 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfakeBench-MM: A Comprehensive Benchmark for Multimodal Deepfake Detection
Oct 26, 2025The misuse of advanced generative AI models has resulted in the widespread proliferation of falsified data, particularly forged human-centric audiovisual content, which poses substantial societal risks (e.g., financial fraud and social instability). In response to this growing threat, several works have preliminarily explored countermeasures. However, the lack of sufficient and diverse training data, along with the absence of a standardized benchmark, hinder deeper exploration. To address this challenge, we first build Mega-MMDF, a large-scale, diverse, and high-quality dataset for multimodal deepfake detection. Specifically, we employ 21 forgery pipelines through the combination of 10 audio forgery methods, 12 visual forgery methods, and 6 audio-driven face reenactment methods. Mega-MMDF currently contains 0.1 million real samples and 1.1 million forged samples, making it one of the largest and most diverse multimodal deepfake datasets, with plans for continuous expansion. Building on it, we present DeepfakeBench-MM, the first unified benchmark for multimodal deepfake detection. It establishes standardized protocols across the entire detection pipeline and serves as a versatile platform for evaluating existing methods as well as exploring novel approaches. DeepfakeBench-MM currently supports 5 datasets and 11 multimodal deepfake detectors. Furthermore, our comprehensive evaluations and in-depth analyses uncover several key findings from multiple perspectives (e.g., augmentation, stacked forgery). We believe that DeepfakeBench-MM, together with our large-scale Mega-MMDF, will serve as foundational infrastructures for advancing multimodal deepfake detection.
PIA: Deepfake Detection Using Phoneme-Temporal and Identity-Dynamic Analysis
Oct 16, 2025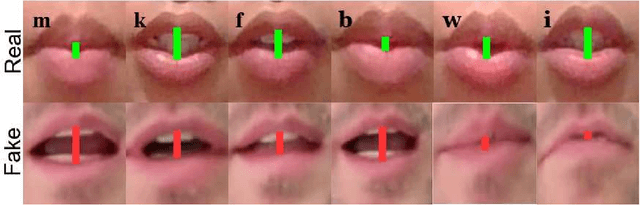
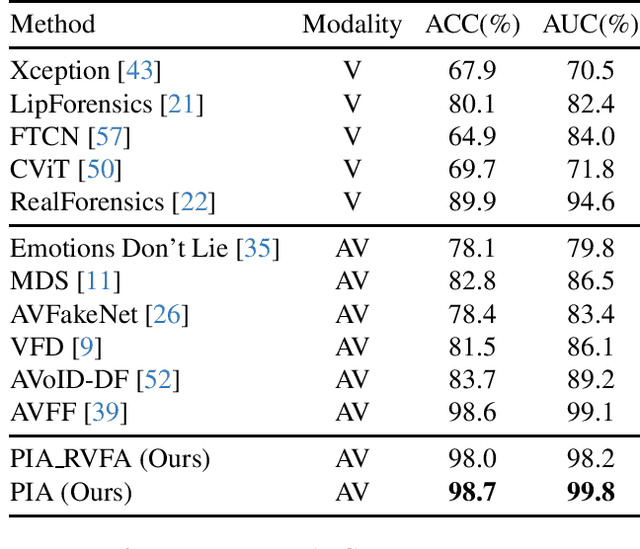
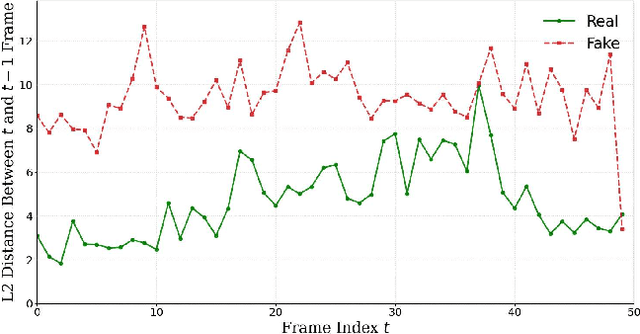
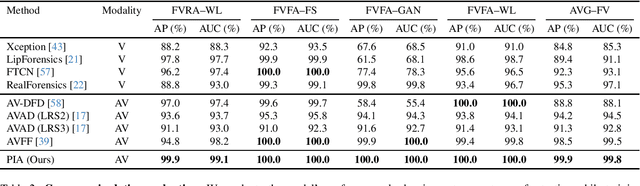
The rise of manipulated media has made deepfakes a particularly insidious threat, involving various generative manipulations such as lip-sync modifications, face-swaps, and avatar-driven facial synthesis. Conventional detection methods, which predominantly depend on manually designed phoneme-viseme alignment thresholds, fundamental frame-level consistency checks, or a unimodal detection strategy, inadequately identify modern-day deepfakes generated by advanced generative models such as GANs, diffusion models, and neural rendering techniques. These advanced techniques generate nearly perfect individual frames yet inadvertently create minor temporal discrepancies frequently overlooked by traditional detectors. We present a novel multimodal audio-visual framework, Phoneme-Temporal and Identity-Dynamic Analysis(PIA), incorporating language, dynamic face motion, and facial identification cues to address these limitations. We utilize phoneme sequences, lip geometry data, and advanced facial identity embeddings. This integrated method significantly improves the detection of subtle deepfake alterations by identifying inconsistencies across multiple complementary modalities. Code is available at https://github.com/skrantidatta/PIA
Detecting Lip-Syncing Deepfakes: Vision Temporal Transformer for Analyzing Mouth Inconsistencies
