 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformalised data synthesis with statistical quality guarantees
Dec 14, 2023With the proliferation of ever more complicated Deep Learning architectures, data synthesis is a highly promising technique to address the demand of data-hungry models. However, reliably assessing the quality of a 'synthesiser' model's output is an open research question with significant associated risks for high-stake domains. To address this challenge, we have designed a unique confident data synthesis algorithm that introduces statistical confidence guarantees through a novel extension of the Conformal Prediction framework. We support our proposed algorithm with theoretical proofs and an extensive empirical evaluation of five benchmark datasets. To show our approach's versatility on ubiquitous real-world challenges, the datasets were carefully selected for their variety of difficult characteristics: low sample count, class imbalance and non-separability, and privacy-sensitive data. In all trials, training sets extended with our confident synthesised data performed at least as well as the original, and frequently significantly improved Deep Learning performance by up to +65% F1-score.
A novel Deep Learning approach for one-step Conformal Prediction approximation
Jul 29, 2022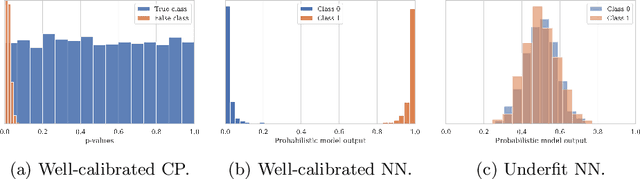


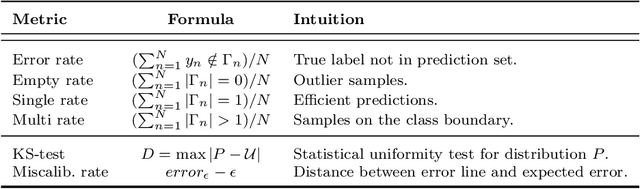
Deep Learning predictions with measurable confidence are increasingly desirable for real-world problems, especially in high-risk settings. The Conformal Prediction (CP) framework is a versatile solution that automatically guarantees a maximum error rate. However, CP suffers from computational inefficiencies that limit its application to large-scale datasets. In this paper, we propose a novel conformal loss function that approximates the traditionally two-step CP approach in a single step. By evaluating and penalising deviations from the stringent expected CP output distribution, a Deep Learning model may learn the direct relationship between input data and conformal p-values. Our approach achieves significant training time reductions up to 86% compared to Aggregated Conformal Prediction (ACP), an accepted CP approximation variant. In terms of approximate validity and predictive efficiency, we carry out a comprehensive empirical evaluation to show our novel loss function's competitiveness with ACP for binary and multi-class classification on the well-established MNIST dataset.
Audio feature ranking for sound-based COVID-19 patient detection
Apr 14, 2021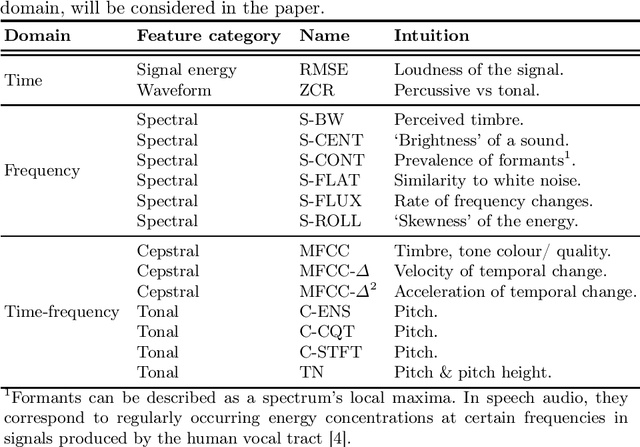
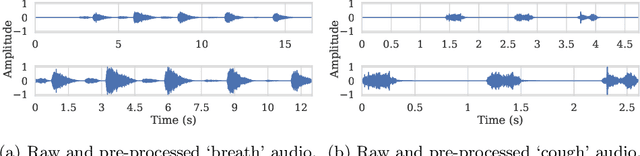
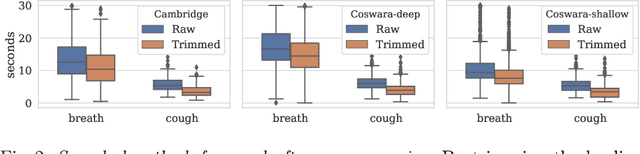
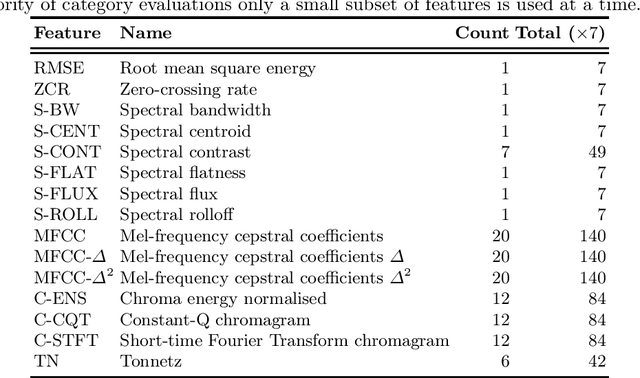
Audio classification using breath and cough samples has recently emerged as a low-cost, non-invasive, and accessible COVID-19 screening method. However, no application has been approved for official use at the time of writing due to the stringent reliability and accuracy requirements of the critical healthcare setting. To support the development of the Machine Learning classification models, we performed an extensive comparative investigation and ranking of 15 audio features, including less well-known ones. The results were verified on two independent COVID-19 sound datasets. By using the identified top-performing features, we have increased the COVID-19 classification accuracy by up to 17% on the Cambridge dataset, and up to 10% on the Coswara dataset, compared to the original baseline accuracy without our feature ranking.
Deep Learning Application in Security and Privacy -- Theory and Practice: A Position Paper
Dec 01, 2018Technology is shaping our lives in a multitude of ways. This is fuelled by a technology infrastructure, both legacy and state of the art, composed of a heterogeneous group of hardware, software, services and organisations. Such infrastructure faces a diverse range of challenges to its operations that include security, privacy, resilience, and quality of services. Among these, cybersecurity and privacy are taking the centre-stage, especially since the General Data Protection Regulation (GDPR) came into effect. Traditional security and privacy techniques are overstretched and adversarial actors have evolved to design exploitation techniques that circumvent protection. With the ever-increasing complexity of technology infrastructure, security and privacy-preservation specialists have started to look for adaptable and flexible protection methods that can evolve (potentially autonomously) as the adversarial actor changes its techniques. For this, Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL) were put forward as saviours. In this paper, we look at the promises of AI, ML, and DL stated in academic and industrial literature and evaluate how realistic they are. We also put forward potential challenges a DL based security and privacy protection technique has to overcome. Finally, we conclude the paper with a discussion on what steps the DL and the security and privacy-preservation community have to take to ensure that DL is not just going to be hype, but an opportunity to build a secure, reliable, and trusted technology infrastructure on which we can rely on for so much in our lives.