 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionBlocks: Blockwise Training for Generative Models via Score-Based Diffusion
Jun 17, 2025Training large neural networks with end-to-end backpropagation creates significant memory bottlenecks, limiting accessibility to state-of-the-art AI research. We propose $\textit{DiffusionBlocks}$, a novel training framework that interprets neural network blocks as performing denoising operations in a continuous-time diffusion process. By partitioning the network into independently trainable blocks and optimizing noise level assignments based on equal cumulative probability mass, our approach achieves significant memory efficiency while maintaining competitive performance compared to traditional backpropagation in generative tasks. Experiments on image generation and language modeling tasks demonstrate memory reduction proportional to the number of blocks while achieving superior performance. DiffusionBlocks provides a promising pathway for democratizing access to large-scale neural network training with limited computational resources.
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
Jan 29, 2025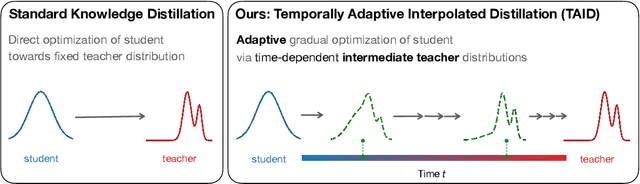
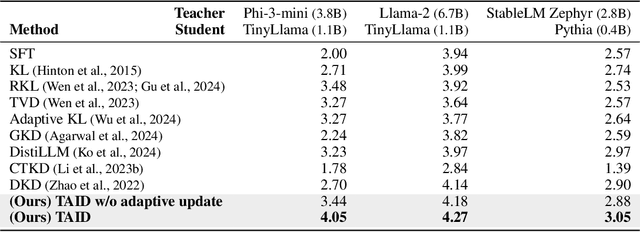
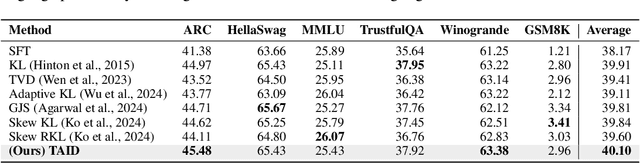
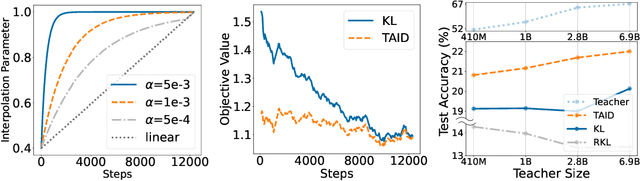
Causal language models have demonstrated remarkable capabilities, but their size poses significant challenges for deployment in resource-constrained environments. Knowledge distillation, a widely-used technique for transferring knowledge from a large teacher model to a small student model, presents a promising approach for model compression. A significant remaining issue lies in the major differences between teacher and student models, namely the substantial capacity gap, mode averaging, and mode collapse, which pose barriers during distillation. To address these issues, we introduce $\textit{Temporally Adaptive Interpolated Distillation (TAID)}$, a novel knowledge distillation approach that dynamically interpolates student and teacher distributions through an adaptive intermediate distribution, gradually shifting from the student's initial distribution towards the teacher's distribution. We provide a theoretical analysis demonstrating TAID's ability to prevent mode collapse and empirically show its effectiveness in addressing the capacity gap while balancing mode averaging and mode collapse. Our comprehensive experiments demonstrate TAID's superior performance across various model sizes and architectures in both instruction tuning and pre-training scenarios. Furthermore, we showcase TAID's practical impact by developing two state-of-the-art compact foundation models: $\texttt{TAID-LLM-1.5B}$ for language tasks and $\texttt{TAID-VLM-2B}$ for vision-language tasks. These results demonstrate TAID's effectiveness in creating high-performing and efficient models, advancing the development of more accessible AI technologies.
Local Curvature Smoothing with Stein's Identity for Efficient Score Matching
Dec 05, 2024



