 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Anything for Video: A Comprehensive Review of Video Object Segmentation and Tracking from Past to Future
Jul 30, 2025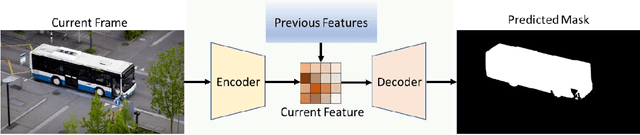
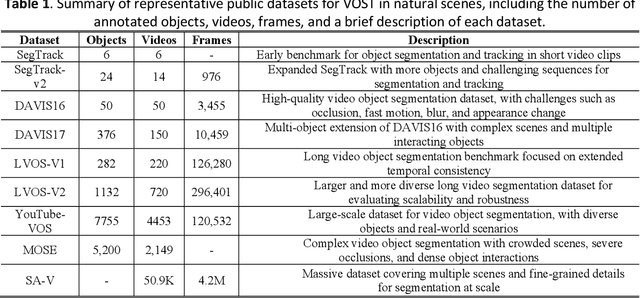
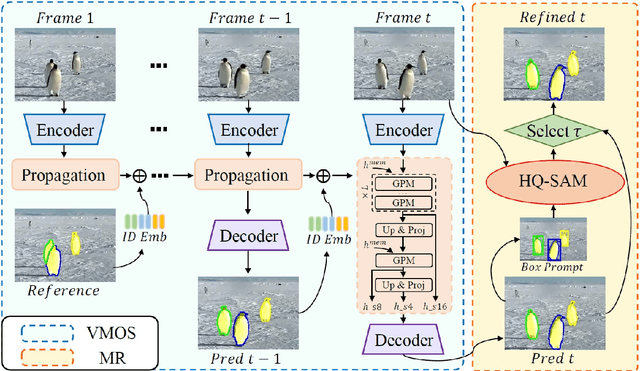
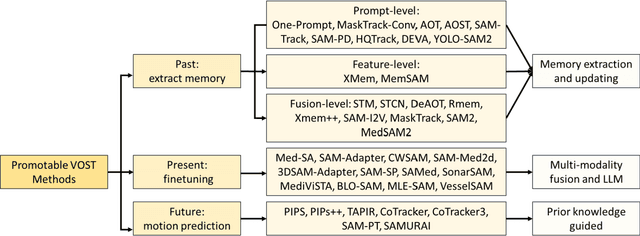
Video Object Segmentation and Tracking (VOST) presents a complex yet critical challenge in computer vision, requiring robust integration of segmentation and tracking across temporally dynamic frames. Traditional methods have struggled with domain generalization, temporal consistency, and computational efficiency. The emergence of foundation models like the Segment Anything Model (SAM) and its successor, SAM2, has introduced a paradigm shift, enabling prompt-driven segmentation with strong generalization capabilities. Building upon these advances, this survey provides a comprehensive review of SAM/SAM2-based methods for VOST, structured along three temporal dimensions: past, present, and future. We examine strategies for retaining and updating historical information (past), approaches for extracting and optimizing discriminative features from the current frame (present), and motion prediction and trajectory estimation mechanisms for anticipating object dynamics in subsequent frames (future). In doing so, we highlight the evolution from early memory-based architectures to the streaming memory and real-time segmentation capabilities of SAM2. We also discuss recent innovations such as motion-aware memory selection and trajectory-guided prompting, which aim to enhance both accuracy and efficiency. Finally, we identify remaining challenges including memory redundancy, error accumulation, and prompt inefficiency, and suggest promising directions for future research. This survey offers a timely and structured overview of the field, aiming to guide researchers and practitioners in advancing the state of VOST through the lens of foundation models.
Time-resolved dynamic CBCT reconstruction using prior-model-free spatiotemporal Gaussian representation (PMF-STGR)
Mar 28, 2025Time-resolved CBCT imaging, which reconstructs a dynamic sequence of CBCTs reflecting intra-scan motion (one CBCT per x-ray projection without phase sorting or binning), is highly desired for regular and irregular motion characterization, patient setup, and motion-adapted radiotherapy. Representing patient anatomy and associated motion fields as 3D Gaussians, we developed a Gaussian representation-based framework (PMF-STGR) for fast and accurate dynamic CBCT reconstruction. PMF-STGR comprises three major components: a dense set of 3D Gaussians to reconstruct a reference-frame CBCT for the dynamic sequence; another 3D Gaussian set to capture three-level, coarse-to-fine motion-basis-components (MBCs) to model the intra-scan motion; and a CNN-based motion encoder to solve projection-specific temporal coefficients for the MBCs. Scaled by the temporal coefficients, the learned MBCs will combine into deformation vector fields to deform the reference CBCT into projection-specific, time-resolved CBCTs to capture the dynamic motion. Due to the strong representation power of 3D Gaussians, PMF-STGR can reconstruct dynamic CBCTs in a 'one-shot' training fashion from a standard 3D CBCT scan, without using any prior anatomical or motion model. We evaluated PMF-STGR using XCAT phantom simulations and real patient scans. Metrics including the image relative error, structural-similarity-index-measure, tumor center-of-mass-error, and landmark localization error were used to evaluate the accuracy of solved dynamic CBCTs and motion. PMF-STGR shows clear advantages over a state-of-the-art, INR-based approach, PMF-STINR. Compared with PMF-STINR, PMF-STGR reduces reconstruction time by 50% while reconstructing less blurred images with better motion accuracy. With improved efficiency and accuracy, PMF-STGR enhances the applicability of dynamic CBCT imaging for potential clinical translation.
