 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShades of meaning: Uncovering the geometry of ambiguous word representations through contextualised language models
Apr 26, 2023
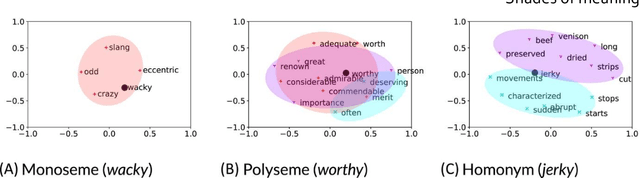
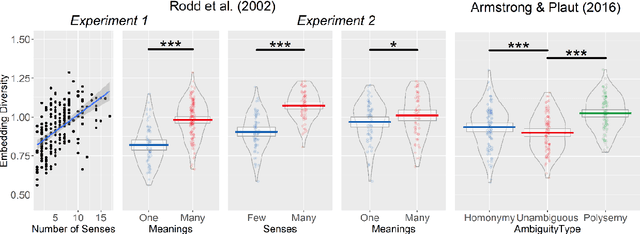
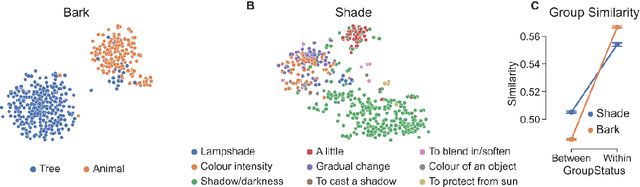
Lexical ambiguity presents a profound and enduring challenge to the language sciences. Researchers for decades have grappled with the problem of how language users learn, represent and process words with more than one meaning. Our work offers new insight into psychological understanding of lexical ambiguity through a series of simulations that capitalise on recent advances in contextual language models. These models have no grounded understanding of the meanings of words at all; they simply learn to predict words based on the surrounding context provided by other words. Yet, our analyses show that their representations capture fine-grained meaningful distinctions between unambiguous, homonymous, and polysemous words that align with lexicographic classifications and psychological theorising. These findings provide quantitative support for modern psychological conceptualisations of lexical ambiguity and raise new challenges for understanding of the way that contextual information shapes the meanings of words across different timescales.
Improving Expert Specialization in Mixture of Experts
Feb 28, 2023



Mixture of experts (MoE), introduced over 20 years ago, is the simplest gated modular neural network architecture. There is renewed interest in MoE because the conditional computation allows only parts of the network to be used during each inference, as was recently demonstrated in large scale natural language processing models. MoE is also of potential interest for continual learning, as experts may be reused for new tasks, and new experts introduced. The gate in the MoE architecture learns task decompositions and individual experts learn simpler functions appropriate to the gate's decomposition. In this paper: (1) we show that the original MoE architecture and its training method do not guarantee intuitive task decompositions and good expert utilization, indeed they can fail spectacularly even for simple data such as MNIST and FashionMNIST; (2) we introduce a novel gating architecture, similar to attention, that improves performance and results in a lower entropy task decomposition; and (3) we introduce a novel data-driven regularization that improves expert specialization. We empirically validate our methods on MNIST, FashionMNIST and CIFAR-100 datasets.
