 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMR-GRPO: Accelerating GRPO-Style Training through Diversity-Aware Reward Reweighting
Jan 14, 2026Group Relative Policy Optimization (GRPO) has become a standard approach for training mathematical reasoning models; however, its reliance on multiple completions per prompt makes training computationally expensive. Although recent work has reduced the number of training steps required to reach peak performance, the overall wall-clock training time often remains unchanged or even increases due to higher per-step cost. We propose MMR-GRPO, which integrates Maximal Marginal Relevance to reweigh rewards based on completion diversity. Our key insight is that semantically redundant completions contribute limited marginal learning signal; prioritizing diverse solutions yields more informative updates and accelerates convergence. Extensive evaluations across three model sizes (1.5B, 7B, 8B), three GRPO variants, and five mathematical reasoning benchmarks show that MMR-GRPO achieves comparable peak performance while requiring on average 47.9% fewer training steps and 70.2% less wall-clock time. These gains are consistent across models, methods, and benchmarks. We will release our code, trained models, and experimental protocols.
Mitigating Gender Bias via Fostering Exploratory Thinking in LLMs
May 22, 2025Large Language Models (LLMs) often exhibit gender bias, resulting in unequal treatment of male and female subjects across different contexts. To address this issue, we propose a novel data generation framework that fosters exploratory thinking in LLMs. Our approach prompts models to generate story pairs featuring male and female protagonists in structurally identical, morally ambiguous scenarios, then elicits and compares their moral judgments. When inconsistencies arise, the model is guided to produce balanced, gender-neutral judgments. These story-judgment pairs are used to fine-tune or optimize the models via Direct Preference Optimization (DPO). Experimental results show that our method significantly reduces gender bias while preserving or even enhancing general model capabilities. We will release the code and generated data.
CliME: Evaluating Multimodal Climate Discourse on Social Media and the Climate Alignment Quotient (CAQ)
Apr 04, 2025
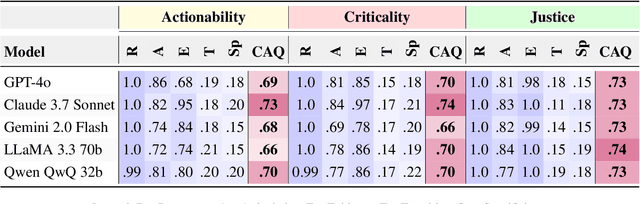
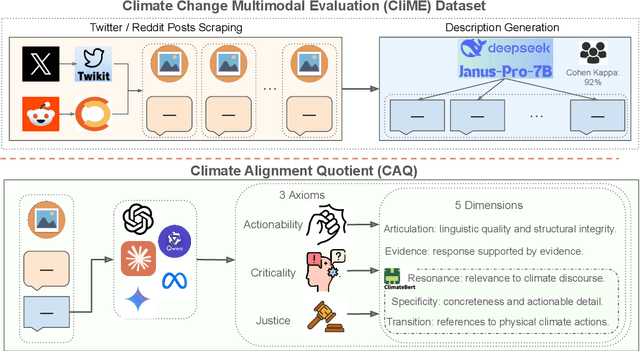

The rise of Large Language Models (LLMs) has raised questions about their ability to understand climate-related contexts. Though climate change dominates social media, analyzing its multimodal expressions is understudied, and current tools have failed to determine whether LLMs amplify credible solutions or spread unsubstantiated claims. To address this, we introduce CliME (Climate Change Multimodal Evaluation), a first-of-its-kind multimodal dataset, comprising 2579 Twitter and Reddit posts. The benchmark features a diverse collection of humorous memes and skeptical posts, capturing how these formats distill complex issues into viral narratives that shape public opinion and policy discussions. To systematically evaluate LLM performance, we present the Climate Alignment Quotient (CAQ), a novel metric comprising five distinct dimensions: Articulation, Evidence, Resonance, Transition, and Specificity. Additionally, we propose three analytical lenses: Actionability, Criticality, and Justice, to guide the assessment of LLM-generated climate discourse using CAQ. Our findings, based on the CAQ metric, indicate that while most evaluated LLMs perform relatively well in Criticality and Justice, they consistently underperform on the Actionability axis. Among the models evaluated, Claude 3.7 Sonnet achieves the highest overall performance. We publicly release our CliME dataset and code to foster further research in this domain.
