 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperSAM: Crafting a SAM Supernetwork via Structured Pruning and Unstructured Parameter Prioritization
Jan 15, 2025



Neural Architecture Search (NAS) is a powerful approach of automating the design of efficient neural architectures. In contrast to traditional NAS methods, recently proposed one-shot NAS methods prove to be more efficient in performing NAS. One-shot NAS works by generating a singular weight-sharing supernetwork that acts as a search space (container) of subnetworks. Despite its achievements, designing the one-shot search space remains a major challenge. In this work we propose a search space design strategy for Vision Transformer (ViT)-based architectures. In particular, we convert the Segment Anything Model (SAM) into a weight-sharing supernetwork called SuperSAM. Our approach involves automating the search space design via layer-wise structured pruning and parameter prioritization. While the structured pruning applies probabilistic removal of certain transformer layers, parameter prioritization performs weight reordering and slicing of MLP-blocks in the remaining layers. We train supernetworks on several datasets using the sandwich rule. For deployment, we enhance subnetwork discovery by utilizing a program autotuner to identify efficient subnetworks within the search space. The resulting subnetworks are 30-70% smaller in size compared to the original pre-trained SAM ViT-B, yet outperform the pretrained model. Our work introduces a new and effective method for ViT NAS search-space design.
MIREncoder: Multi-modal IR-based Pretrained Embeddings for Performance Optimizations
Jul 02, 2024One of the primary areas of interest in High Performance Computing is the improvement of performance of parallel workloads. Nowadays, compilable source code-based optimization tasks that employ deep learning often exploit LLVM Intermediate Representations (IRs) for extracting features from source code. Most such works target specific tasks, or are designed with a pre-defined set of heuristics. So far, pre-trained models are rare in this domain, but the possibilities have been widely discussed. Especially approaches mimicking large-language models (LLMs) have been proposed. But these have prohibitively large training costs. In this paper, we propose MIREncoder, a M}ulti-modal IR-based Auto-Encoder that can be pre-trained to generate a learned embedding space to be used for downstream tasks by machine learning-based approaches. A multi-modal approach enables us to better extract features from compilable programs. It allows us to better model code syntax, semantics and structure. For code-based performance optimizations, these features are very important while making optimization decisions. A pre-trained model/embedding implicitly enables the usage of transfer learning, and helps move away from task-specific trained models. Additionally, a pre-trained model used for downstream performance optimization should itself have reduced overhead, and be easily usable. These considerations have led us to propose a modeling approach that i) understands code semantics and structure, ii) enables use of transfer learning, and iii) is small and simple enough to be easily re-purposed or reused even with low resource availability. Our evaluations will show that our proposed approach can outperform the state of the art while reducing overhead.
The Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024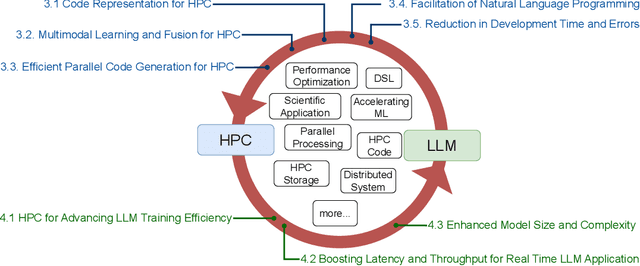

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
Performance Optimization using Multimodal Modeling and Heterogeneous GNN
Apr 27, 2023



Growing heterogeneity and configurability in HPC architectures has made auto-tuning applications and runtime parameters on these systems very complex. Users are presented with a multitude of options to configure parameters. In addition to application specific solutions, a common approach is to use general purpose search strategies, which often might not identify the best configurations or their time to convergence is a significant barrier. There is, thus, a need for a general purpose and efficient tuning approach that can be easily scaled and adapted to various tuning tasks. We propose a technique for tuning parallel code regions that is general enough to be adapted to multiple tasks. In this paper, we analyze IR-based programming models to make task-specific performance optimizations. To this end, we propose the Multimodal Graph Neural Network and Autoencoder (MGA) tuner, a multimodal deep learning based approach that adapts Heterogeneous Graph Neural Networks and Denoizing Autoencoders for modeling IR-based code representations that serve as separate modalities. This approach is used as part of our pipeline to model a syntax, semantics, and structure-aware IR-based code representation for tuning parallel code regions/kernels. We extensively experiment on OpenMP and OpenCL code regions/kernels obtained from PolyBench, Rodinia, STREAM, DataRaceBench, AMD SDK, NPB, NVIDIA SDK, Parboil, SHOC, and LULESH benchmarks. We apply our multimodal learning techniques to the tasks of i) optimizing the number of threads, scheduling policy and chunk size in OpenMP loops and, ii) identifying the best device for heterogeneous device mapping of OpenCL kernels. Our experiments show that this multimodal learning based approach outperforms the state-of-the-art in all experiments.
