 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMPILOT: Harnessing Transformer Models for Auto Parallelization to Shared Memory Computing Paradigms
Nov 11, 2025Recent advances in large language models (LLMs) have significantly accelerated progress in code translation, enabling more accurate and efficient transformation across programming languages. While originally developed for natural language processing, LLMs have shown strong capabilities in modeling programming language syntax and semantics, outperforming traditional rule-based systems in both accuracy and flexibility. These models have streamlined cross-language conversion, reduced development overhead, and accelerated legacy code migration. In this paper, we introduce OMPILOT, a novel domain-specific encoder-decoder transformer tailored for translating C++ code into OpenMP, enabling effective shared-memory parallelization. OMPILOT leverages custom pre-training objectives that incorporate the semantics of parallel constructs and combines both unsupervised and supervised learning strategies to improve code translation robustness. Unlike previous work that focused primarily on loop-level transformations, OMPILOT operates at the function level to capture a wider semantic context. To evaluate our approach, we propose OMPBLEU, a novel composite metric specifically crafted to assess the correctness and quality of OpenMP parallel constructs, addressing limitations in conventional translation metrics.
CodeRosetta: Pushing the Boundaries of Unsupervised Code Translation for Parallel Programming
Oct 27, 2024



Recent advancements in Large Language Models (LLMs) have renewed interest in automatic programming language translation. Encoder-decoder transformer models, in particular, have shown promise in translating between different programming languages. However, translating between a language and its high-performance computing (HPC) extensions remains underexplored due to challenges such as complex parallel semantics. In this paper, we introduce CodeRosetta, an encoder-decoder transformer model designed specifically for translating between programming languages and their HPC extensions. CodeRosetta is evaluated on C++ to CUDA and Fortran to C++ translation tasks. It uses a customized learning framework with tailored pretraining and training objectives to effectively capture both code semantics and parallel structural nuances, enabling bidirectional translation. Our results show that CodeRosetta outperforms state-of-the-art baselines in C++ to CUDA translation by 2.9 BLEU and 1.72 CodeBLEU points while improving compilation accuracy by 6.05%. Compared to general closed-source LLMs, our method improves C++ to CUDA translation by 22.08 BLEU and 14.39 CodeBLEU, with 2.75% higher compilation accuracy. Finally, CodeRosetta exhibits proficiency in Fortran to parallel C++ translation, marking it, to our knowledge, as the first encoder-decoder model for this complex task, improving CodeBLEU by at least 4.63 points compared to closed-source and open-code LLMs.
AUTOPARLLM: GNN-Guided Automatic Code Parallelization using Large Language Models
Oct 09, 2023



Parallelizing sequentially written programs is a challenging task. Even experienced developers need to spend considerable time finding parallelism opportunities and then actually writing parallel versions of sequentially written programs. To address this issue, we present AUTOPARLLM, a framework for automatically discovering parallelism and generating the parallel version of the sequentially written program. Our framework consists of two major components: i) a heterogeneous Graph Neural Network (GNN) based parallelism discovery and parallel pattern detection module, and ii) an LLM-based code generator to generate the parallel counterpart of the sequential programs. We use the GNN to learn the flow-aware characteristics of the programs to identify parallel regions in sequential programs and then construct an enhanced prompt using the GNN's results for the LLM-based generator to finally produce the parallel counterparts of the sequential programs. We evaluate AUTOPARLLM on 11 applications of 2 well-known benchmark suites: NAS Parallel Benchmark and Rodinia Benchmark. Our results show that AUTOPARLLM is indeed effective in improving the state-of-the-art LLM-based models for the task of parallel code generation in terms of multiple code generation metrics. AUTOPARLLM also improves the average runtime of the parallel code generated by the state-of-the-art LLMs by as high as 3.4% and 2.9% for the NAS Parallel Benchmark and Rodinia Benchmark respectively. Additionally, to overcome the issue that well-known metrics for translation evaluation have not been optimized to evaluate the quality of the generated parallel code, we propose OMPScore for evaluating the quality of the generated code. We show that OMPScore exhibits a better correlation with human judgment than existing metrics, measured by up to 75% improvement of Spearman correlation.
PERFOGRAPH: A Numerical Aware Program Graph Representation for Performance Optimization and Program Analysis
May 31, 2023