LegalCore: A Dataset for Legal Documents Event Coreference Resolution
Feb 18, 2025Recognizing events and their coreferential mentions in a document is essential for understanding semantic meanings of text. The existing research on event coreference resolution is mostly limited to news articles. In this paper, we present the first dataset for the legal domain, LegalCore, which has been annotated with comprehensive event and event coreference information. The legal contract documents we annotated in this dataset are several times longer than news articles, with an average length of around 25k tokens per document. The annotations show that legal documents have dense event mentions and feature both short-distance and super long-distance coreference links between event mentions. We further benchmark mainstream Large Language Models (LLMs) on this dataset for both event detection and event coreference resolution tasks, and find that this dataset poses significant challenges for state-of-the-art open-source and proprietary LLMs, which perform significantly worse than a supervised baseline. We will publish the dataset as well as the code.
UAL-Bench: The First Comprehensive Unusual Activity Localization Benchmark
Oct 02, 2024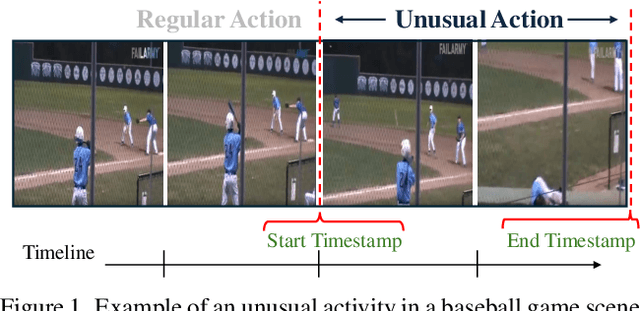
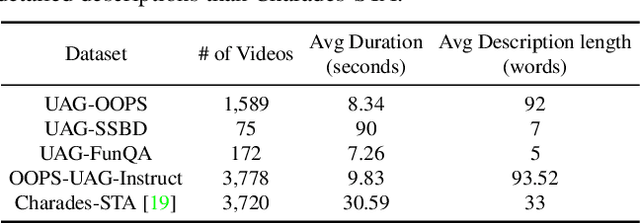
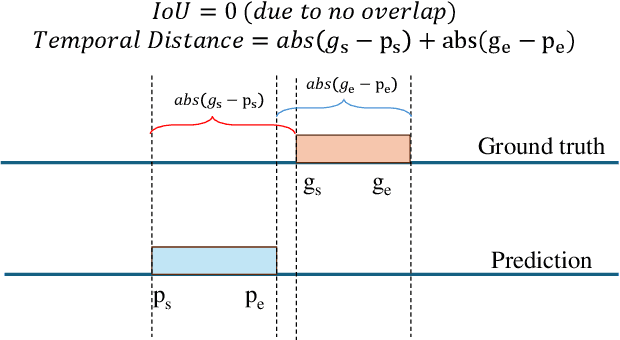
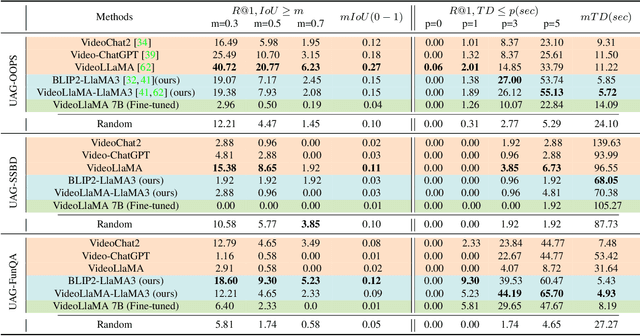
Localizing unusual activities, such as human errors or surveillance incidents, in videos holds practical significance. However, current video understanding models struggle with localizing these unusual events likely because of their insufficient representation in models' pretraining datasets. To explore foundation models' capability in localizing unusual activity, we introduce UAL-Bench, a comprehensive benchmark for unusual activity localization, featuring three video datasets: UAG-OOPS, UAG-SSBD, UAG-FunQA, and an instruction-tune dataset: OOPS-UAG-Instruct, to improve model capabilities. UAL-Bench evaluates three approaches: Video-Language Models (Vid-LLMs), instruction-tuned Vid-LLMs, and a novel integration of Vision-Language Models and Large Language Models (VLM-LLM). Our results show the VLM-LLM approach excels in localizing short-span unusual events and predicting their onset (start time) more accurately than Vid-LLMs. We also propose a new metric, R@1, TD <= p, to address limitations in existing evaluation methods. Our findings highlight the challenges posed by long-duration videos, particularly in autism diagnosis scenarios, and the need for further advancements in localization techniques. Our work not only provides a benchmark for unusual activity localization but also outlines the key challenges for existing foundation models, suggesting future research directions on this important task.
Are LLMs Good Annotators for Discourse-level Event Relation Extraction?