ParaGraph: Weighted Graph Representation for Performance Optimization of HPC Kernels
Apr 07, 2023GPU-based HPC clusters are attracting more scientific application developers due to their extensive parallelism and energy efficiency. In order to achieve portability among a variety of multi/many core architectures, a popular choice for an application developer is to utilize directive-based parallel programming models, such as OpenMP. However, even with OpenMP, the developer must choose from among many strategies for exploiting a GPU or a CPU. Recently, Machine Learning (ML) approaches have brought significant advances in the optimizations of HPC applications. To this end, several ways have been proposed to represent application characteristics for ML models. However, the available techniques fail to capture features that are crucial for exposing parallelism. In this paper, we introduce a new graph-based program representation for parallel applications that extends the Abstract Syntax Tree to represent control and data flow information. The originality of this work lies in the addition of new edges exploiting the implicit ordering and parent-child relationships in ASTs, as well as the introduction of edge weights to account for loop and condition information. We evaluate our proposed representation by training a Graph Neural Network (GNN) to predict the runtime of an OpenMP code region across CPUs and GPUs. Various transformations utilizing collapse and data transfer between the CPU and GPU are used to construct the dataset. The predicted runtime of the model is used to determine which transformation provides the best performance. Results show that our approach is indeed effective and has normalized RMSE as low as 0.004 to at most 0.01 in its runtime predictions.
Power Constrained Autotuning using Graph Neural Networks
Feb 22, 2023
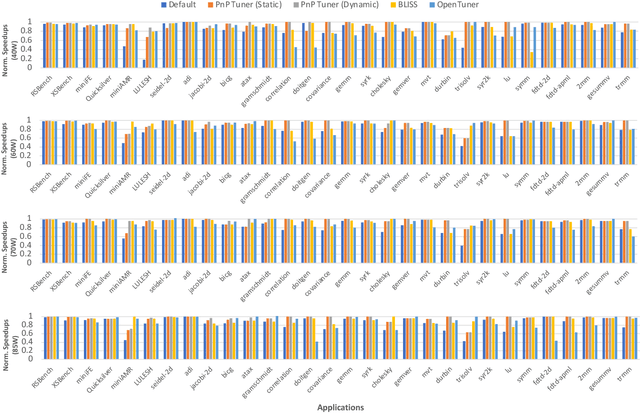
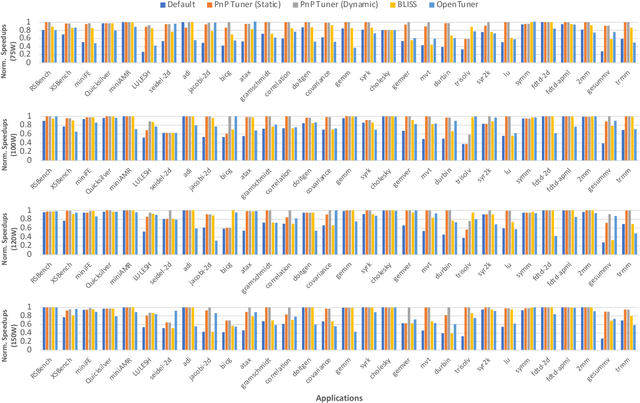
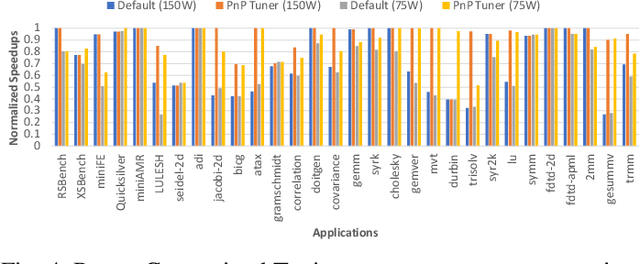
Recent advances in multi and many-core processors have led to significant improvements in the performance of scientific computing applications. However, the addition of a large number of complex cores have also increased the overall power consumption, and power has become a first-order design constraint in modern processors. While we can limit power consumption by simply applying software-based power constraints, applying them blindly will lead to non-trivial performance degradation. To address the challenge of improving the performance, power, and energy efficiency of scientific applications on modern multi-core processors, we propose a novel Graph Neural Network based auto-tuning approach that (i) optimizes runtime performance at pre-defined power constraints, and (ii) simultaneously optimizes for runtime performance and energy efficiency by minimizing the energy-delay product. The key idea behind this approach lies in modeling parallel code regions as flow-aware code graphs to capture both semantic and structural code features. We demonstrate the efficacy of our approach by conducting an extensive evaluation on $30$ benchmarks and proxy-/mini-applications with $68$ OpenMP code regions. Our approach identifies OpenMP configurations at different power constraints that yield a geometric mean performance improvement of more than $25\%$ and $13\%$ over the default OpenMP configuration on a 32-core Skylake and a $16$-core Haswell processor respectively. In addition, when we optimize for the energy-delay product, the OpenMP configurations selected by our auto-tuner demonstrate both performance improvement of $21\%$ and $11\%$ and energy reduction of $29\%$ and $18\%$ over the default OpenMP configuration at Thermal Design Power for the same Skylake and Haswell processors, respectively.
