 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-Resident Inverted File Index for Streaming Vector Databases
Jan 16, 2026Vector search has emerged as the computational backbone of modern AI infrastructure, powering critical systems ranging from Vector Databases to Retrieval-Augmented Generation (RAG). While the GPU-accelerated Inverted File (IVF) index acts as one of the most widely used techniques for these large-scale workloads due to its memory efficiency, its traditional architecture remains fundamentally static. Existing designs rely on rigid and contiguous memory layouts that lack native support for in-place mutation, creating a severe bottleneck for streaming scenarios. In applications requiring real-time knowledge updates, such as live recommendation engines or dynamic RAG systems, maintaining index freshness necessitates expensive CPU-GPU roundtrips that cause system latency to spike from milliseconds to seconds. In this paper, we propose SIVF (Streaming Inverted File), a new GPU-native architecture designed to empower vector databases with high-velocity data ingestion and deletion capabilities. SIVF replaces the static memory layout with a slab-based allocation system and a validity bitmap, enabling lock-free and in-place mutation directly in VRAM. We further introduce a GPU-resident address translation table (ATT) to resolve the overhead of locating vectors, providing $O(1)$ access to physical storage slots. We evaluate SIVF against the industry-standard GPU IVF implementation on the SIFT1M and GIST1M datasets. Microbenchmarks demonstrate that SIVF reduces deletion latency by up to $13,300\times$ (from 11.8 seconds to 0.89 ms on GIST1M) and improves ingestion throughput by $36\times$ to $105\times$. In end-to-end sliding window scenarios, SIVF eliminates system freezes and achieves a $161\times$ to $266\times$ speedup with single-digit millisecond latency. Notably, this performance incurs negligible storage penalty, maintaining less than 0.8\% memory overhead compared to static indices.
MCGI: Manifold-Consistent Graph Indexing for Billion-Scale Disk-Resident Vector Search
Jan 05, 2026Graph-based Approximate Nearest Neighbor (ANN) search often suffers from performance degradation in high-dimensional spaces due to the ``Euclidean-Geodesic mismatch,'' where greedy routing diverges from the underlying data manifold. To address this, we propose Manifold-Consistent Graph Indexing (MCGI), a geometry-aware and disk-resident indexing method that leverages Local Intrinsic Dimensionality (LID) to dynamically adapt search strategies to the data's intrinsic geometry. Unlike standard algorithms that treat dimensions uniformly, MCGI modulates its beam search budget based on in situ geometric analysis, eliminating dependency on static hyperparameters. Theoretical analysis confirms that MCGI enables improved approximation guarantees by preserving manifold-consistent topological connectivity. Empirically, MCGI achieves 5.8$\times$ higher throughput at 95\% recall on high-dimensional GIST1M compared to state-of-the-art DiskANN. On the billion-scale SIFT1B dataset, MCGI further validates its scalability by reducing high-recall query latency by 3$\times$, while maintaining performance parity on standard lower-dimensional datasets.
IPBA: Imperceptible Perturbation Backdoor Attack in Federated Self-Supervised Learning
Aug 11, 2025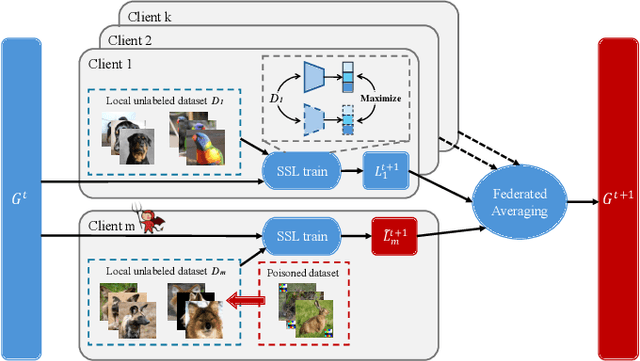
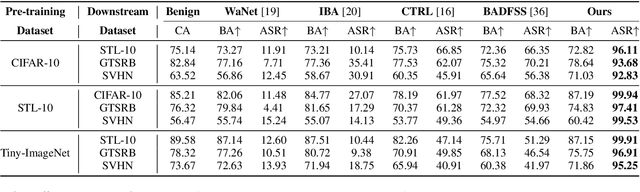