The training of score-based diffusion models (SDMs) is based on score matching. The challenge of score matching is that it includes a computationally expensive Jacobian trace. While several methods have been proposed to avoid this computation, each has drawbacks, such as instability during training and approximating the learning as learning a denoising vector field rather than a true score. We propose a novel score matching variant, local curvature smoothing with Stein's identity (LCSS). The LCSS bypasses the Jacobian trace by applying Stein's identity, enabling regularization effectiveness and efficient computation. We show that LCSS surpasses existing methods in sample generation performance and matches the performance of denoising score matching, widely adopted by most SDMs, in evaluations such as FID, Inception score, and bits per dimension. Furthermore, we show that LCSS enables realistic image generation even at a high resolution of $1024 \times 1024$.
Release of Pre-Trained Models for the Japanese Language
Apr 02, 2024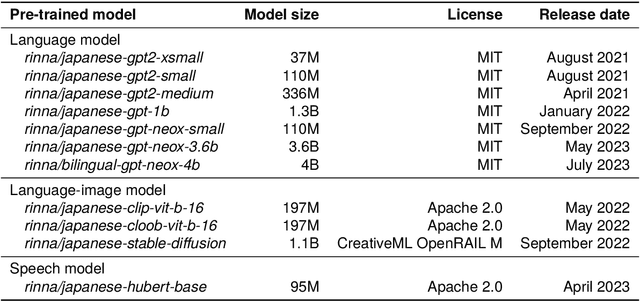

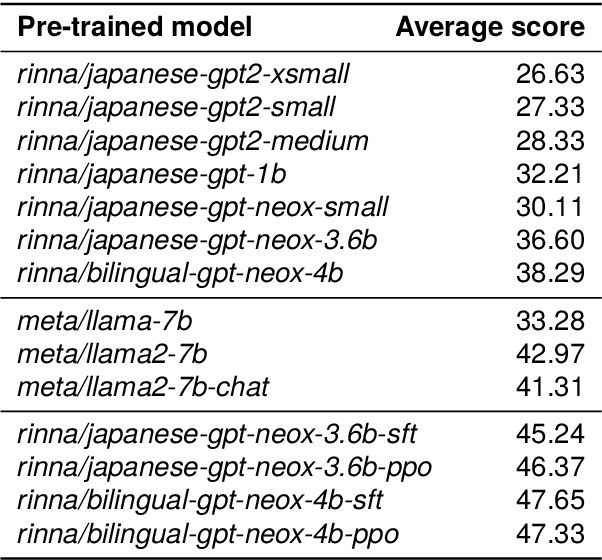
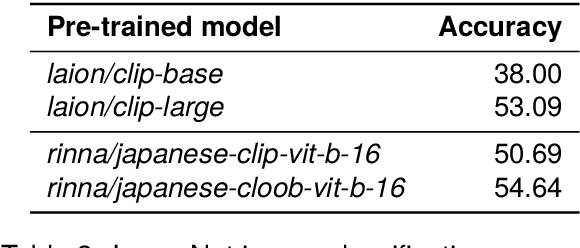
AI democratization aims to create a world in which the average person can utilize AI techniques. To achieve this goal, numerous research institutes have attempted to make their results accessible to the public. In particular, large pre-trained models trained on large-scale data have shown unprecedented potential, and their release has had a significant impact. However, most of the released models specialize in the English language, and thus, AI democratization in non-English-speaking communities is lagging significantly. To reduce this gap in AI access, we released Generative Pre-trained Transformer (GPT), Contrastive Language and Image Pre-training (CLIP), Stable Diffusion, and Hidden-unit Bidirectional Encoder Representations from Transformers (HuBERT) pre-trained in Japanese. By providing these models, users can freely interface with AI that aligns with Japanese cultural values and ensures the identity of Japanese culture, thus enhancing the democratization of AI. Additionally, experiments showed that pre-trained models specialized for Japanese can efficiently achieve high performance in Japanese tasks.
Evolutionary Optimization of Model Merging Recipes
Mar 19, 2024
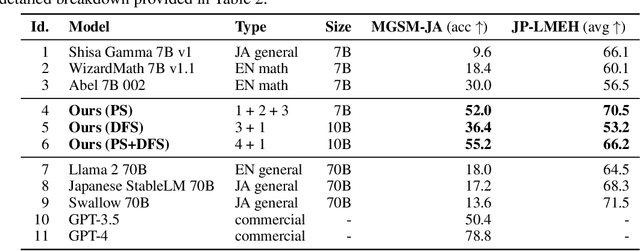