Learning Intermediate Representations using Graph Neural Networks for NUMA and Prefetchers Optimization
Mar 01, 2022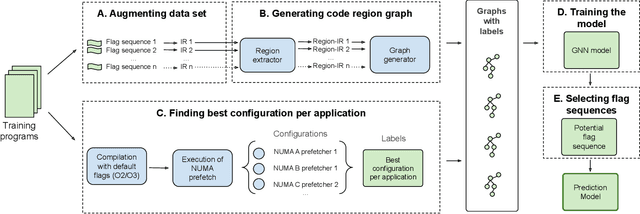
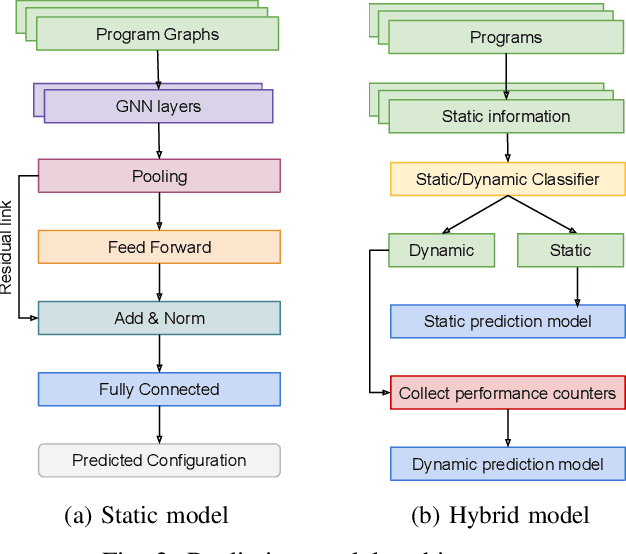
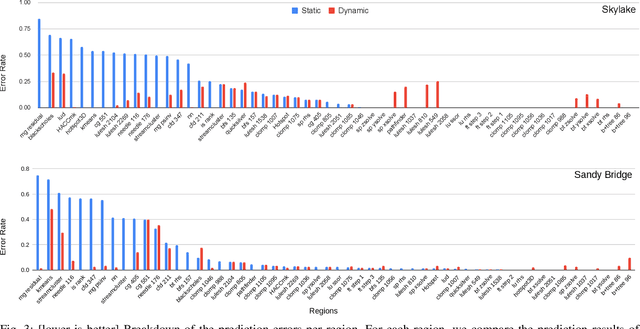
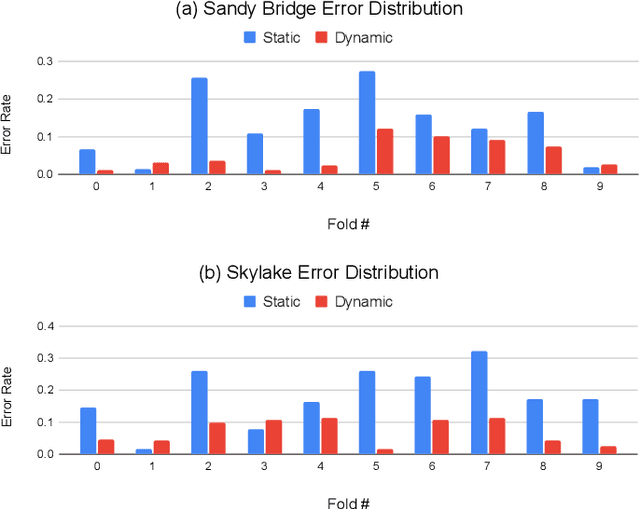
There is a large space of NUMA and hardware prefetcher configurations that can significantly impact the performance of an application. Previous studies have demonstrated how a model can automatically select configurations based on the dynamic properties of the code to achieve speedups. This paper demonstrates how the static Intermediate Representation (IR) of the code can guide NUMA/prefetcher optimizations without the prohibitive cost of performance profiling. We propose a method to create a comprehensive dataset that includes a diverse set of intermediate representations along with optimum configurations. We then apply a graph neural network model in order to validate this dataset. We show that our static intermediate representation based model achieves 80% of the performance gains provided by expensive dynamic performance profiling based strategies. We further develop a hybrid model that uses both static and dynamic information. Our hybrid model achieves the same gains as the dynamic models but at a reduced cost by only profiling 30% of the programs.