 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASAM: Terrain-and-Aware Segment Anything Model for Temporal-Scale Remote Sensing Segmentation
Sep 19, 2025Segment Anything Model (SAM) has demonstrated impressive zero-shot segmentation capabilities across natural image domains, but it struggles to generalize to the unique challenges of remote sensing data, such as complex terrain, multi-scale objects, and temporal dynamics. In this paper, we introduce TASAM, a terrain and temporally-aware extension of SAM designed specifically for high-resolution remote sensing image segmentation. TASAM integrates three lightweight yet effective modules: a terrain-aware adapter that injects elevation priors, a temporal prompt generator that captures land-cover changes over time, and a multi-scale fusion strategy that enhances fine-grained object delineation. Without retraining the SAM backbone, our approach achieves substantial performance gains across three remote sensing benchmarks-LoveDA, iSAID, and WHU-CD-outperforming both zero-shot SAM and task-specific models with minimal computational overhead. Our results highlight the value of domain-adaptive augmentation for foundation models and offer a scalable path toward more robust geospatial segmentation.
Boosting Active Learning with Knowledge Transfer
Sep 19, 2025Uncertainty estimation is at the core of Active Learning (AL). Most existing methods resort to complex auxiliary models and advanced training fashions to estimate uncertainty for unlabeled data. These models need special design and hence are difficult to train especially for domain tasks, such as Cryo-Electron Tomography (cryo-ET) classification in computational biology. To address this challenge, we propose a novel method using knowledge transfer to boost uncertainty estimation in AL. Specifically, we exploit the teacher-student mode where the teacher is the task model in AL and the student is an auxiliary model that learns from the teacher. We train the two models simultaneously in each AL cycle and adopt a certain distance between the model outputs to measure uncertainty for unlabeled data. The student model is task-agnostic and does not rely on special training fashions (e.g. adversarial), making our method suitable for various tasks. More importantly, we demonstrate that data uncertainty is not tied to concrete value of task loss but closely related to the upper-bound of task loss. We conduct extensive experiments to validate the proposed method on classical computer vision tasks and cryo-ET challenges. The results demonstrate its efficacy and efficiency.
ReviBranch: Deep Reinforcement Learning for Branch-and-Bound with Revived Trajectories
Aug 24, 2025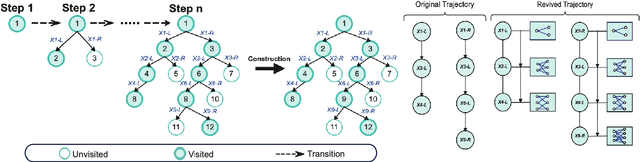
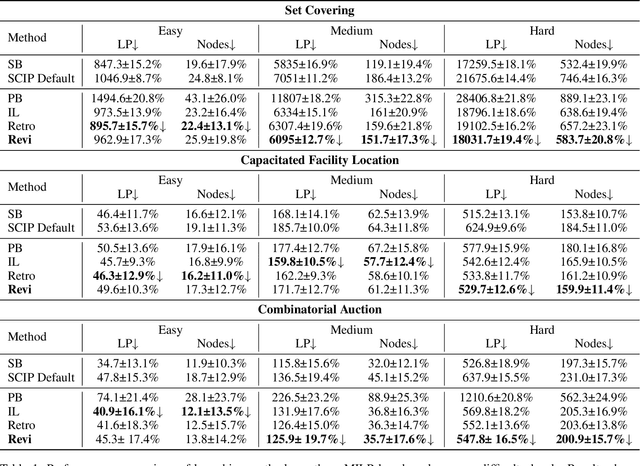
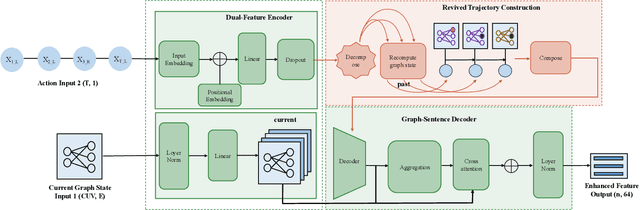
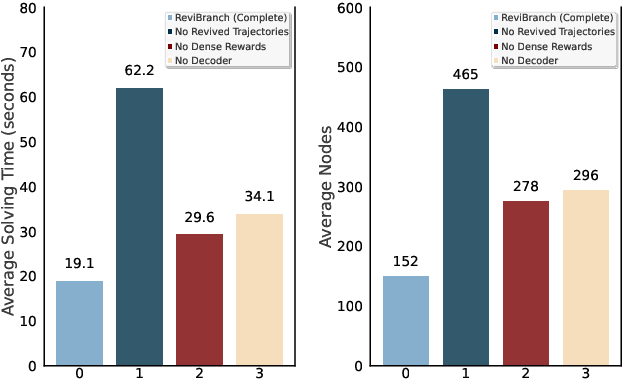
The Branch-and-bound (B&B) algorithm is the main solver for Mixed Integer Linear Programs (MILPs), where the selection of branching variable is essential to computational efficiency. However, traditional heuristics for branching often fail to generalize across heterogeneous problem instances, while existing learning-based methods such as imitation learning (IL) suffers from dependence on expert demonstration quality, and reinforcement learning (RL) struggles with limitations in sparse rewards and dynamic state representation challenges. To address these issues, we propose ReviBranch, a novel deep RL framework that constructs revived trajectories by reviving explicit historical correspondences