Prior Frequency Guided Diffusion Model for Limited Angle (LA)-CBCT Reconstruction
Apr 09, 2024Cone-beam computed tomography (CBCT) is widely used in image-guided radiotherapy. Reconstructing CBCTs from limited-angle acquisitions (LA-CBCT) is highly desired for improved imaging efficiency, dose reduction, and better mechanical clearance. LA-CBCT reconstruction, however, suffers from severe under-sampling artifacts, making it a highly ill-posed inverse problem. Diffusion models can generate data/images by reversing a data-noising process through learned data distributions; and can be incorporated as a denoiser/regularizer in LA-CBCT reconstruction. In this study, we developed a diffusion model-based framework, prior frequency-guided diffusion model (PFGDM), for robust and structure-preserving LA-CBCT reconstruction. PFGDM uses a conditioned diffusion model as a regularizer for LA-CBCT reconstruction, and the condition is based on high-frequency information extracted from patient-specific prior CT scans which provides a strong anatomical prior for LA-CBCT reconstruction. Specifically, we developed two variants of PFGDM (PFGDM-A and PFGDM-B) with different conditioning schemes. PFGDM-A applies the high-frequency CT information condition until a pre-optimized iteration step, and drops it afterwards to enable both similar and differing CT/CBCT anatomies to be reconstructed. PFGDM-B, on the other hand, continuously applies the prior CT information condition in every reconstruction step, while with a decaying mechanism, to gradually phase out the reconstruction guidance from the prior CT scans. The two variants of PFGDM were tested and compared with current available LA-CBCT reconstruction solutions, via metrics including PSNR and SSIM. PFGDM outperformed all traditional and diffusion model-based methods. PFGDM reconstructs high-quality LA-CBCTs under very-limited gantry angles, allowing faster and more flexible CBCT scans with dose reductions.
FDDM: Unsupervised Medical Image Translation with a Frequency-Decoupled Diffusion Model
Nov 19, 2023



Diffusion models have demonstrated significant potential in producing high-quality images for medical image translation to aid disease diagnosis, localization, and treatment. Nevertheless, current diffusion models have limited success in achieving faithful image translations that can accurately preserve the anatomical structures of medical images, especially for unpaired datasets. The preservation of structural and anatomical details is essential to reliable medical diagnosis and treatment planning, as structural mismatches can lead to disease misidentification and treatment errors. In this study, we introduced a frequency-decoupled diffusion model (FDDM), a novel framework that decouples the frequency components of medical images in the Fourier domain during the translation process, to allow structure-preserved high-quality image conversion. FDDM applies an unsupervised frequency conversion module to translate the source medical images into frequency-specific outputs and then uses the frequency-specific information to guide a following diffusion model for final source-to-target image translation. We conducted extensive evaluations of FDDM using a public brain MR-to-CT translation dataset, showing its superior performance against other GAN-, VAE-, and diffusion-based models. Metrics including the Frechet inception distance (FID), the peak signal-to-noise ratio (PSNR), and the structural similarity index measure (SSIM) were assessed. FDDM achieves an FID of 29.88, less than half of the second best. These results demonstrated FDDM's prowess in generating highly-realistic target-domain images while maintaining the faithfulness of translated anatomical structures.
Zero-shot Medical Image Translation via Frequency-Guided Diffusion Models
Apr 05, 2023



Recently, the diffusion model has emerged as a superior generative model that can produce high-quality images with excellent realism. There is a growing interest in applying diffusion models to image translation tasks. However, for medical image translation, the existing diffusion models are deficient in accurately retaining structural information since the structure details of source domain images are lost during the forward diffusion process and cannot be fully recovered through learned reverse diffusion, while the integrity of anatomical structures is extremely important in medical images. Training and conditioning diffusion models using paired source and target images with matching anatomy can help. However, such paired data are very difficult and costly to obtain, and may also reduce the robustness of the developed model to out-of-distribution testing data. We propose a frequency-guided diffusion model (FGDM) that employs frequency-domain filters to guide the diffusion model for structure-preserving image translation. Based on its design, FGDM allows zero-shot learning, as it can be trained solely on the data from the target domain, and used directly for source-to-target domain translation without any exposure to the source-domain data during training. We trained FGDM solely on the head-and-neck CT data, and evaluated it on both head-and-neck and lung cone-beam CT (CBCT)-to-CT translation tasks. FGDM outperformed the state-of-the-art methods (GAN-based, VAE-based, and diffusion-based) in all metrics, showing its significant advantages in zero-shot medical image translation.