 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling On-Device LLMs Personalization with Smartphone Sensing
Jul 05, 2024

This demo presents a novel end-to-end framework that combines on-device large language models (LLMs) with smartphone sensing technologies to achieve context-aware and personalized services. The framework addresses critical limitations of current personalization solutions via cloud-based LLMs, such as privacy concerns, latency and cost, and limited personal sensor data. To achieve this, we innovatively proposed deploying LLMs on smartphones with multimodal sensor data and customized prompt engineering, ensuring privacy and enhancing personalization performance through context-aware sensing. A case study involving a university student demonstrated the proposed framework's capability to provide tailored recommendations. In addition, we show that the proposed framework achieves the best trade-off in privacy, performance, latency, cost, battery and energy consumption between on-device and cloud LLMs. Future work aims to integrate more diverse sensor data and conduct large-scale user studies to further refine the personalization. We envision the proposed framework could significantly improve user experiences in various domains such as healthcare, productivity, and entertainment by providing secure, context-aware, and efficient interactions directly on users' devices.
Meta-Learning with Less Forgetting on Large-Scale Non-Stationary Task Distributions
Sep 03, 2022

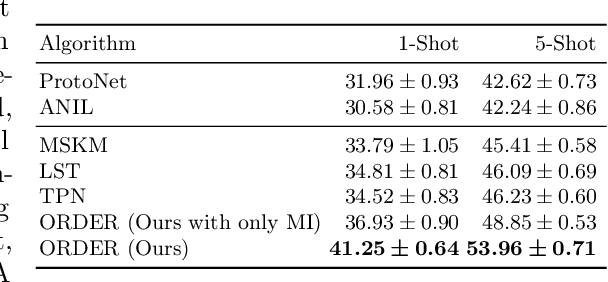
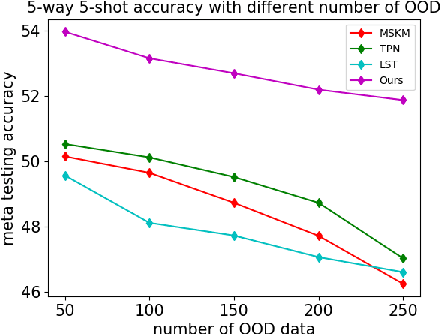
The paradigm of machine intelligence moves from purely supervised learning to a more practical scenario when many loosely related unlabeled data are available and labeled data is scarce. Most existing algorithms assume that the underlying task distribution is stationary. Here we consider a more realistic and challenging setting in that task distributions evolve over time. We name this problem as Semi-supervised meta-learning with Evolving Task diStributions, abbreviated as SETS. Two key challenges arise in this more realistic setting: (i) how to use unlabeled data in the presence of a large amount of unlabeled out-of-distribution (OOD) data; and (ii) how to prevent catastrophic forgetting on previously learned task distributions due to the task distribution shift. We propose an OOD Robust and knowleDge presErved semi-supeRvised meta-learning approach (ORDER), to tackle these two major challenges. Specifically, our ORDER introduces a novel mutual information regularization to robustify the model with unlabeled OOD data and adopts an optimal transport regularization to remember previously learned knowledge in feature space. In addition, we test our method on a very challenging dataset: SETS on large-scale non-stationary semi-supervised task distributions consisting of (at least) 72K tasks. With extensive experiments, we demonstrate the proposed ORDER alleviates forgetting on evolving task distributions and is more robust to OOD data than related strong baselines.
Improving Task-free Continual Learning by Distributionally Robust Memory Evolution