between branching decisions and their corresponding graph states along search-tree paths. During training, ReviBranch enables agents to learn from complete structural evolution and temporal dependencies within the branching process. Additionally, we introduce an importance-weighted reward redistribution mechanism that transforms sparse terminal rewards into dense stepwise feedback, addressing the sparse reward challenge. Extensive experiments on different MILP benchmarks demonstrate that ReviBranch outperforms state-of-the-art RL methods, reducing B&B nodes by 4.0% and LP iterations by 2.2% on large-scale instances. The results highlight the robustness and generalizability of ReviBranch across heterogeneous MILP problem classes.
CIBR: Cross-modal Information Bottleneck Regularization for Robust CLIP Generalization
Mar 31, 2025Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success in cross-modal tasks such as zero-shot image classification and text-image retrieval by effectively aligning visual and textual representations. However, the theoretical foundations underlying CLIP's strong generalization remain unclear. In this work, we address this gap by proposing the Cross-modal Information Bottleneck (CIB) framework. CIB offers a principled interpretation of CLIP's contrastive learning objective as an implicit Information Bottleneck optimization. Under this view, the model maximizes shared cross-modal information while discarding modality-specific redundancies, thereby preserving essential semantic alignment across modalities. Building on this insight, we introduce a Cross-modal Information Bottleneck Regularization (CIBR) method that explicitly enforces these IB principles during training. CIBR introduces a penalty term to discourage modality-specific redundancy, thereby enhancing semantic alignment between image and text features. We validate CIBR on extensive vision-language benchmarks, including zero-shot classification across seven diverse image datasets and text-image retrieval on MSCOCO and Flickr30K. The results show consistent performance gains over standard CLIP. These findings provide the first theoretical understanding of CLIP's generalization through the IB lens. They also demonstrate practical improvements, offering guidance for future cross-modal representation learning.
Deep Active Learning with Manifold-preserving Trajectory Sampling
Oct 21, 2024

Active learning (AL) is for optimizing the selection of unlabeled data for annotation (labeling), aiming to enhance model performance while minimizing labeling effort. The key question in AL is which unlabeled data should be selected for annotation. Existing deep AL methods arguably suffer from bias incurred by clabeled data, which takes a much lower percentage than unlabeled data in AL context. We observe that such an issue is severe in different types of data, such as vision and non-vision data. To address this issue, we propose a novel method, namely Manifold-Preserving Trajectory Sampling (MPTS), aiming to enforce the feature space learned from labeled data to represent a more accurate manifold. By doing so, we expect to effectively correct the bias incurred by labeled data, which can cause a biased selection of unlabeled data. Despite its focus on manifold, the proposed method can be conveniently implemented by performing distribution mapping with MMD (Maximum Mean Discrepancies). Extensive experiments on various vision and non-vision benchmark datasets demonstrate the superiority of our method. Our source code can be found here.
