 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis of Speech Self-Supervised Learning at Multiple Resolutions
Oct 31, 2024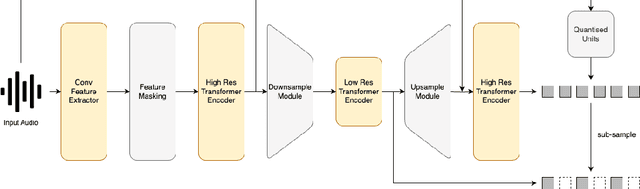
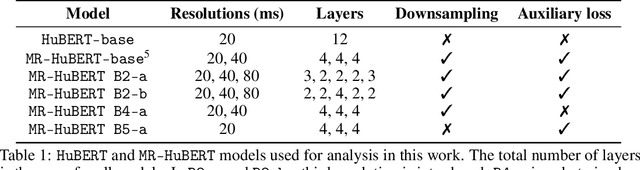
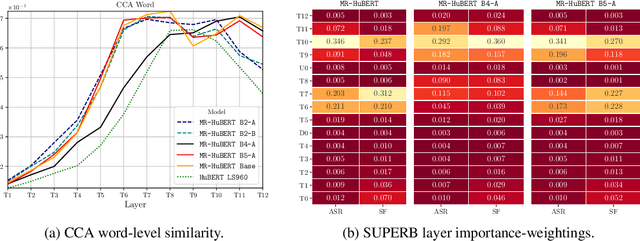

Self-supervised learning (SSL) models have become crucial in speech processing, with recent advancements concentrating on developing architectures that capture representations across multiple timescales. The primary goal of these multi-scale architectures is to exploit the hierarchical nature of speech, where lower-resolution components aim to capture representations that align with increasingly abstract concepts (e.g., from phones to words to sentences). Although multi-scale approaches have demonstrated some improvements over single-scale models, the precise reasons for these enhancements have poor empirical support. In this study, we present an initial analysis of layer-wise representations in multi-scale architectures, with a focus on Canonical Correlation Analysis (CCA) and Mutual Information (MI). We apply this analysis to Multi-Resolution HuBERT (MR-HuBERT) and find that (1) the improved performance on SUPERB tasks is primarily due to the auxiliary low-resolution loss rather than the downsampling itself, and (2) downsampling to lower resolutions neither improves downstream performance nor correlates with higher-level information (e.g., words), though it does improve computational efficiency. These findings challenge assumptions about the multi-scale nature of MR-HuBERT and motivate the importance of disentangling computational efficiency from learning better representations.
Shades of meaning: Uncovering the geometry of ambiguous word representations through contextualised language models
Apr 26, 2023
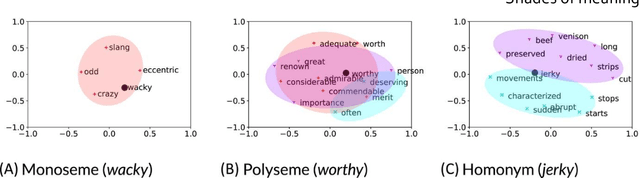
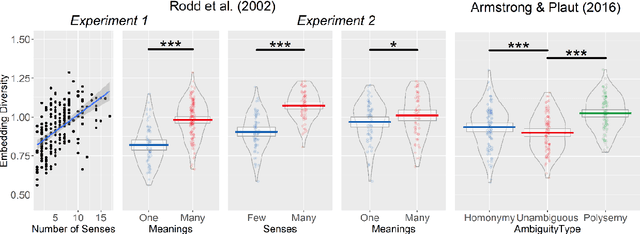
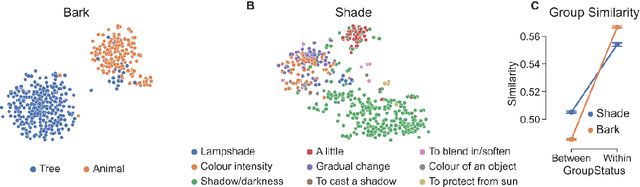
Lexical ambiguity presents a profound and enduring challenge to the language sciences. Researchers for decades have grappled with the problem of how language users learn, represent and process words with more than one meaning. Our work offers new insight into psychological understanding of lexical ambiguity through a series of simulations that capitalise on recent advances in contextual language models. These models have no grounded understanding of the meanings of words at all; they simply learn to predict words based on the surrounding context provided by other words. Yet, our analyses show that their representations capture fine-grained meaningful distinctions between unambiguous, homonymous, and polysemous words that align with lexicographic classifications and psychological theorising. These findings provide quantitative support for modern psychological conceptualisations of lexical ambiguity and raise new challenges for understanding of the way that contextual information shapes the meanings of words across different timescales.