 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperSAM: Crafting a SAM Supernetwork via Structured Pruning and Unstructured Parameter Prioritization
Jan 15, 2025



Neural Architecture Search (NAS) is a powerful approach of automating the design of efficient neural architectures. In contrast to traditional NAS methods, recently proposed one-shot NAS methods prove to be more efficient in performing NAS. One-shot NAS works by generating a singular weight-sharing supernetwork that acts as a search space (container) of subnetworks. Despite its achievements, designing the one-shot search space remains a major challenge. In this work we propose a search space design strategy for Vision Transformer (ViT)-based architectures. In particular, we convert the Segment Anything Model (SAM) into a weight-sharing supernetwork called SuperSAM. Our approach involves automating the search space design via layer-wise structured pruning and parameter prioritization. While the structured pruning applies probabilistic removal of certain transformer layers, parameter prioritization performs weight reordering and slicing of MLP-blocks in the remaining layers. We train supernetworks on several datasets using the sandwich rule. For deployment, we enhance subnetwork discovery by utilizing a program autotuner to identify efficient subnetworks within the search space. The resulting subnetworks are 30-70% smaller in size compared to the original pre-trained SAM ViT-B, yet outperform the pretrained model. Our work introduces a new and effective method for ViT NAS search-space design.
SAM-I-Am: Semantic Boosting for Zero-shot Atomic-Scale Electron Micrograph Segmentation
Apr 09, 2024



Image segmentation is a critical enabler for tasks ranging from medical diagnostics to autonomous driving. However, the correct segmentation semantics - where are boundaries located? what segments are logically similar? - change depending on the domain, such that state-of-the-art foundation models can generate meaningless and incorrect results. Moreover, in certain domains, fine-tuning and retraining techniques are infeasible: obtaining labels is costly and time-consuming; domain images (micrographs) can be exponentially diverse; and data sharing (for third-party retraining) is restricted. To enable rapid adaptation of the best segmentation technology, we propose the concept of semantic boosting: given a zero-shot foundation model, guide its segmentation and adjust results to match domain expectations. We apply semantic boosting to the Segment Anything Model (SAM) to obtain microstructure segmentation for transmission electron microscopy. Our booster, SAM-I-Am, extracts geometric and textural features of various intermediate masks to perform mask removal and mask merging operations. We demonstrate a zero-shot performance increase of (absolute) +21.35%, +12.6%, +5.27% in mean IoU, and a -9.91%, -18.42%, -4.06% drop in mean false positive masks across images of three difficulty classes over vanilla SAM (ViT-L).
The Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024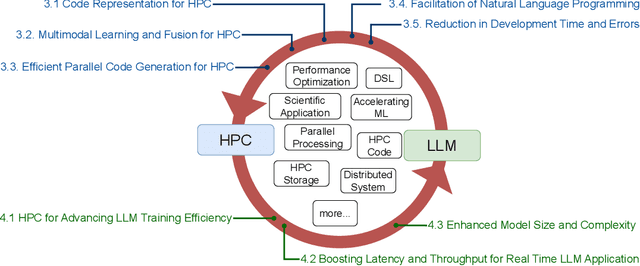

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
LEFL: Low Entropy Client Sampling in Federated Learning
Dec 29, 2023Federated learning (FL) is a machine learning paradigm where multiple clients collaborate to optimize a single global model using their private data. The global model is maintained by a central server that orchestrates the FL training process through a series of training rounds. In each round, the server samples clients from a client pool before sending them its latest global model parameters for further optimization. Naive sampling strategies implement random client sampling and fail to factor client data distributions for privacy reasons. Hence we proposes an alternative sampling strategy by performing a one-time clustering of clients based on their model's learned high-level features while respecting data privacy. This enables the server to perform stratified client sampling across clusters in every round. We show datasets of sampled clients selected with this approach yield a low relative entropy with respect to the global data distribution. Consequently, the FL training becomes less noisy and significantly improves the convergence of the global model by as much as 7.4% in some experiments. Furthermore, it also significantly reduces the communication rounds required to achieve a target accuracy.