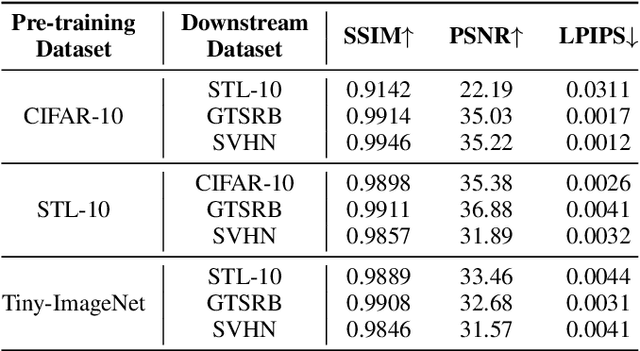
Federated self-supervised learning (FSSL) combines the advantages of decentralized modeling and unlabeled representation learning, serving as a cutting-edge paradigm with strong potential for scalability and privacy preservation. Although FSSL has garnered increasing attention, research indicates that it remains vulnerable to backdoor attacks. Existing methods generally rely on visually obvious triggers, which makes it difficult to meet the requirements for stealth and practicality in real-world deployment. In this paper, we propose an imperceptible and effective backdoor attack method against FSSL, called IPBA. Our empirical study reveals that existing imperceptible triggers face a series of challenges in FSSL, particularly limited transferability, feature entanglement with augmented samples, and out-of-distribution properties. These issues collectively undermine the effectiveness and stealthiness of traditional backdoor attacks in FSSL. To overcome these challenges, IPBA decouples the feature distributions of backdoor and augmented samples, and introduces Sliced-Wasserstein distance to mitigate the out-of-distribution properties of backdoor samples, thereby optimizing the trigger generation process. Our experimental results on several FSSL scenarios and datasets show that IPBA significantly outperforms existing backdoor attack methods in performance and exhibits strong robustness under various defense mechanisms.
Balancing Privacy and Efficiency: Music Information Retrieval via Additive Homomorphic Encryption
Aug 09, 2025In the era of generative AI, ensuring the privacy of music data presents unique challenges: unlike static artworks such as images, music data is inherently temporal and multimodal, and it is sampled, transformed, and remixed at an unprecedented scale. These characteristics make its core vector embeddings, i.e, the numerical representations of the music, highly susceptible to being learned, misused, or even stolen by models without accessing the original audio files. Traditional methods like copyright licensing and digital watermarking offer limited protection for these abstract mathematical representations, thus necessitating a stronger, e.g., cryptographic, approach to safeguarding the embeddings themselves. Standard encryption schemes, such as AES, render data unintelligible for computation, making such searches impossible. While Fully Homomorphic Encryption (FHE) provides a plausible solution by allowing arbitrary computations on ciphertexts, its substantial performance overhead remains impractical for large-scale vector similarity searches. Given this trade-off, we propose a more practical approach using Additive Homomorphic Encryption (AHE) for vector similarity search. The primary contributions of this paper are threefold: we analyze threat models unique to music information retrieval systems; we provide a theoretical analysis and propose an efficient AHE-based solution through inner products of music embeddings to deliver privacy-preserving similarity search; and finally, we demonstrate the efficiency and practicality of the proposed approach through empirical evaluation and comparison to FHE schemes on real-world MP3 files.
MPAD: A New Dimension-Reduction Method for Preserving Nearest Neighbors in High-Dimensional Vector Search
Apr 23, 2025
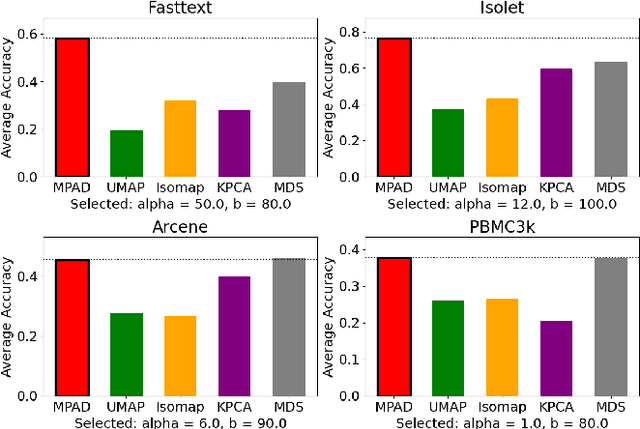


High-dimensional vector embeddings are widely used in retrieval systems, yet dimensionality reduction (DR) is seldom applied due to its tendency to distort nearest-neighbor (NN) structure critical for search. Existing DR techniques such as PCA and UMAP optimize global or manifold-preserving criteria, rather than retrieval-specific objectives. We present MPAD: Maximum Pairwise Absolute Difference, an unsupervised DR method that explicitly preserves approximate NN relations by maximizing the margin between k-NNs and non-k-NNs under a soft orthogonality constraint. This design enables MPAD to retain ANN-relevant geometry without supervision or changes to the original embedding model. Experiments across multiple domains show that MPAD consistently outperforms standard DR methods in preserving neighborhood structure, enabling more accurate search in reduced dimensions.
Nemesis: Noise-randomized Encryption with Modular Efficiency and Secure Integration in Machine Learning Systems
Dec 18, 2024