A review of smartphones based indoor positioning: challenges and applications
Jun 03, 2020
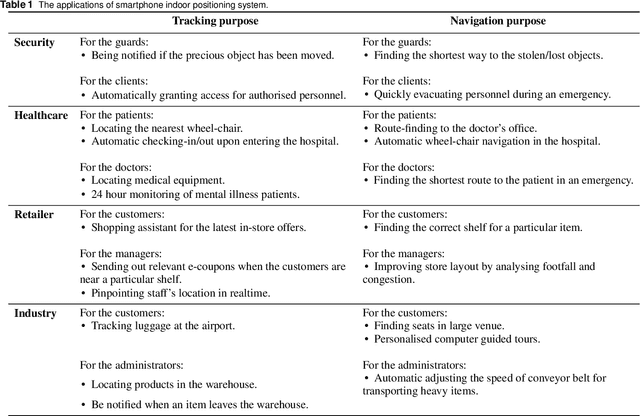
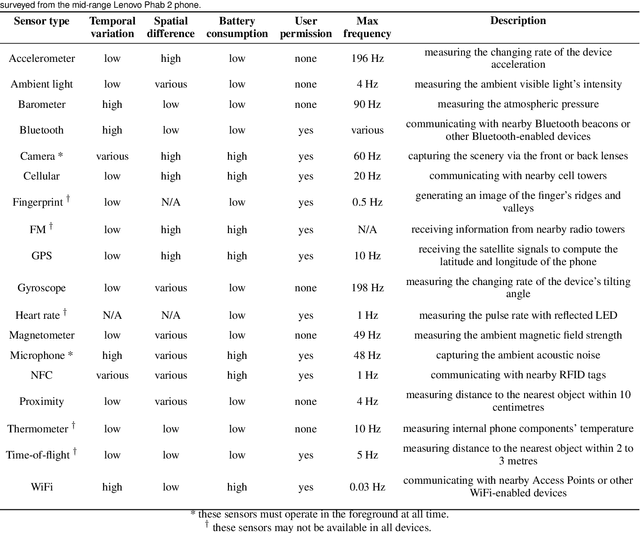
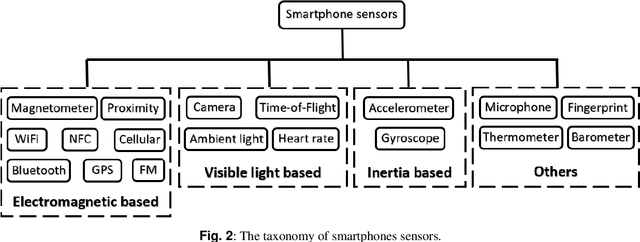
The continual proliferation of mobile devices has encouraged much effort in using the smartphones for indoor positioning. This article is dedicated to review the most recent and interesting smartphones based indoor navigation systems, ranging from electromagnetic to inertia to visible light ones, with an emphasis on their unique challenges and potential real-world applications. A taxonomy of smartphones sensors will be introduced, which serves as the basis to categorise different positioning systems for reviewing. A set of criteria to be used for the evaluation purpose will be devised. For each sensor category, the most recent, interesting and practical systems will be examined, with detailed discussion on the open research questions for the academics, and the practicality for the potential clients.
Anomaly Detection in Video Games
May 20, 2020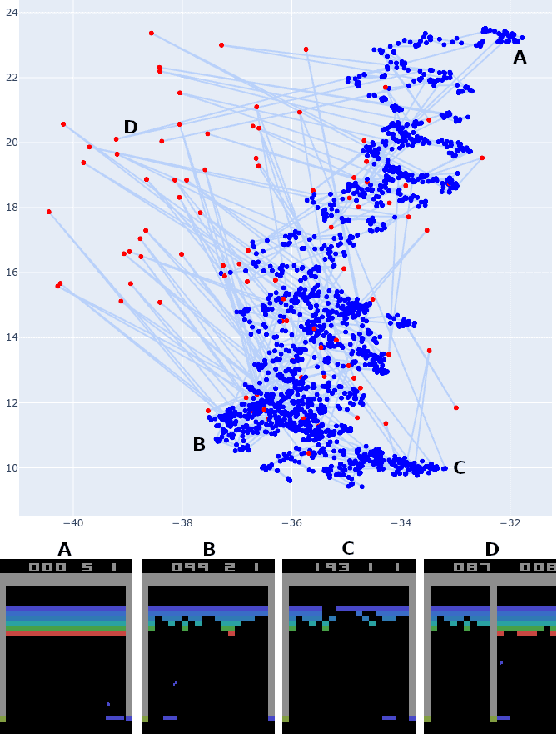
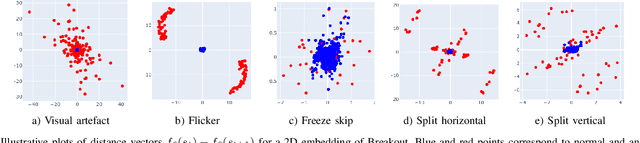
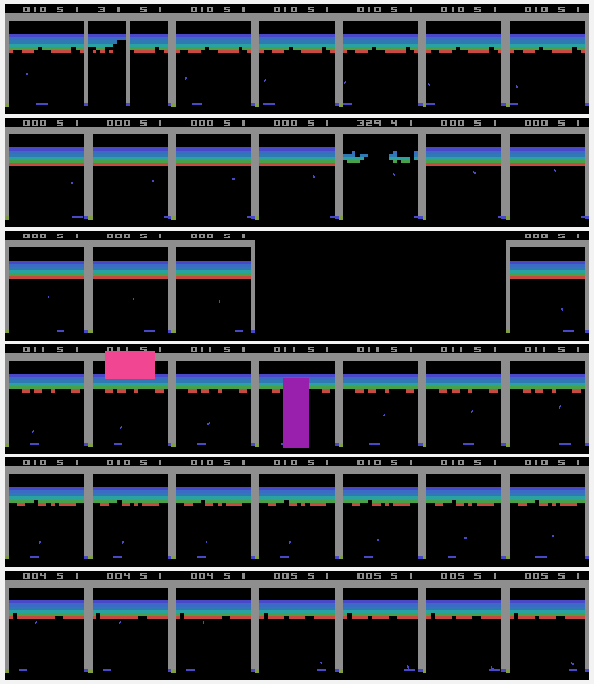

With the aim of designing automated tools that assist in the video game quality assurance process, we frame the problem of identifying bugs in video games as an anomaly detection (AD) problem. We develop State-State