Advancing Out-of-Distribution Detection through Data Purification and Dynamic Activation Function Design
Mar 06, 2024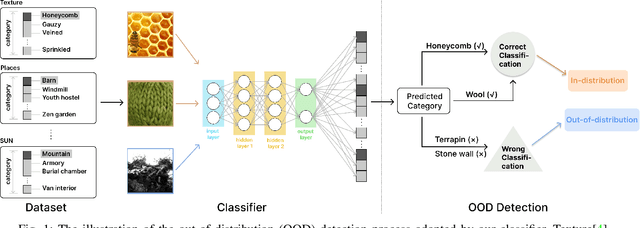
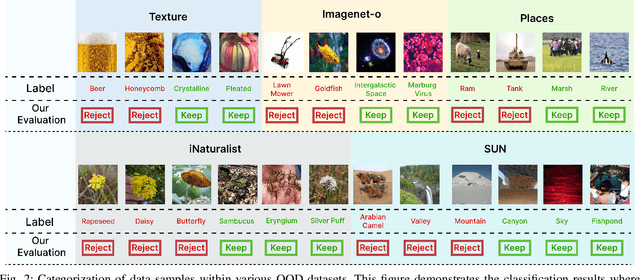
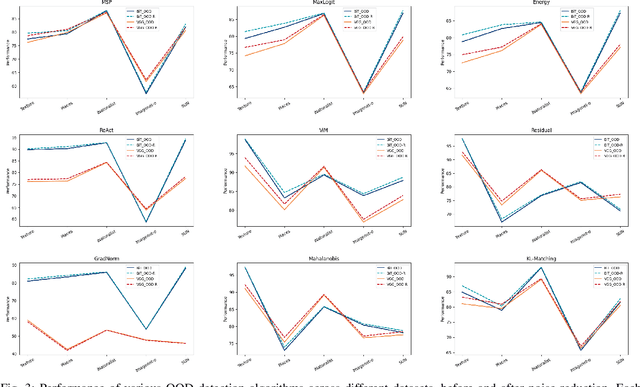
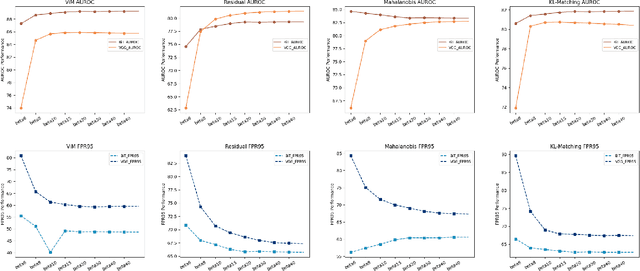
In the dynamic realms of machine learning and deep learning, the robustness and reliability of models are paramount, especially in critical real-world applications. A fundamental challenge in this sphere is managing Out-of-Distribution (OOD) samples, significantly increasing the risks of model misclassification and uncertainty. Our work addresses this challenge by enhancing the detection and management of OOD samples in neural networks. We introduce OOD-R (Out-of-Distribution-Rectified), a meticulously curated collection of open-source datasets with enhanced noise reduction properties. In-Distribution (ID) noise in existing OOD datasets can lead to inaccurate evaluation of detection algorithms. Recognizing this, OOD-R incorporates noise filtering technologies to refine the datasets, ensuring a more accurate and reliable evaluation of OOD detection algorithms. This approach not only improves the overall quality of data but also aids in better distinguishing between OOD and ID samples, resulting in up to a 2.5\% improvement in model accuracy and a minimum 3.2\% reduction in false positives. Furthermore, we present ActFun, an innovative method that fine-tunes the model's response to diverse inputs, thereby improving the stability of feature extraction and minimizing specificity issues. ActFun addresses the common problem of model overconfidence in OOD detection by strategically reducing the influence of hidden units, which enhances the model's capability to estimate OOD uncertainty more accurately. Implementing ActFun in the OOD-R dataset has led to significant performance enhancements, including an 18.42\% increase in AUROC of the GradNorm method and a 16.93\% decrease in FPR95 of the Energy method. Overall, our research not only advances the methodologies in OOD detection but also emphasizes the importance of dataset integrity for accurate algorithm evaluation.