Addressing Data Heterogeneity in Decentralized Learning via Topological Pre-processing
Dec 16, 2022Recently, local peer topology has been shown to influence the overall convergence of decentralized learning (DL) graphs in the presence of data heterogeneity. In this paper, we demonstrate the advantages of constructing a proxy-based locally heterogeneous DL topology to enhance convergence and maintain data privacy. In particular, we propose a novel peer clumping strategy to efficiently cluster peers before arranging them in a final training graph. By showing how locally heterogeneous graphs outperform locally homogeneous graphs of similar size and from the same global data distribution, we present a strong case for topological pre-processing. Moreover, we demonstrate the scalability of our approach by showing how the proposed topological pre-processing overhead remains small in large graphs while the performance gains get even more pronounced. Furthermore, we show the robustness of our approach in the presence of network partitions.
Resource-Aware Heterogeneous Federated Learning using Neural Architecture Search
Nov 09, 2022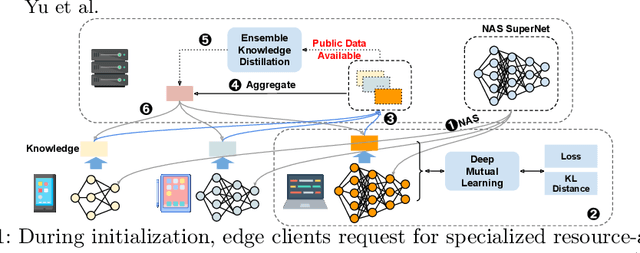
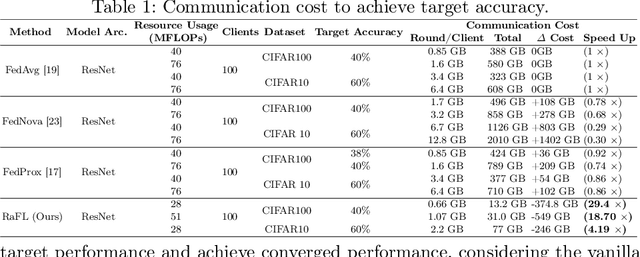
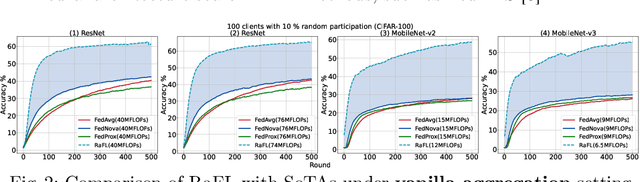
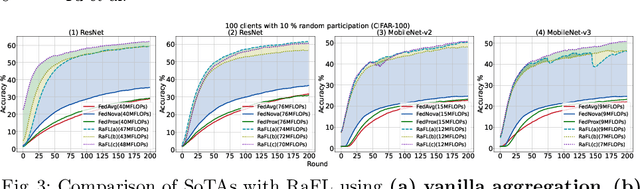
Federated Learning (FL) is extensively used to train AI/ML models in distributed and privacy-preserving settings. Participant edge devices in FL systems typically contain non-independent and identically distributed~(Non-IID) private data and unevenly distributed computational resources. Preserving user data privacy while optimizing AI/ML models in a heterogeneous federated network requires us to address data heterogeneity and system/resource heterogeneity. Hence, we propose \underline{R}esource-\underline{a}ware \underline{F}ederated \underline{L}earning~(RaFL) to address these challenges. RaFL allocates resource-aware models to edge devices using Neural Architecture Search~(NAS) and allows heterogeneous model architecture deployment by knowledge extraction and fusion. Integrating NAS into FL enables on-demand customized model deployment for resource-diverse edge devices. Furthermore, we propose a multi-model architecture fusion scheme allowing the aggregation of the distributed learning results. Results demonstrate RaFL's superior resource efficiency compared to SoTA.
