 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSarashina2.2-TTS: Tackling Kanji Polyphony in Japanese Speech Generation via Data Scaling and Targeted Data Synthesis
Jun 24, 2026While large language model (LLM)-based text-to-speech (TTS) systems have achieved high-quality speech synthesis, most existing systems focus on English and Chinese. Japanese, however, remains under-explored, and its unique linguistic challenges, such as widespread context-dependent kanji polyphony, have yet to be adequately tackled. Here we introduce Sarashina2.2-TTS (https://github.com/sbintuitions/sarashina2.2-tts), a Japanese-centric LLM-TTS system that tackles these challenges through a dual approach: data strategy and evaluation methodology. First, we scale training to approximately 361k hours of speech, incorporating a balanced mix of Japanese and English data. Furthermore, we design a targeted data augmentation pipeline covering all 2,136 Joyo (regular-use) kanji designated by Japan's Agency for Cultural Affairs to efficiently address kanji polyphony disambiguation. Second, we introduce the Joyo Kanji Yomi Benchmark (https://github.com/sbintuitions/JoyoKanji-Yomi-Benchmark), covering all 2,136 Joyo kanji and their 4,378 readings. Alongside this benchmark, we propose Kana-CER, a metric that compares synthesized speech against reference readings in the kana space, eliminating orthographic variations to directly measure pronunciation correctness. Experiments demonstrate that our targeted data augmentation significantly improves reading accuracy. Overall, Sarashina2.2-TTS achieves state-of-the-art kanji-level reading accuracy and matches top baselines on general sentence-level pronunciation, while delivering the highest speaker similarity in zero-shot Japanese speech synthesis. Furthermore, cross-lingual evaluation reveals that Sarashina2.2-TTS is the only system that maintains stable Japanese pronunciation regardless of the prompt language, confirming that our balanced training approach improves cross-lingual robustness.
PSLM: Parallel Generation of Text and Speech with LLMs for Low-Latency Spoken Dialogue Systems
Jun 18, 2024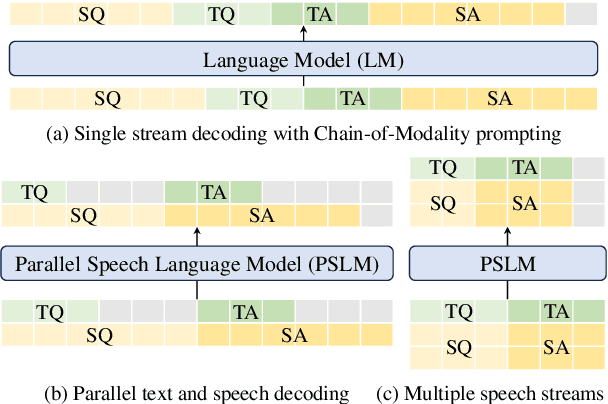
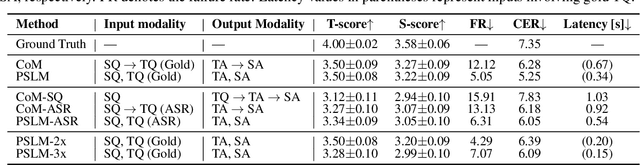
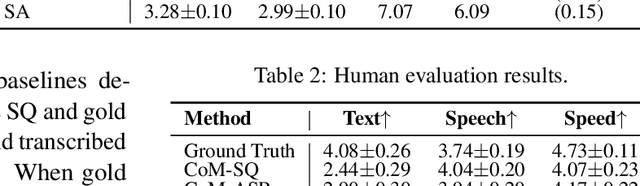
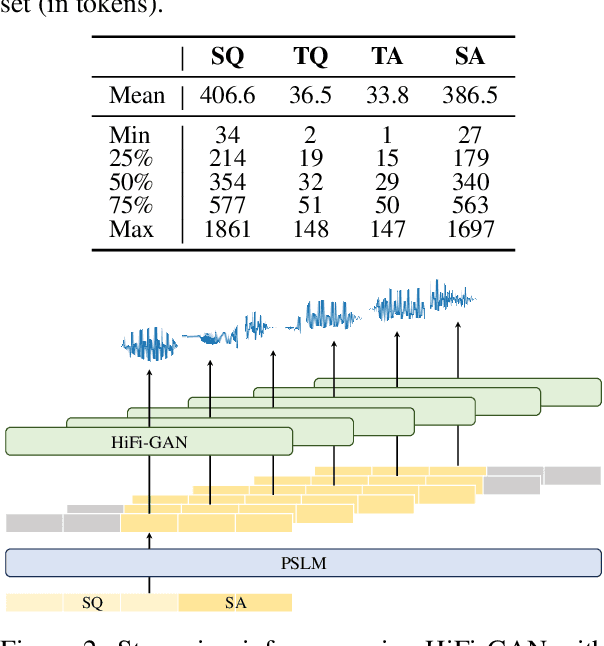
Multimodal language models that process both text and speech have a potential for applications in spoken dialogue systems. However, current models face two major challenges in response generation latency: (1) generating a spoken response requires the prior generation of a written response, and (2) speech sequences are significantly longer than text sequences. This study addresses these issues by extending the input and output sequences of the language model to support the parallel generation of text and speech. Our experiments on spoken question answering tasks demonstrate that our approach improves latency while maintaining the quality of response content. Additionally, we show that latency can be further reduced by generating speech in multiple sequences. Demo samples are available at https://rinnakk.github.io/research/publications/PSLM.
Release of Pre-Trained Models for the Japanese Language
Apr 02, 2024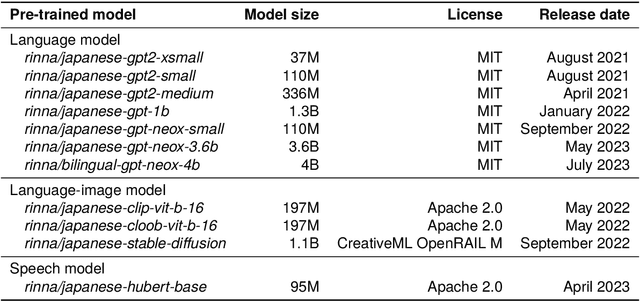

