 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOMAD: Generating Embeddings for Massive Distributed Graphs
Apr 10, 2026Successful machine learning on graphs or networks requires embeddings that not only represent nodes and edges as low-dimensional vectors but also preserve the graph structure. Established methods for generating embeddings require flexible exploration of the entire graph through repeated use of random walks that capture graph structure with samples of nodes and edges. These methods create scalability challenges for massive graphs with millions-to-billions of edges because single-node solutions have inadequate memory and processing capabilities. We present NOMAD, a distributed-memory graph embedding framework using the Message Passing Interface (MPI) for distributed graphs. NOMAD implements proximity-based models proposed in the widely popular LINE (Large-scale Information Network Embedding) algorithm. We propose several practical trade-offs to improve the scalability and communication overheads confronted by irregular and distributed graph embedding methods, catering to massive-scale graphs arising in web and science domains. NOMAD demonstrates median speedups of 10/100x on CPU-based NERSC Perlmutter cluster relative to the popular reference implementations of multi-threaded LINE and node2vec, 35-76x over distributed PBG, and competitive embedding quality relative to LINE, node2vec, and GraphVite, while yielding 12-370x end-to-end speedups on real-world graphs.
Communication-free Sampling and 4D Hybrid Parallelism for Scalable Mini-batch GNN Training
Apr 03, 2026Graph neural networks (GNNs) are widely used for learning on graph datasets derived from various real-world scenarios. Learning from extremely large graphs requires distributed training, and mini-batching with sampling is a popular approach for parallelizing GNN training. Existing distributed mini-batch approaches have significant performance bottlenecks due to expensive sampling methods and limited scaling when using data parallelism. In this work, we present ScaleGNN, a 4D parallel framework for scalable mini-batch GNN training that combines communication-free distributed sampling, 3D parallel matrix multiplication (PMM), and data parallelism. ScaleGNN introduces a uniform vertex sampling algorithm, enabling each process (GPU device) to construct its local mini-batch, i.e., subgraph partitions without any inter-process communication. 3D PMM enables scaling mini-batch training to much larger GPU counts than vanilla data parallelism with significantly lower communication overheads. We also present additional optimizations to overlap sampling with training, reduce communication overhead by sending data in lower precision, kernel fusion, and communication-computation overlap. We evaluate ScaleGNN on five graph datasets and demonstrate strong scaling up to 2048 GPUs on Perlmutter, 2048 GCDs on Frontier, and 1024 GPUs on Tuolumne. On Perlmutter, ScaleGNN achieves 3.5x end-to-end training speedup over the SOTA baseline on ogbn-products.
Enhanced Soups for Graph Neural Networks
Mar 14, 2025Graph Neural Networks (GNN) have demonstrated state-of-the-art performance in numerous scientific and high-performance computing (HPC) applications. Recent work suggests that "souping" (combining) individually trained GNNs into a single model can improve performance without increasing compute and memory costs during inference. However, existing souping algorithms are often slow and memory-intensive, which limits their scalability. We introduce Learned Souping for GNNs, a gradient-descent-based souping strategy that substantially reduces time and memory overhead compared to existing methods. Our approach is evaluated across multiple Open Graph Benchmark (OGB) datasets and GNN architectures, achieving up to 1.2% accuracy improvement and 2.1X speedup. Additionally, we propose Partition Learned Souping, a novel partition-based variant of learned souping that significantly reduces memory usage. On the ogbn-products dataset with GraphSAGE, partition learned souping achieves a 24.5X speedup and a 76% memory reduction without compromising accuracy.
MassiveGNN: Efficient Training via Prefetching for Massively Connected Distributed Graphs
Oct 30, 2024Graph Neural Networks (GNN) are indispensable in learning from graph-structured data, yet their rising computational costs, especially on massively connected graphs, pose significant challenges in terms of execution performance. To tackle this, distributed-memory solutions such as partitioning the graph to concurrently train multiple replicas of GNNs are in practice. However, approaches requiring a partitioned graph usually suffer from communication overhead and load imbalance, even under optimal partitioning and communication strategies due to irregularities in the neighborhood minibatch sampling. This paper proposes practical trade-offs for improving the sampling and communication overheads for representation learning on distributed graphs (using popular GraphSAGE architecture) by developing a parameterized continuous prefetch and eviction scheme on top of the state-of-the-art Amazon DistDGL distributed GNN framework, demonstrating about 15-40% improvement in end-to-end training performance on the National Energy Research Scientific Computing Center's (NERSC) Perlmutter supercomputer for various OGB datasets.
The Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024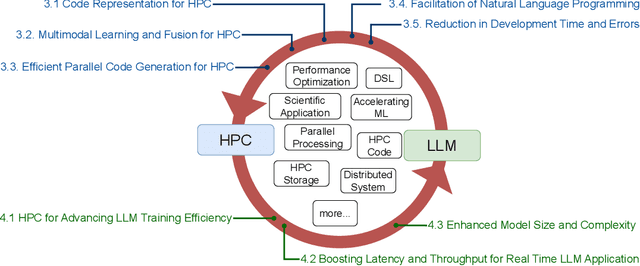

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
Accelerating Domain-aware Deep Learning Models with Distributed Training
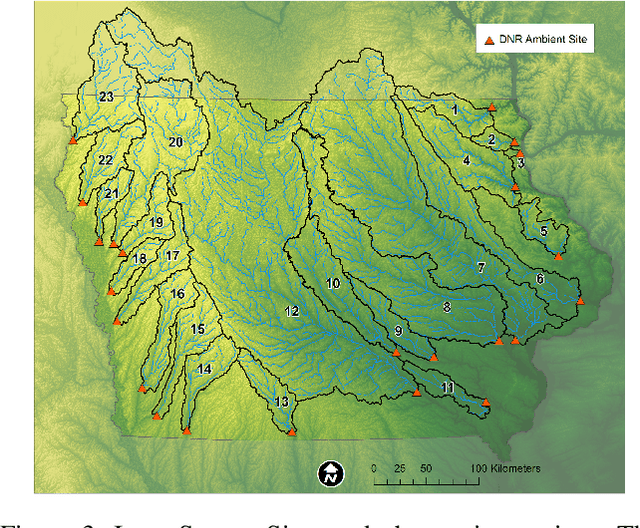
Jan 25, 2023Recent advances in data-generating techniques led to an explosive growth of geo-spatiotemporal data. In domains such as hydrology, ecology, and transportation, interpreting the complex underlying patterns of spatiotemporal interactions with the help of deep learning techniques hence becomes the need of the hour. However, applying deep learning techniques without domain-specific knowledge tends to provide sub-optimal prediction performance. Secondly, training such models on large-scale data requires extensive computational resources. To eliminate these challenges, we present a novel distributed domain-aware spatiotemporal network that utilizes domain-specific knowledge with improved model performance. Our network consists of a pixel-contribution block, a distributed multiheaded multichannel convolutional (CNN) spatial block, and a recurrent temporal block. We choose flood prediction in hydrology as a use case to test our proposed method. From our analysis, the network effectively predicts high peaks in discharge measurements at watershed outlets with up to 4.1x speedup and increased prediction performance of up to 93\%. Our approach achieved a 12.6x overall speedup and increased the mean prediction performance by 16\%. We perform extensive experiments on a dataset of 23 watersheds in a northern state of the U.S. and present our findings.
Transfer Learning Approaches for Knowledge Discovery in Grid-based Geo-Spatiotemporal Data
Oct 02, 2021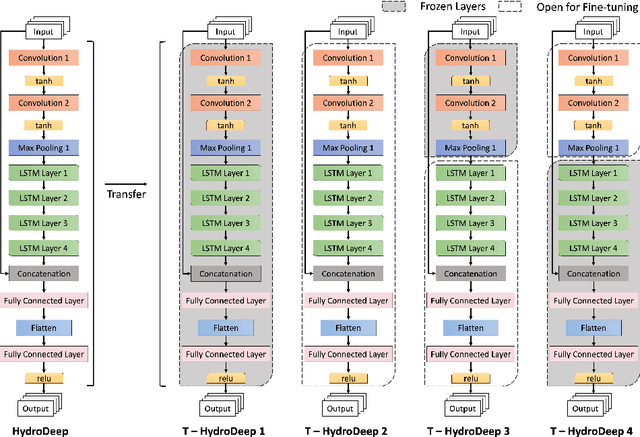
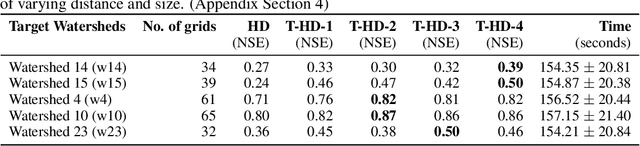
Extracting and meticulously analyzing geo-spatiotemporal features is crucial to recognize intricate underlying causes of natural events, such as floods. Limited evidence about hidden factors leading to climate change makes it challenging to predict regional water discharge accurately. In addition, the explosive growth in complex geo-spatiotemporal environment data that requires repeated learning by the state-of-the-art neural networks for every new region emphasizes the need for new computationally efficient methods, advanced computational resources, and extensive training on a massive amount of available monitored data. We, therefore, propose HydroDeep, an effectively reusable pretrained model to address this problem of transferring knowledge from one region to another by effectively capturing their intrinsic geo-spatiotemporal variance. Further, we present four transfer learning approaches on HydroDeep for spatiotemporal interpretability that improve Nash-Sutcliffe efficiency by 9% to 108% in new regions with a 95% reduction in time.
HydroDeep -- A Knowledge Guided Deep Neural Network for Geo-Spatiotemporal Data Analysis
Oct 09, 2020

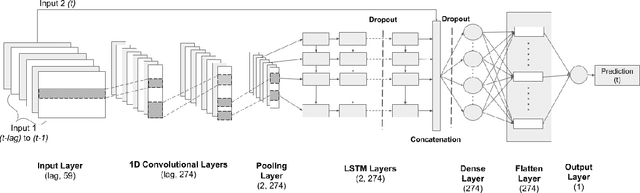
Floods are one of the major climate-related disasters, leading to substantial economic loss and social safety issue. However, the confidence in predicting changes in fluvial floods remains low due to limited evidence and complex causes of regional climate change. The recent development in machine learning techniques has the potential to improve traditional hydrological models by using monitoring data. Although Recurrent Neural Networks (RNN) perform remarkably with multivariate time series data, these models are blinded to the underlying mechanisms represented in a process-based model for flood prediction. While both process-based models and deep learning networks have their strength, understanding the fundamental mechanisms intrinsic to geo-spatiotemporal information is crucial to improve the prediction accuracy of flood occurrence. This paper demonstrates a neural network architecture (HydroDeep) that couples a process-based hydro-ecological model with a combination of Deep Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) Network to build a hybrid baseline model. HydroDeep outperforms the performance of both the independent networks by 4.8% and 31.8% respectively in Nash-Sutcliffe efficiency. A trained HydroDeep can transfer its knowledge and can learn the Geo-spatiotemporal features of any new region in minimal training iterations.