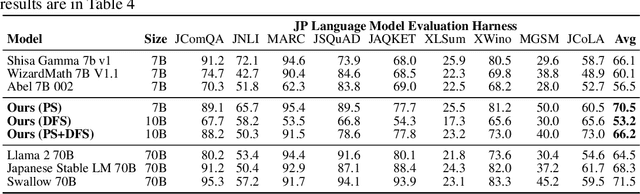
We present a novel application of evolutionary algorithms to automate the creation of powerful foundation models. While model merging has emerged as a promising approach for LLM development due to its cost-effectiveness, it currently relies on human intuition and domain knowledge, limiting its potential. Here, we propose an evolutionary approach that overcomes this limitation by automatically discovering effective combinations of diverse open-source models, harnessing their collective intelligence without requiring extensive additional training data or compute. Our approach operates in both parameter space and data flow space, allowing for optimization beyond just the weights of the individual models. This approach even facilitates cross-domain merging, generating models like a Japanese LLM with Math reasoning capabilities. Surprisingly, our Japanese Math LLM achieved state-of-the-art performance on a variety of established Japanese LLM benchmarks, even surpassing models with significantly more parameters, despite not being explicitly trained for such tasks. Furthermore, a culturally-aware Japanese VLM generated through our approach demonstrates its effectiveness in describing Japanese culture-specific content, outperforming previous Japanese VLMs. This work not only contributes new state-of-the-art models back to the open-source community, but also introduces a new paradigm for automated model composition, paving the way for exploring alternative, efficient approaches to foundation model development.
Focused Prefix Tuning for Controllable Text Generation
Jun 10, 2023



In a controllable text generation dataset, there exist unannotated attributes that could provide irrelevant learning signals to models that use it for training and thus degrade their performance. We propose focused prefix tuning(FPT) to mitigate the problem and to enable the control to focus on the desired attribute. Experimental results show that FPT can achieve better control accuracy and text fluency than baseline models in single-attribute control tasks. In multi-attribute control tasks, FPT achieves comparable control accuracy with the state-of-the-art approach while keeping the flexibility to control new attributes without retraining existing models.
Text-Guided Scene Sketch-to-Photo Synthesis
Feb 14, 2023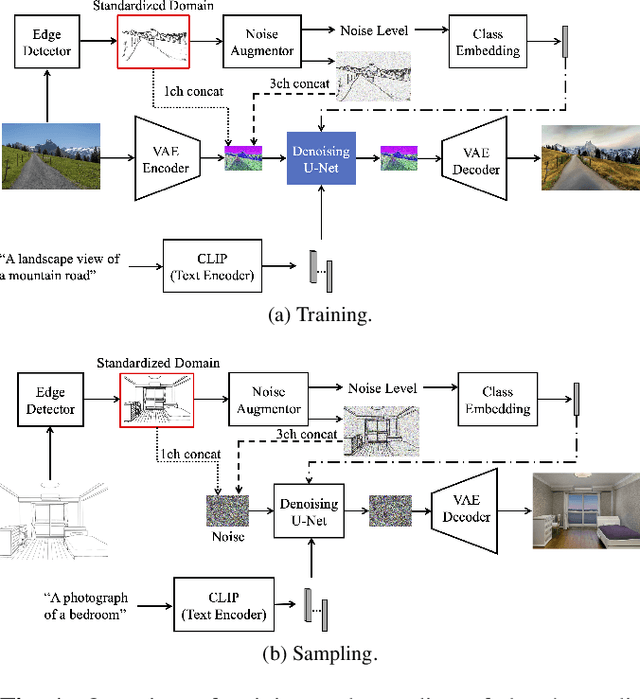
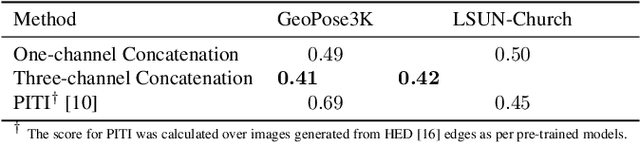


We propose a method for scene-level sketch-to-photo synthesis with text guidance. Although object-level sketch-to-photo synthesis has been widely studied, whole-scene synthesis is still challenging without reference photos that adequately reflect the target style. To this end, we leverage knowledge from recent large-scale pre-trained generative models, resulting in text-guided sketch-to-photo synthesis without the need for reference images. To train our model, we use self-supervised learning from a set of photographs. Specifically, we use a pre-trained edge detector that maps both color and sketch images into a standardized edge domain, which reduces the gap between photograph-based edge images (during training) and hand-drawn sketch images (during inference). We implement our method by fine-tuning a latent diffusion model (i.e., Stable Diffusion) with sketch and text conditions. Experiments show that the proposed method translates original sketch images that are not extracted from color images into photos with compelling visual quality.