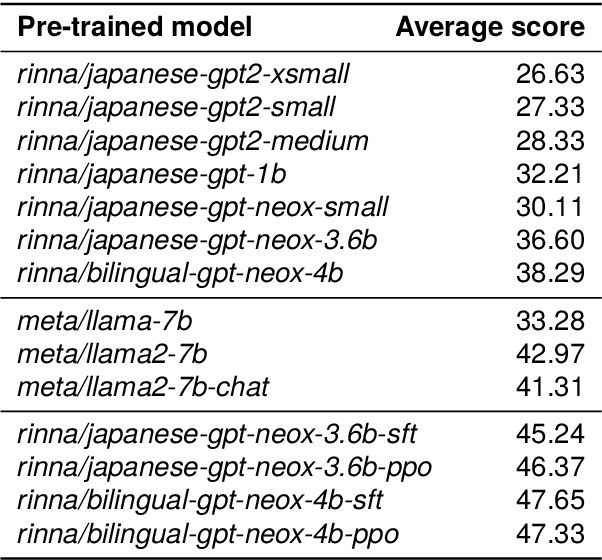
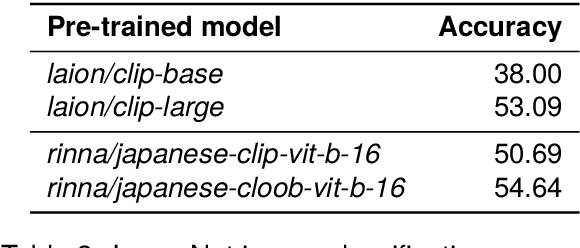
AI democratization aims to create a world in which the average person can utilize AI techniques. To achieve this goal, numerous research institutes have attempted to make their results accessible to the public. In particular, large pre-trained models trained on large-scale data have shown unprecedented potential, and their release has had a significant impact. However, most of the released models specialize in the English language, and thus, AI democratization in non-English-speaking communities is lagging significantly. To reduce this gap in AI access, we released Generative Pre-trained Transformer (GPT), Contrastive Language and Image Pre-training (CLIP), Stable Diffusion, and Hidden-unit Bidirectional Encoder Representations from Transformers (HuBERT) pre-trained in Japanese. By providing these models, users can freely interface with AI that aligns with Japanese cultural values and ensures the identity of Japanese culture, thus enhancing the democratization of AI. Additionally, experiments showed that pre-trained models specialized for Japanese can efficiently achieve high performance in Japanese tasks.
PeriodGrad: Towards Pitch-Controllable Neural Vocoder Based on a Diffusion Probabilistic Model
Feb 22, 2024