Siamese Networks (S3N) as an efficient deep metric learning approach to AD in this context and explore how it may be used as part of an automated testing tool. Finally, we show by empirical evaluation on a series of Atari games, that S3N is able to learn a meaningful embedding, and consequently is able to identify various common types of video game bugs.
Explaining Deep Learning Models with Constrained Adversarial Examples
Jun 25, 2019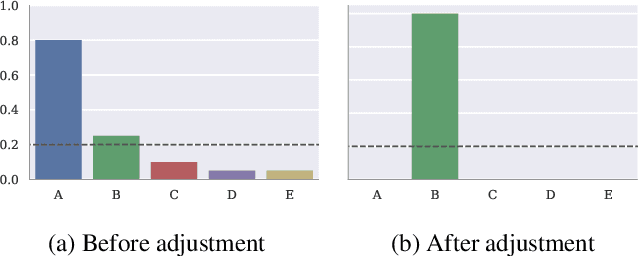
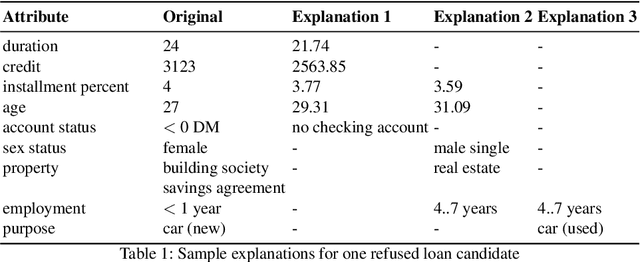
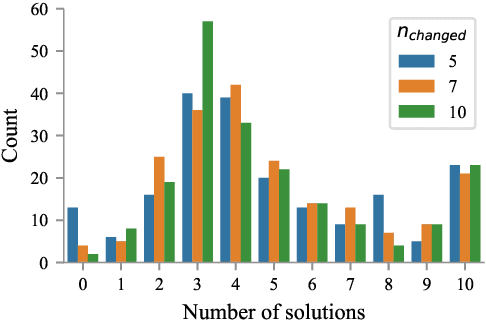
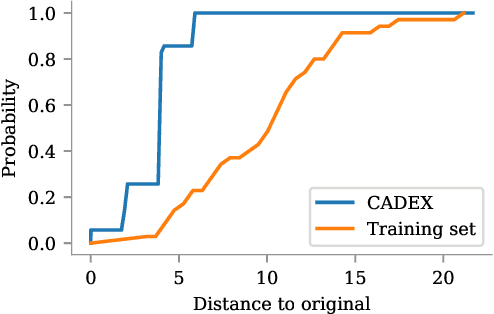
Machine learning algorithms generally suffer from a problem of explainability. Given a classification result from a model, it is typically hard to determine what caused the decision to be made, and to give an informative explanation. We explore a new method of generating counterfactual explanations, which instead of explaining why a particular classification was made explain how a different outcome can be achieved. This gives the recipients of the explanation a better way to understand the outcome, and provides an actionable suggestion. We show that the introduced method of Constrained Adversarial Examples (CADEX) can be used in real world applications, and yields explanations which incorporate business or domain constraints such as handling categorical attributes and range constraints.