Jul 28, 2024



Large Language Models (LLMs) have demonstrated proficiency in a wide array of natural language processing tasks. However, its effectiveness over discourse-level event relation extraction (ERE) tasks remains unexplored. In this paper, we assess the effectiveness of LLMs in addressing discourse-level ERE tasks characterized by lengthy documents and intricate relations encompassing coreference, temporal, causal, and subevent types. Evaluation is conducted using an commercial model, GPT-3.5, and an open-source model, LLaMA-2. Our study reveals a notable underperformance of LLMs compared to the baseline established through supervised learning. Although Supervised Fine-Tuning (SFT) can improve LLMs performance, it does not scale well compared to the smaller supervised baseline model. Our quantitative and qualitative analysis shows that LLMs have several weaknesses when applied for extracting event relations, including a tendency to fabricate event mentions, and failures to capture transitivity rules among relations, detect long distance relations, or comprehend contexts with dense event mentions.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024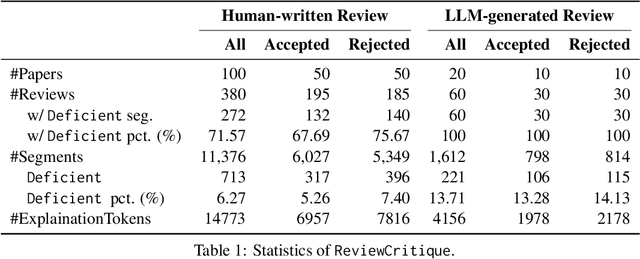
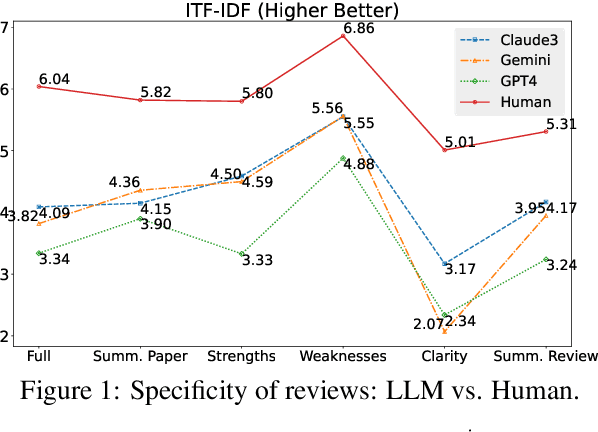

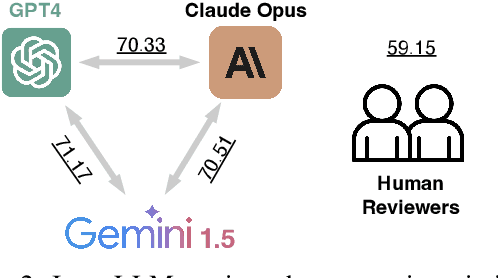
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
Leveraging Multiple Teachers for Test-Time Adaptation of Language-Guided Classifiers
Nov 13, 2023Recent approaches have explored language-guided classifiers capable of classifying examples from novel tasks when provided with task-specific natural language explanations, instructions or prompts (Sanh et al., 2022; R. Menon et al., 2022). While these classifiers can generalize in zero-shot settings, their task performance often varies substantially between different language explanations in unpredictable ways (Lu et al., 2022; Gonen et al., 2022). Also, current approaches fail to leverage unlabeled examples that may be available in many scenarios. Here, we introduce TALC, a framework that uses data programming to adapt a language-guided classifier for a new task during inference when provided with explanations from multiple teachers and unlabeled test examples. Our results show that TALC consistently outperforms a competitive baseline from prior work by an impressive 9.3% (relative improvement). Further, we demonstrate the robustness of TALC to variations in the quality and quantity of provided explanations, highlighting its potential in scenarios where learning from multiple teachers or a crowd is involved. Our code is available at: https://github.com/WeiKangda/TALC.git.
When Do Decompositions Help for Machine Reading?
Dec 20, 2022Answering complex questions often requires multi-step reasoning in order to obtain the final answer. Most research into decompositions of complex questions involves open-domain systems, which have shown success in using these decompositions for improved retrieval. In the machine reading setting, however, work to understand when decompositions are helpful is understudied. We conduct experiments on decompositions in machine reading to unify recent work in this space, using a range of models and datasets. We find that decompositions can be helpful in the few-shot case, giving several points of improvement in exact match scores. However, we also show that when models are given access to datasets with around a few hundred or more examples, decompositions are not helpful (and can actually be detrimental). Thus, our analysis implies that models can learn decompositions implicitly even with limited data.