 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Imbalance in Direct Preference Optimization
Paper and Code
Feb 28, 2025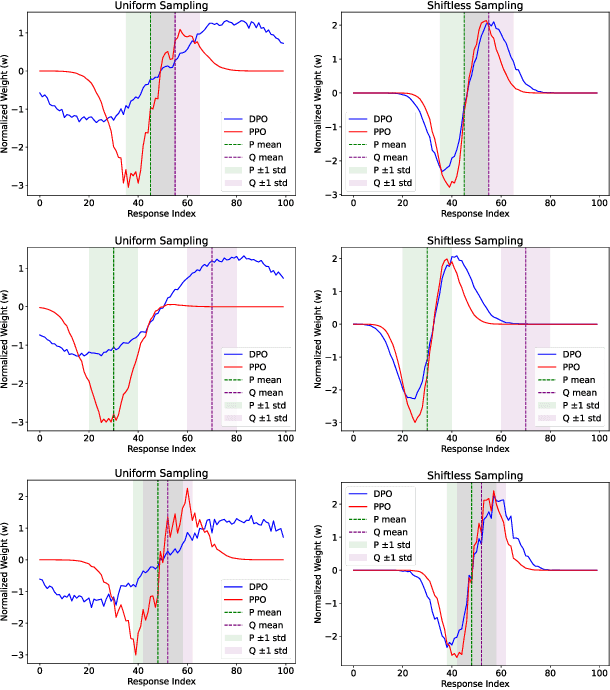
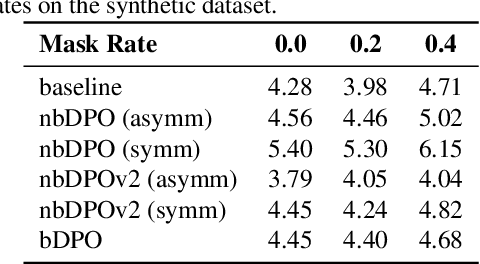
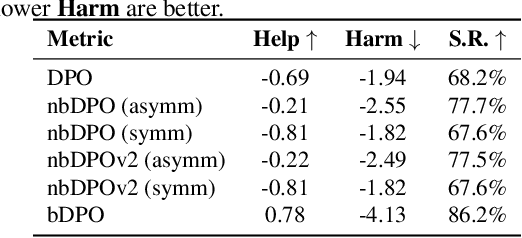
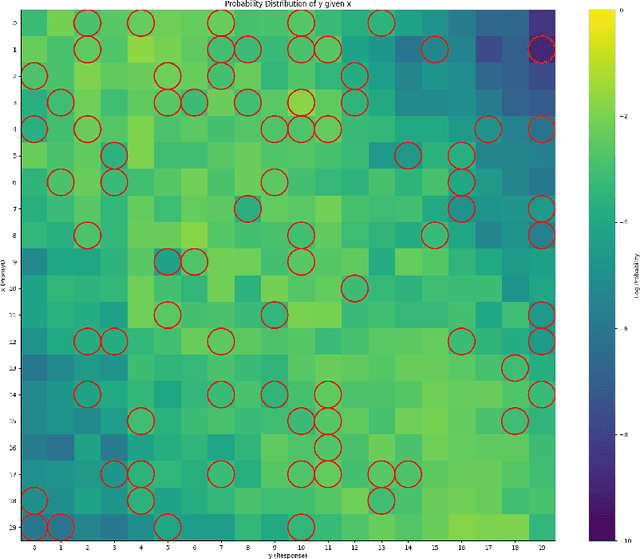
Direct Preference Optimization (DPO) has been proposed as a promising alternative to Proximal Policy Optimization (PPO) based Reinforcement Learning with Human Feedback (RLHF). However, empirical evaluations consistently reveal suboptimal performance in DPO compared to common RLHF pipelines. In this work, we conduct a systematic analysis of DPO's training dynamics and identify gradient imbalance as a critical limitation. We demonstrate theoretically and empirically that this imbalance perturbs optimization trajectories, destabilizes learning, and induces suboptimal convergence. To address this issue, we propose Balanced-DPO, a simple yet effective modification to the DPO objective that introduces a computationally efficient gradient reweighting mechanism. Our experiments demonstrate the effectiveness of Balanced-DPO, validating the theoretical findings and confirming that addressing gradient imbalance is key to improving DPO's performance, highlighting a promising direction for future research.