An evolutionary model that satisfies detailed balance
Feb 27, 2019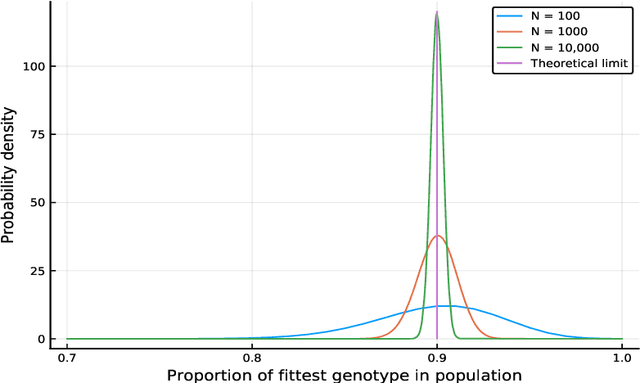
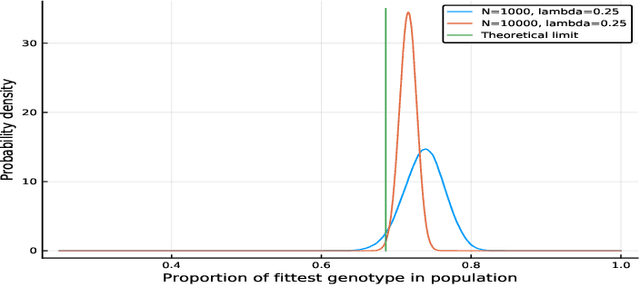
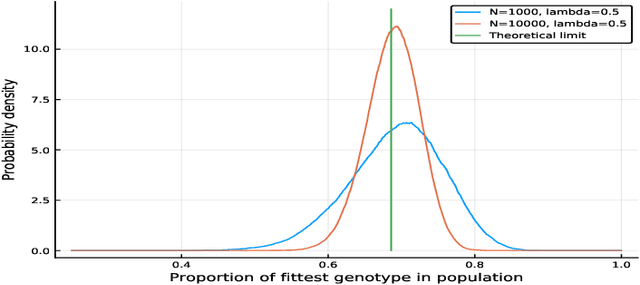
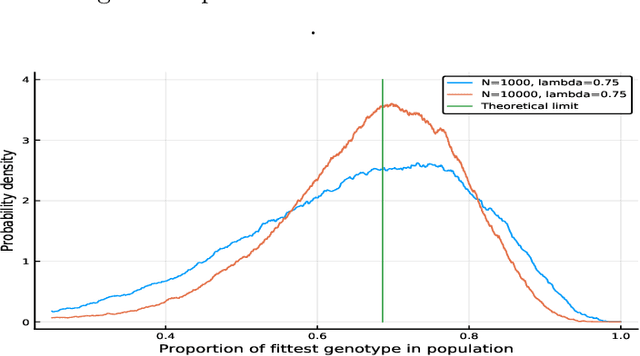
We propose a class of evolutionary models that involves an arbitrary exchangeable process as the breeding process and different selection schemes. In those models, a new genome is born according to the breeding process, and then a genome is removed according to the selection scheme that involves fitness. Thus the population size remains constant. The process evolves according to a Markov chain, and, unlike in many other existing models, the stationary distribution -- so called mutation-selection equilibrium -- can be easily found and studied. The behaviour of the stationary distribution when the population size increases is our main object of interest. Several phase-transition theorems are proved.
