 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Expert Specialization in Mixture of Experts
Feb 28, 2023



Mixture of experts (MoE), introduced over 20 years ago, is the simplest gated modular neural network architecture. There is renewed interest in MoE because the conditional computation allows only parts of the network to be used during each inference, as was recently demonstrated in large scale natural language processing models. MoE is also of potential interest for continual learning, as experts may be reused for new tasks, and new experts introduced. The gate in the MoE architecture learns task decompositions and individual experts learn simpler functions appropriate to the gate's decomposition. In this paper: (1) we show that the original MoE architecture and its training method do not guarantee intuitive task decompositions and good expert utilization, indeed they can fail spectacularly even for simple data such as MNIST and FashionMNIST; (2) we introduce a novel gating architecture, similar to attention, that improves performance and results in a lower entropy task decomposition; and (3) we introduce a novel data-driven regularization that improves expert specialization. We empirically validate our methods on MNIST, FashionMNIST and CIFAR-100 datasets.
3D Self-Supervised Methods for Medical Imaging
Jun 06, 2020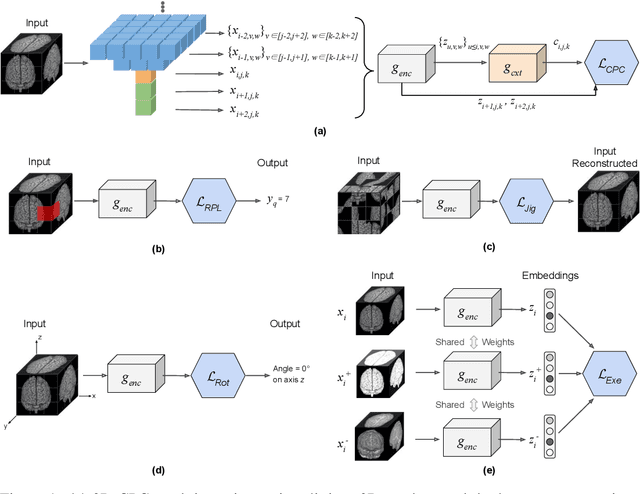
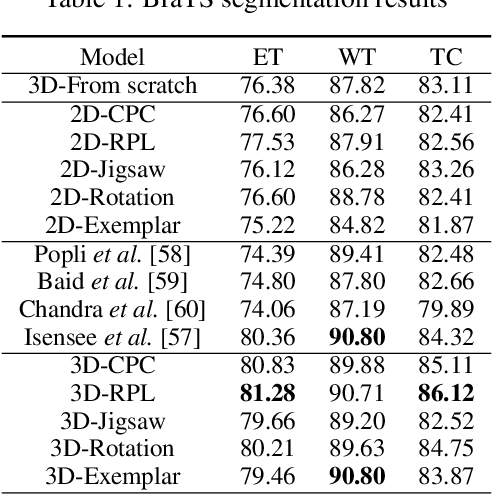
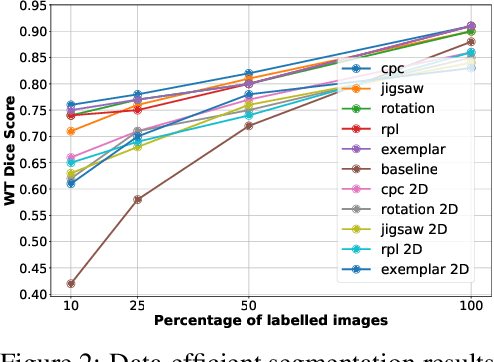

Self-supervised learning methods have witnessed a recent surge of interest after proving successful in multiple application fields. In this work, we leverage these techniques, and we propose 3D versions for five different self-supervised methods, in the form of proxy tasks. Our methods facilitate neural network feature learning from unlabeled 3D images, aiming to reduce the required cost for expert annotation. The developed algorithms are 3D Contrastive Predictive Coding, 3D Rotation prediction, 3D Jigsaw puzzles, Relative 3D patch location, and 3D Exemplar networks. Our experiments show that pretraining models with our 3D tasks yields more powerful semantic representations, and enables solving downstream tasks more accurately and efficiently, compared to training the models from scratch and to pretraining them on 2D slices. We demonstrate the effectiveness of our methods on three downstream tasks from the medical imaging domain: i) Brain Tumor Segmentation from 3D MRI, ii) Pancreas Tumor Segmentation from 3D CT, and iii) Diabetic Retinopathy Detection from 2D Fundus images. In each task, we assess the gains in data-efficiency, performance, and speed of convergence. We achieve results competitive to state-of-the-art solutions at a fraction of the computational expense. We also publish the implementations for the 3D and 2D versions of our algorithms as an open-source library, in an effort to allow other researchers to apply and extend our methods on their datasets.