The remarkable growth and significant success of machine learning have expanded its applications into programming languages and program analysis. However, a key challenge in adopting the latest machine learning methods is the representation of programming languages, which directly impacts the ability of machine learning methods to reason about programs. The absence of numerical awareness, composite data structure information, and improper way of presenting variables in previous representation works have limited their performances. To overcome the limitations and challenges of current program representations, we propose a novel graph-based program representation called PERFOGRAPH. PERFOGRAPH can capture numerical information and the composite data structure by introducing new nodes and edges. Furthermore, we propose an adapted embedding method to incorporate numerical awareness. These enhancements make PERFOGRAPH a highly flexible and scalable representation that can effectively capture program intricate dependencies and semantics. Consequently, it serves as a powerful tool for various applications such as program analysis, performance optimization, and parallelism discovery. Our experimental results demonstrate that PERFOGRAPH outperforms existing representations and sets new state-of-the-art results by reducing the error rate by 7.4% (AMD dataset) and 10% (NVIDIA dataset) in the well-known Device Mapping challenge. It also sets new state-of-the-art results in various performance optimization tasks like Parallelism Discovery and Numa and Prefetchers Configuration prediction.
Performance Optimization using Multimodal Modeling and Heterogeneous GNN
Apr 27, 2023



Growing heterogeneity and configurability in HPC architectures has made auto-tuning applications and runtime parameters on these systems very complex. Users are presented with a multitude of options to configure parameters. In addition to application specific solutions, a common approach is to use general purpose search strategies, which often might not identify the best configurations or their time to convergence is a significant barrier. There is, thus, a need for a general purpose and efficient tuning approach that can be easily scaled and adapted to various tuning tasks. We propose a technique for tuning parallel code regions that is general enough to be adapted to multiple tasks. In this paper, we analyze IR-based programming models to make task-specific performance optimizations. To this end, we propose the Multimodal Graph Neural Network and Autoencoder (MGA) tuner, a multimodal deep learning based approach that adapts Heterogeneous Graph Neural Networks and Denoizing Autoencoders for modeling IR-based code representations that serve as separate modalities. This approach is used as part of our pipeline to model a syntax, semantics, and structure-aware IR-based code representation for tuning parallel code regions/kernels. We extensively experiment on OpenMP and OpenCL code regions/kernels obtained from PolyBench, Rodinia, STREAM, DataRaceBench, AMD SDK, NPB, NVIDIA SDK, Parboil, SHOC, and LULESH benchmarks. We apply our multimodal learning techniques to the tasks of i) optimizing the number of threads, scheduling policy and chunk size in OpenMP loops and, ii) identifying the best device for heterogeneous device mapping of OpenCL kernels. Our experiments show that this multimodal learning based approach outperforms the state-of-the-art in all experiments.
ParaGraph: Weighted Graph Representation for Performance Optimization of HPC Kernels
Apr 07, 2023

