 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved YOLOv7 model for insulator defect detection
Feb 11, 2025Insulators are crucial insulation components and structural supports in power grids, playing a vital role in the transmission lines. Due to temperature fluctuations, internal stress, or damage from hail, insulators are prone to injury. Automatic detection of damaged insulators faces challenges such as diverse types, small defect targets, and complex backgrounds and shapes. Most research for detecting insulator defects has focused on a single defect type or a specific material. However, the insulators in the grid's transmission lines have different colors and materials. Various insulator defects coexist, and the existing methods have difficulty meeting the practical application requirements. Current methods suffer from low detection accuracy and mAP0.5 cannot meet application requirements. This paper proposes an improved YOLOv7 model for multi-type insulator defect detection. First, our model replaces the SPPCSPC module with the RFB module to enhance the network's feature extraction capability. Second, a CA mechanism is introduced into the head part to enhance the network's feature representation ability and to improve detection accuracy. Third, a WIoU loss function is employed to address the low-quality samples hindering model generalization during training, thereby improving the model's overall performance. The experimental results indicate that the proposed model exhibits enhancements across various performance metrics. Specifically, there is a 1.6% advancement in mAP_0.5, a corresponding 1.6% enhancement in mAP_0.5:0.95, a 1.3% elevation in precision, and a 1% increase in recall. Moreover, the model achieves parameter reduction by 3.2 million, leading to a decrease of 2.5 GFLOPS in computational cost. Notably, there is also an improvement of 2.81 milliseconds in single-image detection speed.
Dense Object Detection Based on De-homogenized Queries
Feb 11, 2025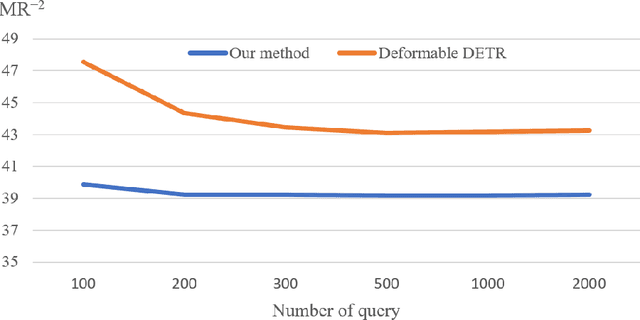
Dense object detection is widely used in automatic driving, video surveillance, and other fields. This paper focuses on the challenging task of dense object detection. Currently, detection methods based on greedy algorithms, such as non-maximum suppression (NMS), often produce many repetitive predictions or missed detections in dense scenarios, which is a common problem faced by NMS-based algorithms. Through the end-to-end DETR (DEtection TRansformer), as a type of detector that can incorporate the post-processing de-duplication capability of NMS, etc., into the network, we found that homogeneous queries in the query-based detector lead to a reduction in the de-duplication capability of the network and the learning efficiency of the encoder, resulting in duplicate prediction and missed detection problems. To solve this problem, we propose learnable differentiated encoding to de-homogenize the queries, and at the same time, queries can communicate with each other via differentiated encoding information, replacing the previous self-attention among the queries. In addition, we used joint loss on the output of the encoder that considered both location and confidence prediction to give a higher-quality initialization for queries. Without cumbersome decoder stacking and guaranteeing accuracy, our proposed end-to-end detection framework was more concise and reduced the number of parameters by about 8% compared to deformable DETR. Our method achieved excellent results on the challenging CrowdHuman dataset with 93.6% average precision (AP), 39.2% MR-2, and 84.3% JI. The performance overperformed previous SOTA methods, such as Iter-E2EDet (Progressive End-to-End Object Detection) and MIP (One proposal, Multiple predictions). In addition, our method is more robust in various scenarios with different densities.
Foreign-Object Detection in High-Voltage Transmission Line Based on Improved YOLOv8m
Feb 11, 2025The safe operation of high-voltage transmission lines ensures the power grid's security. Various foreign objects attached to the transmission lines, such as balloons, kites and nesting birds, can significantly affect the safe and stable operation of high-voltage transmission lines. With the advancement of computer vision technology, periodic automatic inspection of foreign objects is efficient and necessary. Existing detection methods have low accuracy because foreign objects at-tached to the transmission lines are complex, including occlusions, diverse object types, significant scale variations, and complex backgrounds. In response to the practical needs of the Yunnan Branch of China Southern Power Grid Co., Ltd., this paper proposes an improved YOLOv8m-based model for detecting foreign objects on transmission lines. Experiments are conducted on a dataset collected from Yunnan Power Grid. The proposed model enhances the original YOLOv8m by in-corporating a Global Attention Module (GAM) into the backbone to focus on occluded foreign objects, replacing the SPPF module with the SPPCSPC module to augment the model's multiscale feature extraction capability, and introducing the Focal-EIoU loss function to address the issue of high- and low-quality sample imbalances. These improvements accelerate model convergence and enhance detection accuracy. The experimental results demonstrate that our proposed model achieves a 2.7% increase in mAP_0.5, a 4% increase in mAP_0.5:0.95, and a 6% increase in recall.
Improved YOLOv5s model for key components detection of power transmission lines
Feb 10, 2025High-voltage transmission lines are located far from the road, resulting in inconvenient inspection work and rising maintenance costs. Intelligent inspection of power transmission lines has become increasingly important. However, subsequent intelligent inspection relies on accurately detecting various key components. Due to the low detection accuracy of key components in transmission line image inspection, this paper proposed an improved object detection model based on the YOLOv5s (You Only Look Once Version 5 Small) model to improve the detection accuracy of key components of transmission lines. According to the characteristics of the power grid inspection image, we first modify the distance measurement in the k-means clustering to improve the anchor matching of the YOLOv5s model. Then, we add the convolutional block attention module (CBAM) attention mechanism to the backbone network to improve accuracy. Finally, we apply the focal loss function to reduce the impact of class imbalance. Our improved method's mAP (mean average precision) reached 98.1%, the precision reached 97.5%, the recall reached 94.4%, and the detection rate reached 84.8 FPS (frames per second). The experimental results show that our improved model improves detection accuracy and has performance advantages over other models.
An Appearance Defect Detection Method for Cigarettes Based on C-CenterNet
Feb 10, 2025
Due to the poor adaptability of traditional methods in the cigarette detection task on the automatic cigarette production line, it is difficult to accurately identify whether a cigarette has defects and the types of defects; thus, a cigarette appearance defect detection method based on C-CenterNet is proposed. This detector uses keypoint estimation to locate center points and regresses all other defect properties. Firstly, Resnet50 is used as the backbone feature extraction network, and the convolutional block attention mechanism (CBAM) is introduced to enhance the network's ability to extract effective features and reduce the interference of non-target information. At the same time, the feature pyramid network is used to enhance the feature extraction of each layer. Then, deformable convolution is used to replace part of the common convolution to enhance the learning ability of different shape defects. Finally, the activation function ACON (ActivateOrNot) is used instead of the ReLU activation function, and the activation operation of some neurons is adaptively selected to improve the detection accuracy of the network. The experimental results are mainly acquired via the mean Average Precision (mAP). The experimental results show that the mAP of the C-CenterNet model applied in the cigarette appearance defect detection task is 95.01%. Compared with the original CenterNet model, the model's success rate is increased by 6.14%, so it can meet the requirements of precision and adaptability in cigarette detection tasks on the automatic cigarette production line.
Coarse-to-Fine Structure-Aware Artistic Style Transfer
Feb 08, 2025



