 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Visual Prompting for Cross-Domain Road Damage Detection
Nov 16, 2025
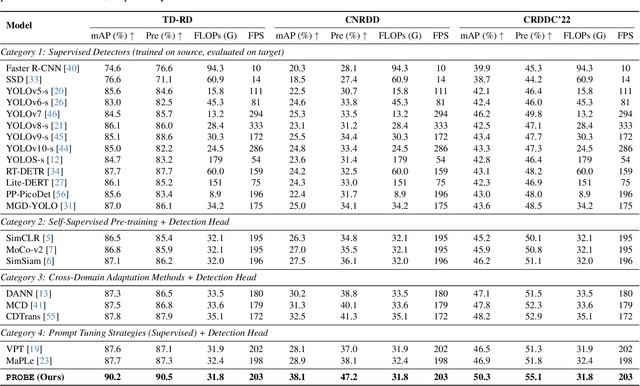
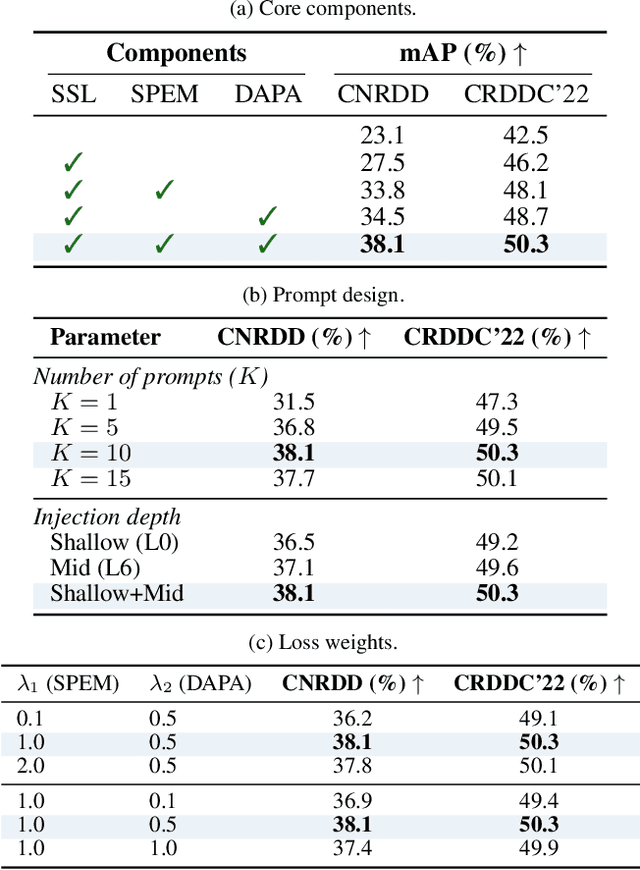

The deployment of automated pavement defect detection is often hindered by poor cross-domain generalization. Supervised detectors achieve strong in-domain accuracy but require costly re-annotation for new environments, while standard self-supervised methods capture generic features and remain vulnerable to domain shift. We propose \ours, a self-supervised framework that \emph{visually probes} target domains without labels. \ours introduces a Self-supervised Prompt Enhancement Module (SPEM), which derives defect-aware prompts from unlabeled target data to guide a frozen ViT backbone, and a Domain-Aware Prompt Alignment (DAPA) objective, which aligns prompt-conditioned source and target representations. Experiments on four challenging benchmarks show that \ours consistently outperforms strong supervised, self-supervised, and adaptation baselines, achieving robust zero-shot transfer, improved resilience to domain variations, and high data efficiency in few-shot adaptation. These results highlight self-supervised prompting as a practical direction for building scalable and adaptive visual inspection systems. Source code is publicly available: https://github.com/xixiaouab/PROBE/tree/main
Beyond Editing Pairs: Fine-Grained Instructional Image Editing via Multi-Scale Learnable Regions
May 25, 2025Current text-driven image editing methods typically follow one of two directions: relying on large-scale, high-quality editing pair datasets to improve editing precision and diversity, or exploring alternative dataset-free techniques. However, constructing large-scale editing datasets requires carefully designed pipelines, is time-consuming, and often results in unrealistic samples or unwanted artifacts. Meanwhile, dataset-free methods may suffer from limited instruction comprehension and restricted editing capabilities. Faced with these challenges, the present work develops a novel paradigm for instruction-driven image editing that leverages widely available and enormous text-image pairs, instead of relying on editing pair datasets. Our approach introduces a multi-scale learnable region to localize and guide the editing process. By treating the alignment between images and their textual descriptions as supervision and learning to generate task-specific editing regions, our method achieves high-fidelity, precise, and instruction-consistent image editing. Extensive experiments demonstrate that the proposed approach attains state-of-the-art performance across various tasks and benchmarks, while exhibiting strong adaptability to various types of generative models.
