 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA SAM-guided and Match-based Semi-Supervised Segmentation Framework for Medical Imaging
Nov 25, 2024
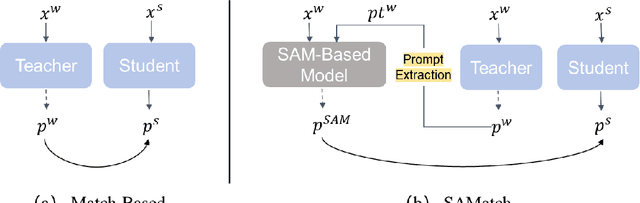
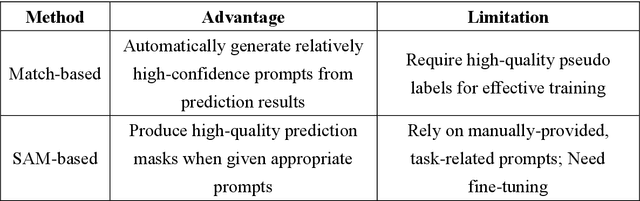
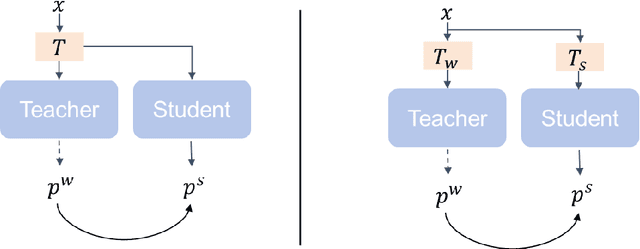
This study introduces SAMatch, a SAM-guided Match-based framework for semi-supervised medical image segmentation, aimed at improving pseudo label quality in data-scarce scenarios. While Match-based frameworks are effective, they struggle with low-quality pseudo labels due to the absence of ground truth. SAM, pre-trained on a large dataset, generalizes well across diverse tasks and assists in generating high-confidence prompts, which are then used to refine pseudo labels via fine-tuned SAM. SAMatch is trained end-to-end, allowing for dynamic interaction between the models. Experiments on the ACDC cardiac MRI, BUSI breast ultrasound, and MRLiver datasets show SAMatch achieving state-of-the-art results, with Dice scores of 89.36%, 77.76%, and 80.04%, respectively, using minimal labeled data. SAMatch effectively addresses challenges in semi-supervised segmentation, offering a powerful tool for segmentation in data-limited environments. Code and data are available at https://github.com/apple1986/SAMatch.
FDDM: Unsupervised Medical Image Translation with a Frequency-Decoupled Diffusion Model
Nov 19, 2023



Diffusion models have demonstrated significant potential in producing high-quality images for medical image translation to aid disease diagnosis, localization, and treatment. Nevertheless, current diffusion models have limited success in achieving faithful image translations that can accurately preserve the anatomical structures of medical images, especially for unpaired datasets. The preservation of structural and anatomical details is essential to reliable medical diagnosis and treatment planning, as structural mismatches can lead to disease misidentification and treatment errors. In this study, we introduced a frequency-decoupled diffusion model (FDDM), a novel framework that decouples the frequency components of medical images in the Fourier domain during the translation process, to allow structure-preserved high-quality image conversion. FDDM applies an unsupervised frequency conversion module to translate the source medical images into frequency-specific outputs and then uses the frequency-specific information to guide a following diffusion model for final source-to-target image translation. We conducted extensive evaluations of FDDM using a public brain MR-to-CT translation dataset, showing its superior performance against other GAN-, VAE-, and diffusion-based models. Metrics including the Frechet inception distance (FID), the peak signal-to-noise ratio (PSNR), and the structural similarity index measure (SSIM) were assessed. FDDM achieves an FID of 29.88, less than half of the second best. These results demonstrated FDDM's prowess in generating highly-realistic target-domain images while maintaining the faithfulness of translated anatomical structures.