 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAViTeR: Learning Aligned Visual and Textual Representations Assisted by Image and Caption Generation
Paper and Code
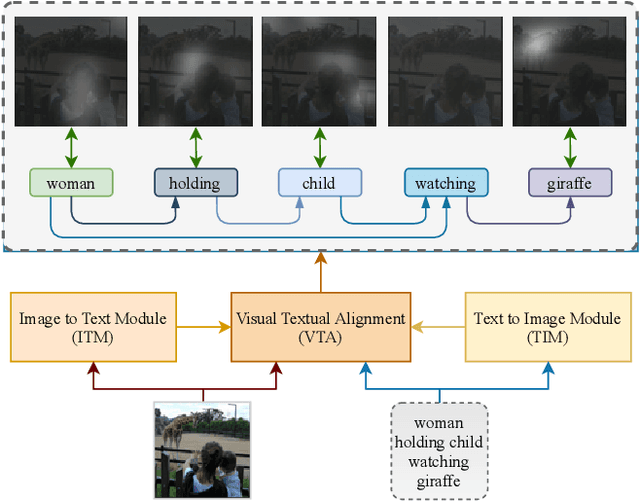
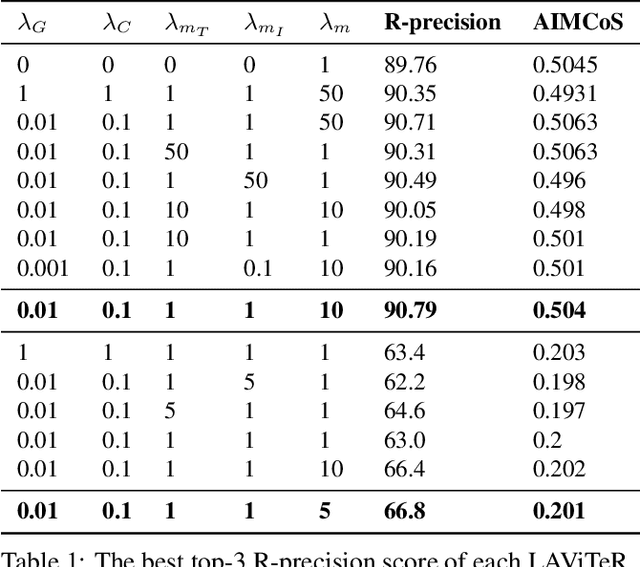
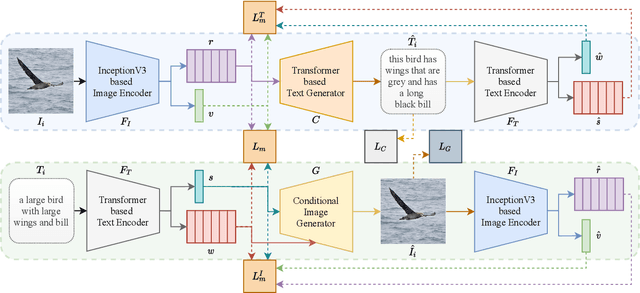
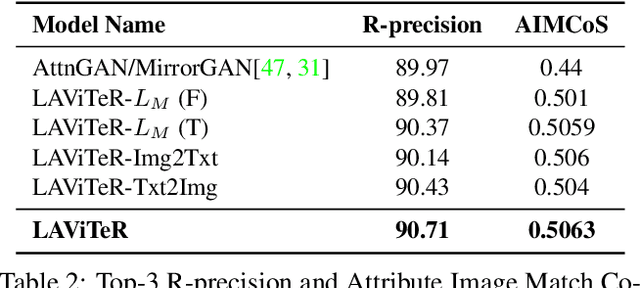
Pre-training visual and textual representations from large-scale image-text pairs is becoming a standard approach for many downstream vision-language tasks. The transformer-based models learn inter and intra-modal attention through a list of self-supervised learning tasks. This paper proposes LAViTeR, a novel architecture for visual and textual representation learning. The main module, Visual Textual Alignment (VTA) will be assisted by two auxiliary tasks, GAN-based image synthesis and Image Captioning. We also propose a new evaluation metric measuring the similarity between the learnt visual and textual embedding. The experimental results on two public datasets, CUB and MS-COCO, demonstrate superior visual and textual representation alignment in the joint feature embedding space