 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Constrained Autotuning using Graph Neural Networks
Feb 22, 2023
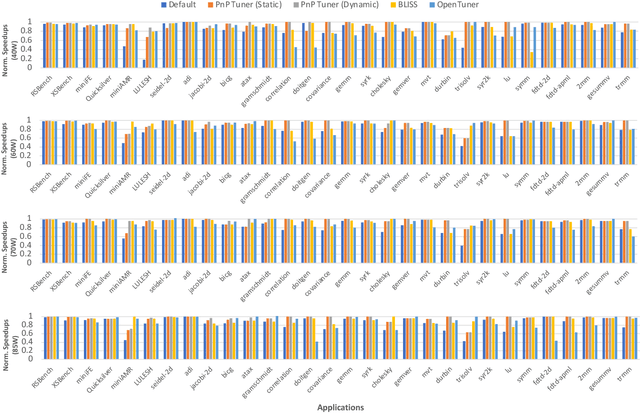
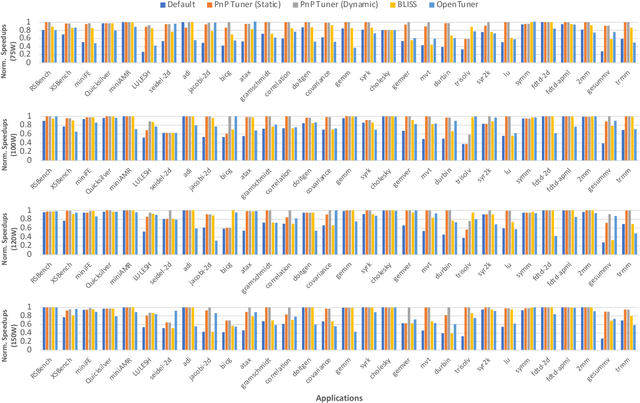
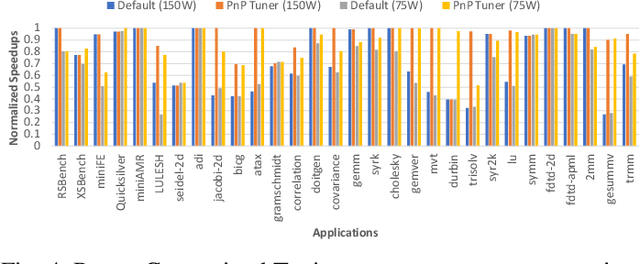
Recent advances in multi and many-core processors have led to significant improvements in the performance of scientific computing applications. However, the addition of a large number of complex cores have also increased the overall power consumption, and power has become a first-order design constraint in modern processors. While we can limit power consumption by simply applying software-based power constraints, applying them blindly will lead to non-trivial performance degradation. To address the challenge of improving the performance, power, and energy efficiency of scientific applications on modern multi-core processors, we propose a novel Graph Neural Network based auto-tuning approach that (i) optimizes runtime performance at pre-defined power constraints, and (ii) simultaneously optimizes for runtime performance and energy efficiency by minimizing the energy-delay product. The key idea behind this approach lies in modeling parallel code regions as flow-aware code graphs to capture both semantic and structural code features. We demonstrate the efficacy of our approach by conducting an extensive evaluation on $30$ benchmarks and proxy-/mini-applications with $68$ OpenMP code regions. Our approach identifies OpenMP configurations at different power constraints that yield a geometric mean performance improvement of more than $25\%$ and $13\%$ over the default OpenMP configuration on a 32-core Skylake and a $16$-core Haswell processor respectively. In addition, when we optimize for the energy-delay product, the OpenMP configurations selected by our auto-tuner demonstrate both performance improvement of $21\%$ and $11\%$ and energy reduction of $29\%$ and $18\%$ over the default OpenMP configuration at Thermal Design Power for the same Skylake and Haswell processors, respectively.