters of the vector representations can reflect the operating states of the industrial system.
* Accepted paper at the 19th International Conference on Engineering Applications of Neural Networks (EANN 2018)