Jul 15, 2022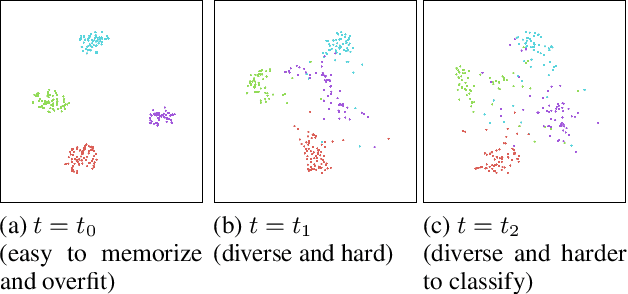
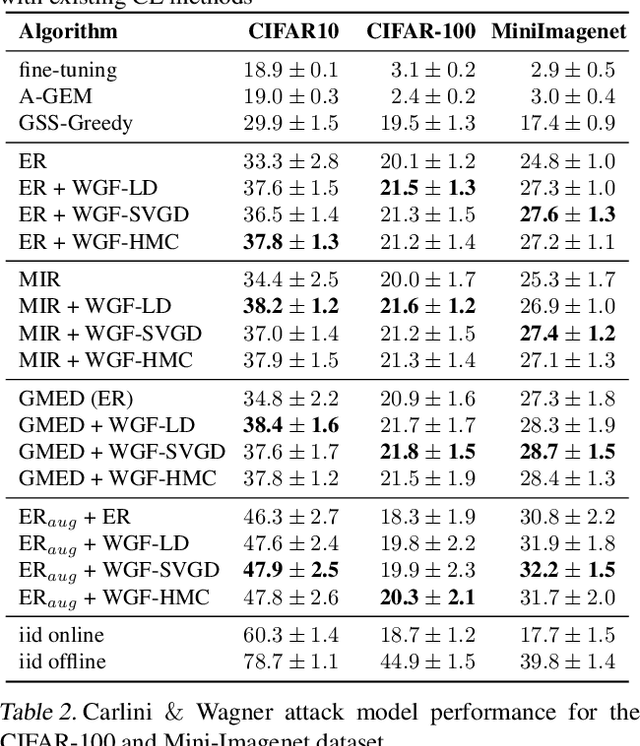
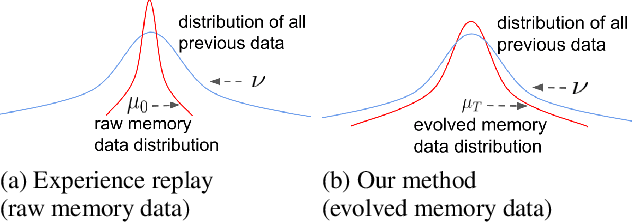
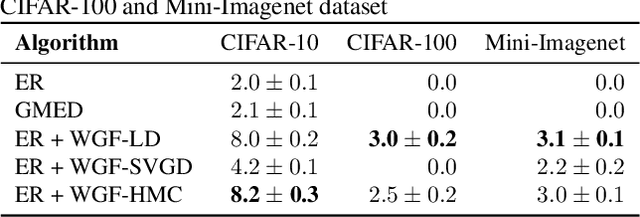
Task-free continual learning (CL) aims to learn a non-stationary data stream without explicit task definitions and not forget previous knowledge. The widely adopted memory replay approach could gradually become less effective for long data streams, as the model may memorize the stored examples and overfit the memory buffer. Second, existing methods overlook the high uncertainty in the memory data distribution since there is a big gap between the memory data distribution and the distribution of all the previous data examples. To address these problems, for the first time, we propose a principled memory evolution framework to dynamically evolve the memory data distribution by making the memory buffer gradually harder to be memorized with distributionally robust optimization (DRO). We then derive a family of methods to evolve the memory buffer data in the continuous probability measure space with Wasserstein gradient flow (WGF). The proposed DRO is w.r.t the worst-case evolved memory data distribution, thus guarantees the model performance and learns significantly more robust features than existing memory-replay-based methods. Extensive experiments on existing benchmarks demonstrate the effectiveness of the proposed methods for alleviating forgetting. As a by-product of the proposed framework, our method is more robust to adversarial examples than existing task-free CL methods.
Meta Learning on a Sequence of Imbalanced Domains with Difficulty Awareness
Sep 29, 2021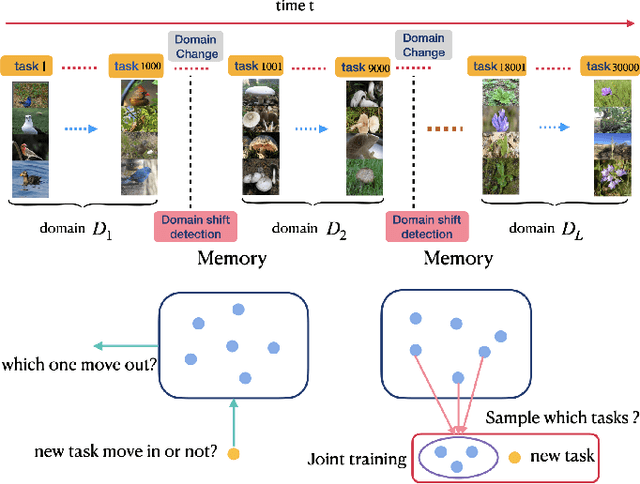
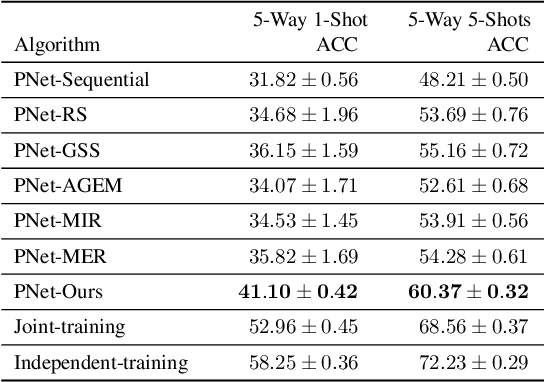
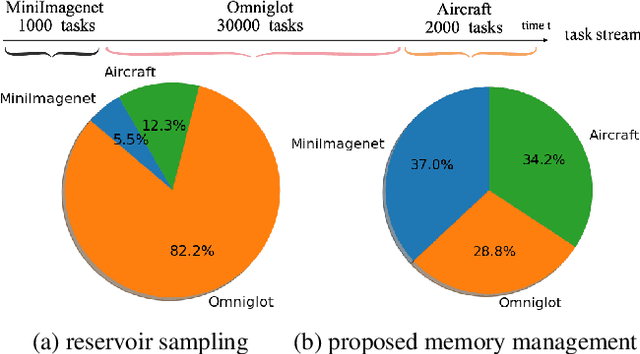
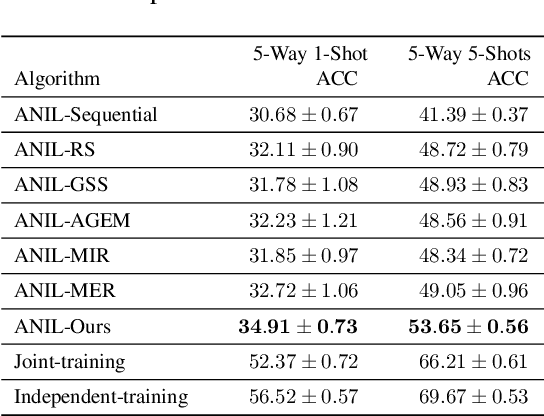
Recognizing new objects by learning from a few labeled examples in an evolving environment is crucial to obtain excellent generalization ability for real-world machine learning systems. A typical setting across current meta learning algorithms assumes a stationary task distribution during meta training. In this paper, we explore a more practical and challenging setting where task distribution changes over time with domain shift. Particularly, we consider realistic scenarios where task distribution is highly imbalanced with domain labels unavailable in nature. We propose a kernel-based method for domain change detection and a difficulty-aware memory management mechanism that jointly considers the imbalanced domain size and domain importance to learn across domains continuously. Furthermore, we introduce an efficient adaptive task sampling method during meta training, which significantly reduces task gradient variance with theoretical guarantees. Finally, we propose a challenging benchmark with imbalanced domain sequences and varied domain difficulty. We have performed extensive evaluations on the proposed benchmark, demonstrating the effectiveness of our method. We made our code publicly available.
Transformer-based Conditional Variational Autoencoder for Controllable Story Generation
Jan 04, 2021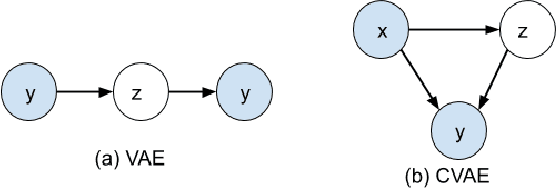