This paper presents a neural vocoder based on a denoising diffusion probabilistic model (DDPM) incorporating explicit periodic signals as auxiliary conditioning signals. Recently, DDPM-based neural vocoders have gained prominence as non-autoregressive models that can generate high-quality waveforms. The neural vocoders based on DDPM have the advantage of training with a simple time-domain loss. In practical applications, such as singing voice synthesis, there is a demand for neural vocoders to generate high-fidelity speech waveforms with flexible pitch control. However, conventional DDPM-based neural vocoders struggle to generate speech waveforms under such conditions. Our proposed model aims to accurately capture the periodic structure of speech waveforms by incorporating explicit periodic signals. Experimental results show that our model improves sound quality and provides better pitch control than conventional DDPM-based neural vocoders.
An Integration of Pre-Trained Speech and Language Models for End-to-End Speech Recognition
Dec 06, 2023



Advances in machine learning have made it possible to perform various text and speech processing tasks, including automatic speech recognition (ASR), in an end-to-end (E2E) manner. Since typical E2E approaches require large amounts of training data and resources, leveraging pre-trained foundation models instead of training from scratch is gaining attention. Although there have been attempts to use pre-trained speech and language models in ASR, most of them are limited to using either. This paper explores the potential of integrating a pre-trained speech representation model with a large language model (LLM) for E2E ASR. The proposed model enables E2E ASR by generating text tokens in an autoregressive manner via speech representations as speech prompts, taking advantage of the vast knowledge provided by the LLM. Furthermore, the proposed model can incorporate remarkable developments for LLM utilization, such as inference optimization and parameter-efficient domain adaptation. Experimental results show that the proposed model achieves performance comparable to modern E2E ASR models.
Towards human-like spoken dialogue generation between AI agents from written dialogue
Oct 02, 2023



The advent of large language models (LLMs) has made it possible to generate natural written dialogues between two agents. However, generating human-like spoken dialogues from these written dialogues remains challenging. Spoken dialogues have several unique characteristics: they frequently include backchannels and laughter, and the smoothness of turn-taking significantly influences the fluidity of conversation. This study proposes CHATS - CHatty Agents Text-to-Speech - a discrete token-based system designed to generate spoken dialogues based on written dialogues. Our system can generate speech for both the speaker side and the listener side simultaneously, using only the transcription from the speaker side, which eliminates the need for transcriptions of backchannels or laughter. Moreover, CHATS facilitates natural turn-taking; it determines the appropriate duration of silence after each utterance in the absence of overlap, and it initiates the generation of overlapping speech based on the phoneme sequence of the next utterance in case of overlap. Experimental evaluations indicate that CHATS outperforms the text-to-speech baseline, producing spoken dialogues that are more interactive and fluid while retaining clarity and intelligibility.
UniFLG: Unified Facial Landmark Generator from Text or Speech
Feb 28, 2023



Talking face generation has been extensively investigated owing to its wide applicability. The two primary frameworks used for talking face generation comprise a text-driven framework, which generates synchronized speech and talking faces from text, and a speech-driven framework, which generates talking faces from speech. To integrate these frameworks, this paper proposes a unified facial landmark generator (UniFLG). The proposed system exploits end-to-end text-to-speech not only for synthesizing speech but also for extracting a series of latent representations that are common to text and speech, and feeds it to a landmark decoder to generate facial landmarks. We demonstrate that our system achieves higher naturalness in both speech synthesis and facial landmark generation compared to the state-of-the-art text-driven method. We further demonstrate that our system can generate facial landmarks from speech of speakers without facial video data or even speech data.
Singing voice synthesis based on frame-level sequence-to-sequence models considering vocal timing deviation
Jan 05, 2023