Machine learning (ML) systems that guarantee security and privacy often rely on Fully Homomorphic Encryption (FHE) as a cornerstone technique, enabling computations on encrypted data without exposing sensitive information. However, a critical limitation of FHE is its computational inefficiency, making it impractical for large-scale applications. In this work, we propose \textit{Nemesis}, a framework that accelerates FHE-based systems without compromising accuracy or security. The design of Nemesis is inspired by Rache (SIGMOD'23), which introduced a caching mechanism for encrypted integers and scalars. Nemesis extends this idea with more advanced caching techniques and mathematical tools, enabling efficient operations over multi-slot FHE schemes and overcoming Rache's limitations to support general plaintext structures. We formally prove the security of Nemesis under standard cryptographic assumptions and evaluate its performance extensively on widely used datasets, including MNIST, FashionMNIST, and CIFAR-10. Experimental results show that Nemesis significantly reduces the computational overhead of FHE-based ML systems, paving the way for broader adoption of privacy-preserving technologies.
Ares: Approximate Representations via Efficient Sparsification -- A Stateless Approach through Polynomial Homomorphism
Dec 14, 2024



The increasing prevalence of high-dimensional data demands efficient and scalable compression methods to support modern applications. However, existing techniques like PCA and Autoencoders often rely on auxiliary metadata or intricate architectures, limiting their practicality for streaming or infinite datasets. In this paper, we introduce a stateless compression framework that leverages polynomial representations to achieve compact, interpretable, and scalable data reduction. By eliminating the need for auxiliary data, our method supports direct algebraic operations in the compressed domain while minimizing error growth during computations. Through extensive experiments on synthetic and real-world datasets, we show that our approach achieves high compression ratios without compromising reconstruction accuracy, all while maintaining simplicity and scalability.
Approximate Fiber Product: A Preliminary Algebraic-Geometric Perspective on Multimodal Embedding Alignment
Nov 30, 2024Multimodal tasks, such as image-text retrieval and generation, require embedding data from diverse modalities into a shared representation space. Aligning embeddings from heterogeneous sources while preserving shared and modality-specific information is a fundamental challenge. This paper provides an initial attempt to integrate algebraic geometry into multimodal representation learning, offering a foundational perspective for further exploration. We model image and text data as polynomials over discrete rings, \( \mathbb{Z}_{256}[x] \) and \( \mathbb{Z}_{|V|}[x] \), respectively, enabling the use of algebraic tools like fiber products to analyze alignment properties. To accommodate real-world variability, we extend the classical fiber product to an approximate fiber product with a tolerance parameter \( \epsilon \), balancing precision and noise tolerance. We study its dependence on \( \epsilon \), revealing asymptotic behavior, robustness to perturbations, and sensitivity to embedding dimensionality. Additionally, we propose a decomposition of the shared embedding space into orthogonal subspaces, \( Z = Z_s \oplus Z_I \oplus Z_T \), where \( Z_s \) captures shared semantics, and \( Z_I \), \( Z_T \) encode modality-specific features. This decomposition is geometrically interpreted via manifolds and fiber bundles, offering insights into embedding structure and optimization. This framework establishes a principled foundation for analyzing multimodal alignment, uncovering connections between robustness, dimensionality allocation, and algebraic structure. It lays the groundwork for further research on embedding spaces in multimodal learning using algebraic geometry.
NexusIndex: Integrating Advanced Vector Indexing and Multi-Model Embeddings for Robust Fake News Detection
Oct 23, 2024



The proliferation of fake news on digital platforms has underscored the need for robust and scalable detection mechanisms. Traditional methods often fall short in handling large and diverse datasets due to limitations in scalability and accuracy. In this paper, we propose NexusIndex, a novel framework and model that enhances fake news detection by integrating advanced language models, an innovative FAISSNexusIndex layer, and attention mechanisms. Our approach leverages multi-model embeddings to capture rich contextual and semantic nuances, significantly improving text interpretation and classification accuracy. By transforming articles into high-dimensional embeddings and indexing them efficiently, NexusIndex facilitates rapid similarity searches across extensive collections of news articles. The FAISSNexusIndex layer further optimizes this process, enabling real-time detection and enhancing the system's scalability and performance. Our experimental results demonstrate that NexusIndex outperforms state-of-the-art methods in efficiency and accuracy across diverse datasets.
VecLSTM: Trajectory Data Processing and Management for Activity Recognition through LSTM Vectorization and Database Integration
Sep 28, 2024



Activity recognition is a challenging task due to the large scale of trajectory data and the need for prompt and efficient processing. Existing methods have attempted to mitigate this problem by employing traditional LSTM architectures, but these approaches often suffer from inefficiencies in processing large datasets. In response to this challenge, we propose VecLSTM, a novel framework that enhances the performance and efficiency of LSTM-based neural networks. Unlike conventional approaches, VecLSTM incorporates vectorization layers, leveraging optimized mathematical operations to process input sequences more efficiently. We have implemented VecLSTM and incorporated it into the MySQL database. To evaluate the effectiveness of VecLSTM, we compare its performance against a conventional LSTM model using a dataset comprising 1,467,652 samples with seven unique labels. Experimental results demonstrate superior accuracy and efficiency compared to the state-of-the-art, with VecLSTM achieving a validation accuracy of 85.57\%, a test accuracy of 85.47\%, and a weighted F1-score of 0.86. Furthermore, VecLSTM significantly reduces training time, offering a 26.2\% reduction compared to traditional LSTM models.