Sex as Gibbs Sampling: a probability model of evolution
Feb 12, 2014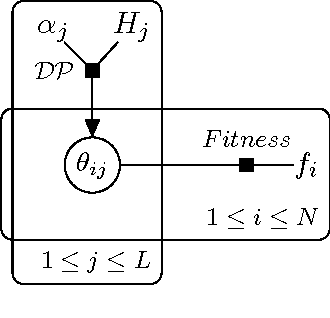
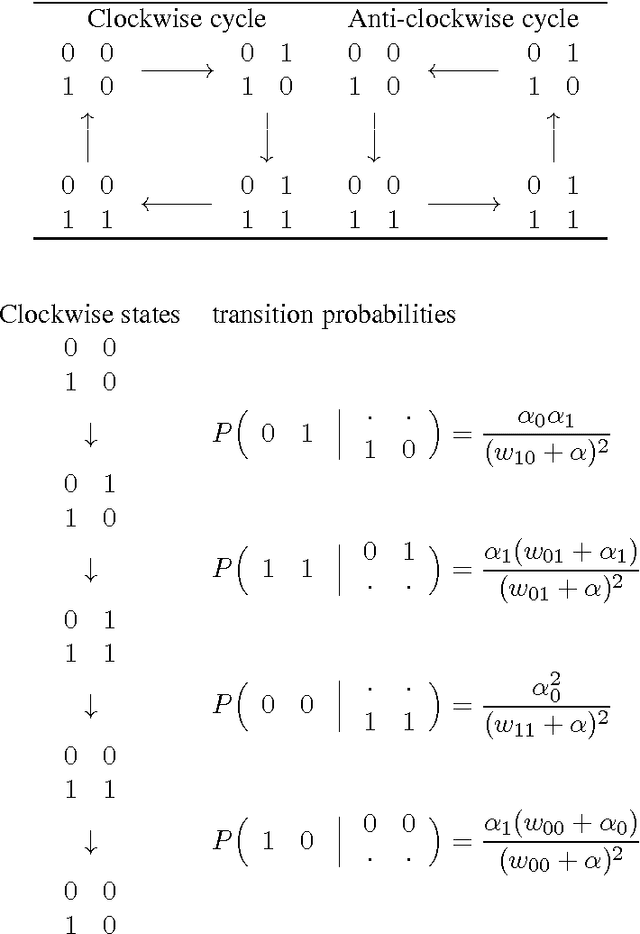

We show that evolutionary computation can be implemented as standard Markov-chain Monte-Carlo (MCMC) sampling. With some care, `genetic algorithms' can be constructed that are reversible Markov chains that satisfy detailed balance; it follows that the stationary distribution of populations is a Gibbs distribution in a simple factorised form. For some standard and popular nonparametric probability models, we exhibit Gibbs-sampling procedures that are plausible genetic algorithms. At mutation-selection equilibrium, a population of genomes is analogous to a sample from a Bayesian posterior, and the genomes are analogous to latent variables. We suggest this is a general, tractable, and insightful formulation of evolutionary computation in terms of standard machine learning concepts and techniques. In addition, we show that evolutionary processes in which selection acts by differences in fecundity are not reversible, and also that it is not possible to construct reversible evolutionary models in which each child is produced by only two parents.