This paper proposes singing voice synthesis (SVS) based on frame-level sequence-to-sequence models considering vocal timing deviation. In SVS, it is essential to synchronize the timing of singing with temporal structures represented by scores, taking into account that there are differences between actual vocal timing and note start timing. In many SVS systems including our previous work, phoneme-level score features are converted into frame-level ones on the basis of phoneme boundaries obtained by external aligners to take into account vocal timing deviations. Therefore, the sound quality is affected by the aligner accuracy in this system. To alleviate this problem, we introduce an attention mechanism with frame-level features. In the proposed system, the attention mechanism absorbs alignment errors in phoneme boundaries. Additionally, we evaluate the system with pseudo-phoneme-boundaries defined by heuristic rules based on musical scores when there is no aligner. The experimental results show the effectiveness of the proposed system.
Singing Voice Synthesis Based on a Musical Note Position-Aware Attention Mechanism
Dec 28, 2022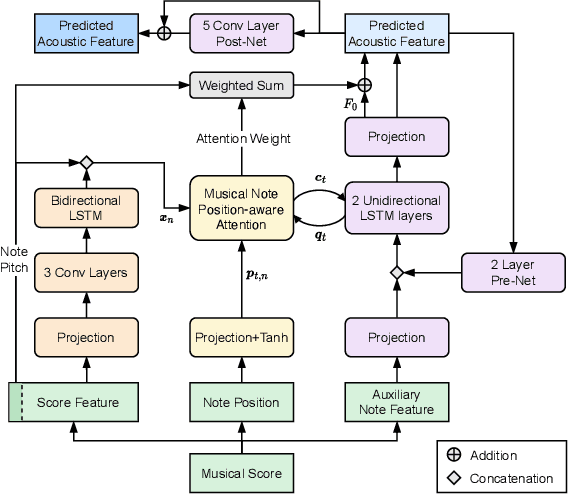

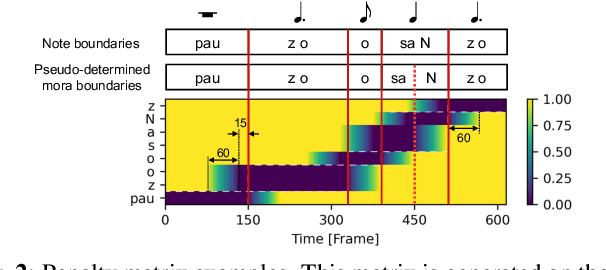

This paper proposes a novel sequence-to-sequence (seq2seq) model with a musical note position-aware attention mechanism for singing voice synthesis (SVS). A seq2seq modeling approach that can simultaneously perform acoustic and temporal modeling is attractive. However, due to the difficulty of the temporal modeling of singing voices, many recent SVS systems with an encoder-decoder-based model still rely on explicitly on duration information generated by additional modules. Although some studies perform simultaneous modeling using seq2seq models with an attention mechanism, they have insufficient robustness against temporal modeling. The proposed attention mechanism is designed to estimate the attention weights by considering the rhythm given by the musical score. Furthermore, several techniques are also introduced to improve the modeling performance of the singing voice. Experimental results indicated that the proposed model is effective in terms of both naturalness and robustness of timing.
Embedding a Differentiable Mel-cepstral Synthesis Filter to a Neural Speech Synthesis System
Nov 21, 2022



This paper integrates a classic mel-cepstral synthesis filter into a modern neural speech synthesis system towards end-to-end controllable speech synthesis. Since the mel-cepstral synthesis filter is explicitly embedded in neural waveform models in the proposed system, both voice characteristics and the pitch of synthesized speech are highly controlled via a frequency warping parameter and fundamental frequency, respectively. We implement the mel-cepstral synthesis filter as a differentiable and GPU-friendly module to enable the acoustic and waveform models in the proposed system to be simultaneously optimized in an end-to-end manner. Experiments show that the proposed system improves speech quality from a baseline system maintaining controllability. The core PyTorch modules used in the experiments will be publicly available on GitHub.