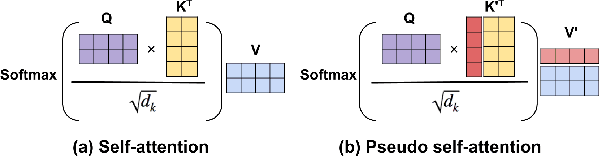

We investigate large-scale latent variable models (LVMs) for neural story generation -- an under-explored application for open-domain long text -- with objectives in two threads: generation effectiveness and controllability. LVMs, especially the variational autoencoder (VAE), have achieved both effective and controllable generation through exploiting flexible distributional latent representations. Recently, Transformers and its variants have achieved remarkable effectiveness without explicit latent representation learning, thus lack satisfying controllability in generation. In this paper, we advocate to revive latent variable modeling, essentially the power of representation learning, in the era of Transformers to enhance controllability without hurting state-of-the-art generation effectiveness. Specifically, we integrate latent representation vectors with a Transformer-based pre-trained architecture to build conditional variational autoencoder (CVAE). Model components such as encoder, decoder and the variational posterior are all built on top of pre-trained language models -- GPT2 specifically in this paper. Experiments demonstrate state-of-the-art conditional generation ability of our model, as well as its excellent representation learning capability and controllability.
Outline to Story: Fine-grained Controllable Story Generation from Cascaded Events
Jan 04, 2021