SPATL: Salient Parameter Aggregation and Transfer Learning for Heterogeneous Clients in Federated Learning
Nov 29, 2021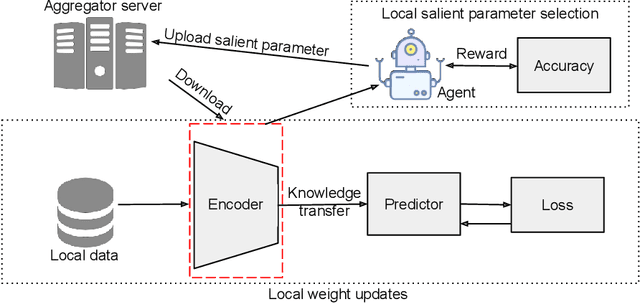
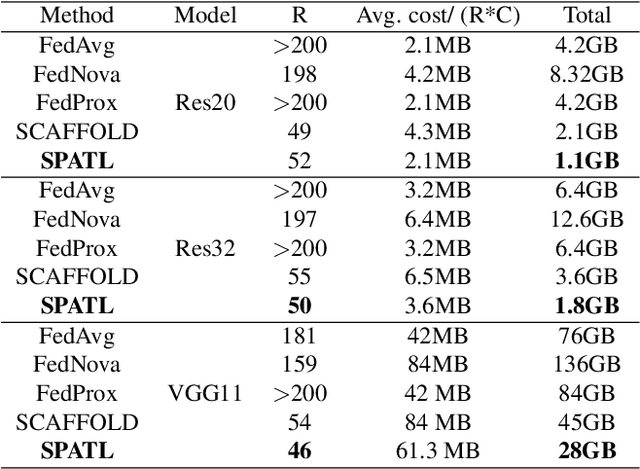
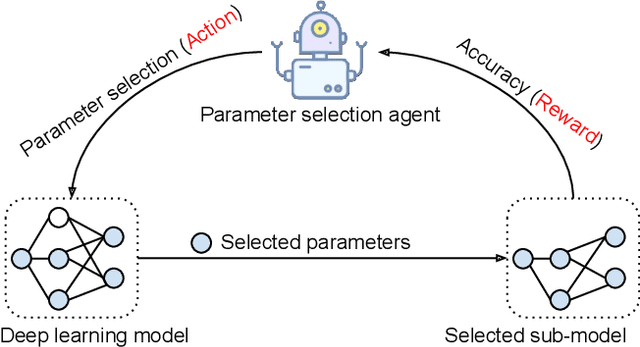
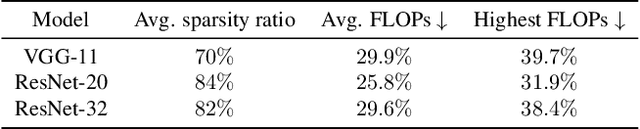
Efficient federated learning is one of the key challenges for training and deploying AI models on edge devices. However, maintaining data privacy in federated learning raises several challenges including data heterogeneity, expensive communication cost, and limited resources. In this paper, we address the above issues by (a) introducing a salient parameter selection agent based on deep reinforcement learning on local clients, and aggregating the selected salient parameters on the central server, and (b) splitting a normal deep learning model~(e.g., CNNs) as a shared encoder and a local predictor, and training the shared encoder through federated learning while transferring its knowledge to Non-IID clients by the local customized predictor. The proposed method (a) significantly reduces the communication overhead of federated learning and accelerates the model inference, while method (b) addresses the data heterogeneity issue in federated learning. Additionally, we leverage the gradient control mechanism to correct the gradient heterogeneity among clients. This makes the training process more stable and converge faster. The experiments show our approach yields a stable training process and achieves notable results compared with the state-of-the-art methods. Our approach significantly reduces the communication cost by up to 108 GB when training VGG-11, and needed $7.6 \times$ less communication overhead when training ResNet-20, while accelerating the local inference by reducing up to $39.7\%$ FLOPs on VGG-11.