Artistic style transfer aims to use a style image and a content image to synthesize a target image that retains the same artistic expression as the style image while preserving the basic content of the content image. Many recently proposed style transfer methods have a common problem; that is, they simply transfer the texture and color of the style image to the global structure of the content image. As a result, the content image has a local structure that is not similar to the local structure of the style image. In this paper, we present an effective method that can be used to transfer style patterns while fusing the local style structure into the local content structure. In our method, dif-ferent levels of coarse stylized features are first reconstructed at low resolution using a Coarse Network, in which style color distribution is roughly transferred, and the content structure is combined with the style structure. Then, the reconstructed features and the content features are adopted to synthesize high-quality structure-aware stylized images with high resolution using a Fine Network with three structural selective fusion (SSF) modules. The effectiveness of our method is demonstrated through the generation of appealing high-quality stylization results and a com-parison with some state-of-the-art style transfer methods.
Multiscale style transfer based on a Laplacian pyramid for traditional Chinese painting
Feb 07, 2025


Style transfer is adopted to synthesize appealing stylized images that preserve the structure of a content image but carry the pattern of a style image. Many recently proposed style transfer methods use only western oil paintings as style images to achieve image stylization. As a result, unnatural messy artistic effects are produced in stylized images when using these methods to directly transfer the patterns of traditional Chinese paintings, which are composed of plain colors and abstract objects. Moreover, most of them work only at the original image scale and thus ignore multiscale image information during training. In this paper, we present a novel effective multiscale style transfer method based on Laplacian pyramid decomposition and reconstruction, which can transfer unique patterns of Chinese paintings by learning different image features at different scales. In the first stage, the holistic patterns are transferred at low resolution by adopting a Style Transfer Base Network. Then, the details of the content and style are gradually enhanced at higher resolutions by a Detail Enhancement Network with an edge information selection (EIS) module in the second stage. The effectiveness of our method is demonstrated through the generation of appealing high-quality stylization results and a comparison with some state-of-the-art style transfer methods. Datasets and codes are available at https://github.com/toby-katakuri/LP_StyleTransferNet.
RS-YOLOX: A High Precision Detector for Object Detection in Satellite Remote Sensing Images
Feb 05, 2025



Automatic object detection by satellite remote sensing images is of great significance for resource exploration and natural disaster assessment. To solve existing problems in remote sensing image detection, this article proposes an improved YOLOX model for satellite remote sensing image automatic detection. This model is named RS-YOLOX. To strengthen the feature learning ability of the network, we used Efficient Channel Attention (ECA) in the backbone network of YOLOX and combined the Adaptively Spatial Feature Fusion (ASFF) with the neck network of YOLOX. To balance the numbers of positive and negative samples in training, we used the Varifocal Loss function. Finally, to obtain a high-performance remote sensing object detector, we combined the trained model with an open-source framework called Slicing Aided Hyper Inference (SAHI). This work evaluated models on three aerial remote sensing datasets (DOTA-v1.5, TGRS-HRRSD, and RSOD). Our comparative experiments demonstrate that our model has the highest accuracy in detecting objects in remote sensing image datasets.