Apr 02, 2025Deepfakes are AI-generated media in which the original content is digitally altered to create convincing but manipulated images, videos, or audio. Among the various types of deepfakes, lip-syncing deepfakes are one of the most challenging deepfakes to detect. In these videos, a person's lip movements are synthesized to match altered or entirely new audio using AI models. Therefore, unlike other types of deepfakes, the artifacts in lip-syncing deepfakes are confined to the mouth region, making them more subtle and, thus harder to discern. In this paper, we propose LIPINC-V2, a novel detection framework that leverages a combination of vision temporal transformer with multihead cross-attention to detect lip-syncing deepfakes by identifying spatiotemporal inconsistencies in the mouth region. These inconsistencies appear across adjacent frames and persist throughout the video. Our model can successfully capture both short-term and long-term variations in mouth movement, enhancing its ability to detect these inconsistencies. Additionally, we created a new lip-syncing deepfake dataset, LipSyncTIMIT, which was generated using five state-of-the-art lip-syncing models to simulate real-world scenarios. Extensive experiments on our proposed LipSyncTIMIT dataset and two other benchmark deepfake datasets demonstrate that our model achieves state-of-the-art performance. The code and the dataset are available at https://github.com/skrantidatta/LIPINC-V2 .
Exposing Lip-syncing Deepfakes from Mouth Inconsistencies
Jan 18, 2024



A lip-syncing deepfake is a digitally manipulated video in which a person's lip movements are created convincingly using AI models to match altered or entirely new audio. Lip-syncing deepfakes are a dangerous type of deepfakes as the artifacts are limited to the lip region and more difficult to discern. In this paper, we describe a novel approach, LIP-syncing detection based on mouth INConsistency (LIPINC), for lip-syncing deepfake detection by identifying temporal inconsistencies in the mouth region. These inconsistencies are seen in the adjacent frames and throughout the video. Our model can successfully capture these irregularities and outperforms the state-of-the-art methods on several benchmark deepfake datasets.
Soft-Attention Improves Skin Cancer Classification Performance
May 10, 2021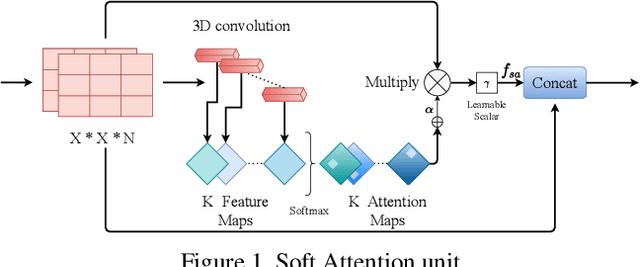
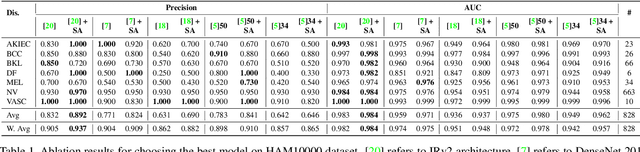
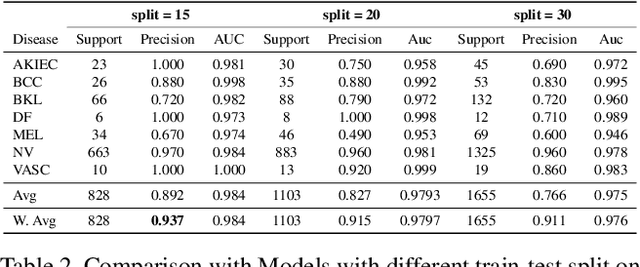
In clinical applications, neural networks must focus on and highlight the most important parts of an input image. Soft-Attention mechanism enables a neural network toachieve this goal. This paper investigates the effectiveness of Soft-Attention in deep neural architectures. The central aim of Soft-Attention is to boost the value of important features and suppress the noise-inducing features. We compare the performance of VGG, ResNet, InceptionResNetv2 and DenseNet architectures with and without the Soft-Attention mechanism, while classifying skin lesions. The original network when coupled with Soft-Attention outperforms the baseline[14] by 4.7% while achieving a precision of 93.7% on HAM10000 dataset. Additionally, Soft-Attention coupling improves the sensitivity score by 3.8% compared to baseline[28] and achieves 91.6% on ISIC-2017 dataset. The code is publicly available at github.