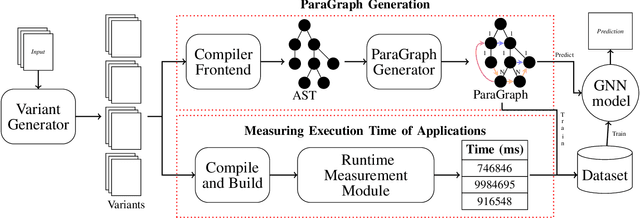

GPU-based HPC clusters are attracting more scientific application developers due to their extensive parallelism and energy efficiency. In order to achieve portability among a variety of multi/many core architectures, a popular choice for an application developer is to utilize directive-based parallel programming models, such as OpenMP. However, even with OpenMP, the developer must choose from among many strategies for exploiting a GPU or a CPU. Recently, Machine Learning (ML) approaches have brought significant advances in the optimizations of HPC applications. To this end, several ways have been proposed to represent application characteristics for ML models. However, the available techniques fail to capture features that are crucial for exposing parallelism. In this paper, we introduce a new graph-based program representation for parallel applications that extends the Abstract Syntax Tree to represent control and data flow information. The originality of this work lies in the addition of new edges exploiting the implicit ordering and parent-child relationships in ASTs, as well as the introduction of edge weights to account for loop and condition information. We evaluate our proposed representation by training a Graph Neural Network (GNN) to predict the runtime of an OpenMP code region across CPUs and GPUs. Various transformations utilizing collapse and data transfer between the CPU and GPU are used to construct the dataset. The predicted runtime of the model is used to determine which transformation provides the best performance. Results show that our approach is indeed effective and has normalized RMSE as low as 0.004 to at most 0.01 in its runtime predictions.
Learning Intermediate Representations using Graph Neural Networks for NUMA and Prefetchers Optimization
Mar 01, 2022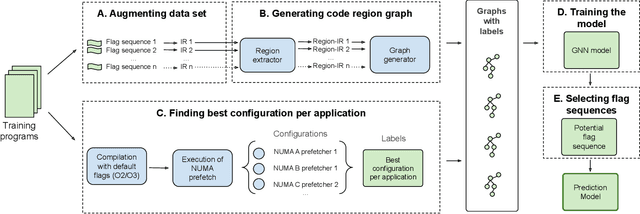
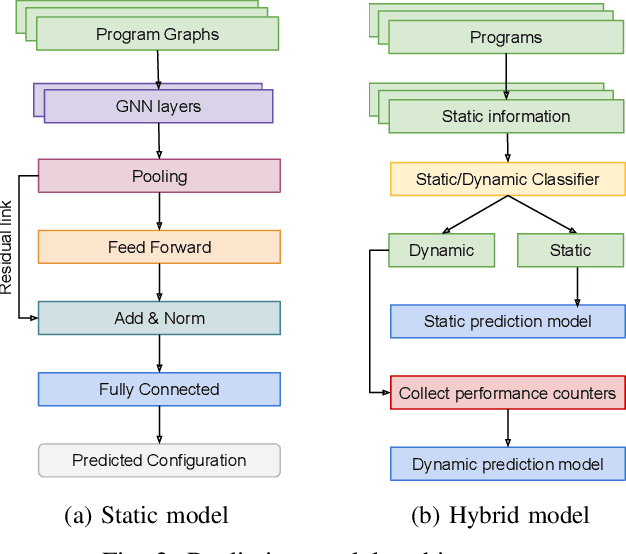
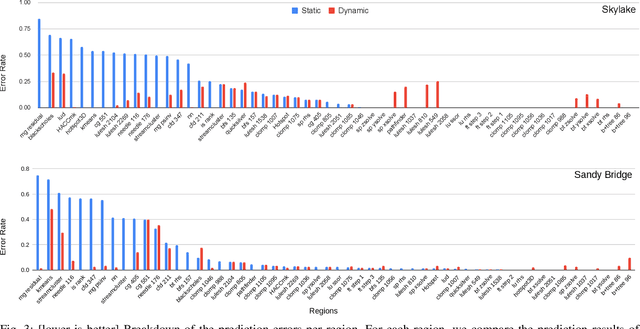
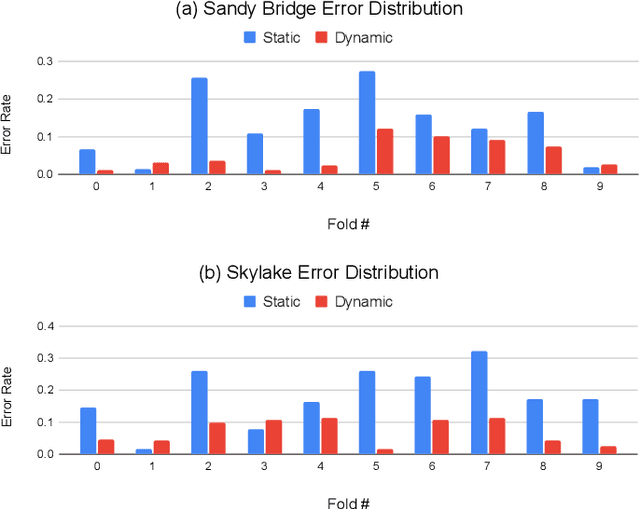
There is a large space of NUMA and hardware prefetcher configurations that can significantly impact the performance of an application. Previous studies have demonstrated how a model can automatically select configurations based on the dynamic properties of the code to achieve speedups. This paper demonstrates how the static Intermediate Representation (IR) of the code can guide NUMA/prefetcher optimizations without the prohibitive cost of performance profiling. We propose a method to create a comprehensive dataset that includes a diverse set of intermediate representations along with optimum configurations. We then apply a graph neural network model in order to validate this dataset. We show that our static intermediate representation based model achieves 80% of the performance gains provided by expensive dynamic performance profiling based strategies. We further develop a hybrid model that uses both static and dynamic information. Our hybrid model achieves the same gains as the dynamic models but at a reduced cost by only profiling 30% of the programs.