CIBR: Cross-modal Information Bottleneck Regularization for Robust CLIP Generalization
Mar 31, 2025Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success in cross-modal tasks such as zero-shot image classification and text-image retrieval by effectively aligning visual and textual representations. However, the theoretical foundations underlying CLIP's strong generalization remain unclear. In this work, we address this gap by proposing the Cross-modal Information Bottleneck (CIB) framework. CIB offers a principled interpretation of CLIP's contrastive learning objective as an implicit Information Bottleneck optimization. Under this view, the model maximizes shared cross-modal information while discarding modality-specific redundancies, thereby preserving essential semantic alignment across modalities. Building on this insight, we introduce a Cross-modal Information Bottleneck Regularization (CIBR) method that explicitly enforces these IB principles during training. CIBR introduces a penalty term to discourage modality-specific redundancy, thereby enhancing semantic alignment between image and text features. We validate CIBR on extensive vision-language benchmarks, including zero-shot classification across seven diverse image datasets and text-image retrieval on MSCOCO and Flickr30K. The results show consistent performance gains over standard CLIP. These findings provide the first theoretical understanding of CLIP's generalization through the IB lens. They also demonstrate practical improvements, offering guidance for future cross-modal representation learning.
CAD-VAE: Leveraging Correlation-Aware Latents for Comprehensive Fair Disentanglement
Mar 11, 2025While deep generative models have significantly advanced representation learning, they may inherit or amplify biases and fairness issues by encoding sensitive attributes alongside predictive features. Enforcing strict independence in disentanglement is often unrealistic when target and sensitive factors are naturally correlated. To address this challenge, we propose CAD-VAE (Correlation-Aware Disentangled VAE), which introduces a correlated latent code to capture the shared information between target and sensitive attributes. Given this correlated latent, our method effectively separates overlapping factors without extra domain knowledge by directly minimizing the conditional mutual information between target and sensitive codes. A relevance-driven optimization strategy refines the correlated code by efficiently capturing essential correlated features and eliminating redundancy. Extensive experiments on benchmark datasets demonstrate that CAD-VAE produces fairer representations, realistic counterfactuals, and improved fairness-aware image editing.
Dense Object Detection Based on De-homogenized Queries
Feb 11, 2025Dense object detection is widely used in automatic driving, video surveillance, and other fields. This paper focuses on the challenging task of dense object detection. Currently, detection methods based on greedy algorithms, such as non-maximum suppression (NMS), often produce many repetitive predictions or missed detections in dense scenarios, which is a common problem faced by NMS-based algorithms. Through the end-to-end DETR (DEtection TRansformer), as a type of detector that can incorporate the post-processing de-duplication capability of NMS, etc., into the network, we found that homogeneous queries in the query-based detector lead to a reduction in the de-duplication capability of the network and the learning efficiency of the encoder, resulting in duplicate prediction and missed detection problems. To solve this problem, we propose learnable differentiated encoding to de-homogenize the queries, and at the same time, queries can communicate with each other via differentiated encoding information, replacing the previous self-attention among the queries. In addition, we used joint loss on the output of the encoder that considered both location and confidence prediction to give a higher-quality initialization for queries. Without cumbersome decoder stacking and guaranteeing accuracy, our proposed end-to-end detection framework was more concise and reduced the number of parameters by about 8% compared to deformable DETR. Our method achieved excellent results on the challenging CrowdHuman dataset with 93.6% average precision (AP), 39.2% MR-2, and 84.3% JI. The performance overperformed previous SOTA methods, such as Iter-E2EDet (Progressive End-to-End Object Detection) and MIP (One proposal, Multiple predictions). In addition, our method is more robust in various scenarios with different densities.