Large-scale pretrained language models have shown thrilling generation capabilities, especially when they generate consistent long text in thousands of words with ease. However, users of these models can only control the prefix of sentences or certain global aspects of generated text. It is challenging to simultaneously achieve fine-grained controllability and preserve the state-of-the-art unconditional text generation capability. In this paper, we first propose a new task named "Outline to Story" (O2S) as a test bed for fine-grained controllable generation of long text, which generates a multi-paragraph story from cascaded events, i.e. a sequence of outline events that guide subsequent paragraph generation. We then create dedicate datasets for future benchmarks, built by state-of-the-art keyword extraction techniques. Finally, we propose an extremely simple yet strong baseline method for the O2S task, which fine tunes pre-trained language models on augmented sequences of outline-story pairs with simple language modeling objective. Our method does not introduce any new parameters or perform any architecture modification, except several special tokens as delimiters to build augmented sequences. Extensive experiments on various datasets demonstrate state-of-the-art conditional story generation performance with our model, achieving better fine-grained controllability and user flexibility. Our paper is among the first ones by our knowledge to propose a model and to create datasets for the task of "outline to story". Our work also instantiates research interest of fine-grained controllable generation of open-domain long text, where controlling inputs are represented by short text.
Implicit Deep Latent Variable Models for Text Generation
Sep 18, 2019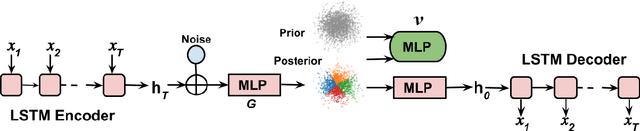

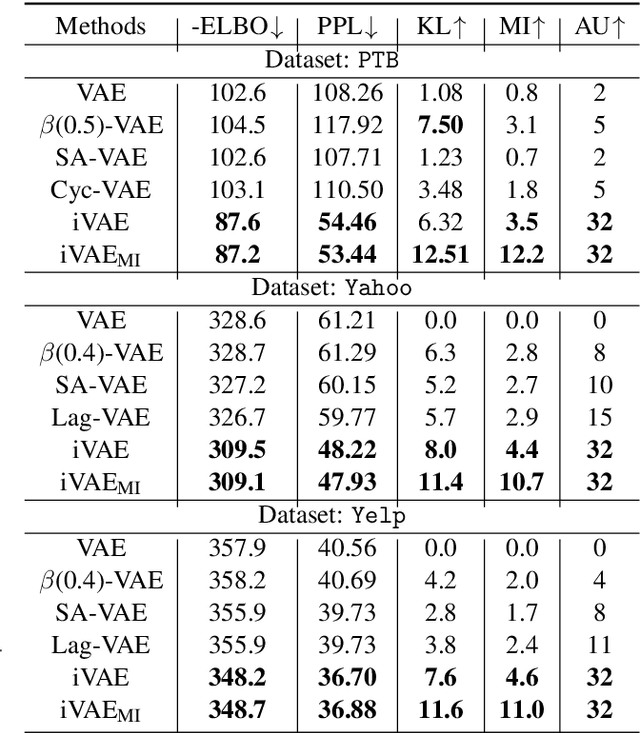

Deep latent variable models (LVM) such as variational auto-encoder (VAE) have recently played an important role in text generation. One key factor is the exploitation of smooth latent structures to guide the generation. However, the representation power of VAEs is limited due to two reasons: (1) the Gaussian assumption is often made on the variational posteriors; and meanwhile (2) a notorious "posterior collapse" issue occurs. In this paper, we advocate sample-based representations of variational distributions for natural language, leading to implicit latent features, which can provide flexible representation power compared with Gaussian-based posteriors. We further develop an LVM to directly match the aggregated posterior to the prior. It can be viewed as a natural extension of VAEs with a regularization of maximizing mutual information, mitigating the "posterior collapse" issue. We demonstrate the effectiveness and versatility of our models in various text generation scenarios, including language modeling, unaligned style transfer, and dialog response generation. The source code to reproduce our experimental results is available on GitHub.