 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeriodGrad: Towards Pitch-Controllable Neural Vocoder Based on a Diffusion Probabilistic Model
Feb 22, 2024This paper presents a neural vocoder based on a denoising diffusion probabilistic model (DDPM) incorporating explicit periodic signals as auxiliary conditioning signals. Recently, DDPM-based neural vocoders have gained prominence as non-autoregressive models that can generate high-quality waveforms. The neural vocoders based on DDPM have the advantage of training with a simple time-domain loss. In practical applications, such as singing voice synthesis, there is a demand for neural vocoders to generate high-fidelity speech waveforms with flexible pitch control. However, conventional DDPM-based neural vocoders struggle to generate speech waveforms under such conditions. Our proposed model aims to accurately capture the periodic structure of speech waveforms by incorporating explicit periodic signals. Experimental results show that our model improves sound quality and provides better pitch control than conventional DDPM-based neural vocoders.
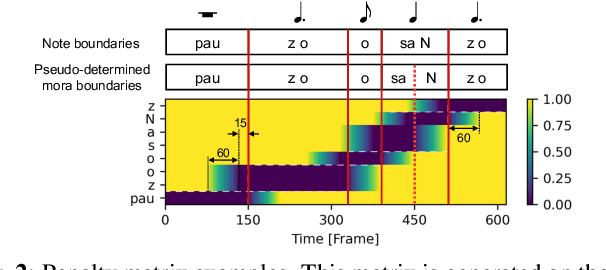
Singing voice synthesis based on frame-level sequence-to-sequence models considering vocal timing deviation
Jan 05, 2023This paper proposes singing voice synthesis (SVS) based on frame-level sequence-to-sequence models considering vocal timing deviation. In SVS, it is essential to synchronize the timing of singing with temporal structures represented by scores, taking into account that there are differences between actual vocal timing and note start timing. In many SVS systems including our previous work, phoneme-level score features are converted into frame-level ones on the basis of phoneme boundaries obtained by external aligners to take into account vocal timing deviations. Therefore, the sound quality is affected by the aligner accuracy in this system. To alleviate this problem, we introduce an attention mechanism with frame-level features. In the proposed system, the attention mechanism absorbs alignment errors in phoneme boundaries. Additionally, we evaluate the system with pseudo-phoneme-boundaries defined by heuristic rules based on musical scores when there is no aligner. The experimental results show the effectiveness of the proposed system.
Singing Voice Synthesis Based on a Musical Note Position-Aware Attention Mechanism
Dec 28, 2022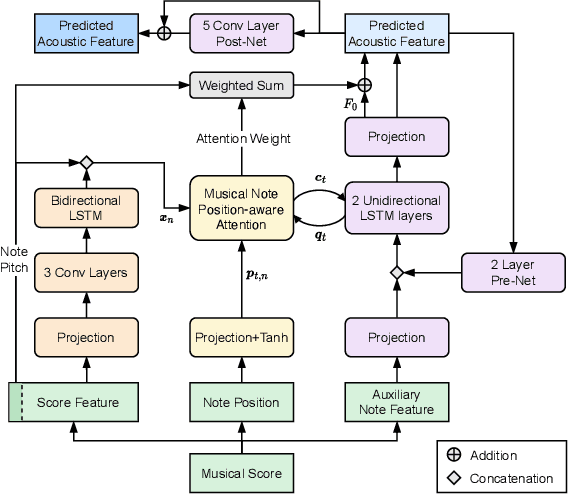


This paper proposes a novel sequence-to-sequence (seq2seq) model with a musical note position-aware attention mechanism for singing voice synthesis (SVS). A seq2seq modeling approach that can simultaneously perform acoustic and temporal modeling is attractive. However, due to the difficulty of the temporal modeling of singing voices, many recent SVS systems with an encoder-decoder-based model still rely on explicitly on duration information generated by additional modules. Although some studies perform simultaneous modeling using seq2seq models with an attention mechanism, they have insufficient robustness against temporal modeling. The proposed attention mechanism is designed to estimate the attention weights by considering the rhythm given by the musical score. Furthermore, several techniques are also introduced to improve the modeling performance of the singing voice. Experimental results indicated that the proposed model is effective in terms of both naturalness and robustness of timing.
Embedding a Differentiable Mel-cepstral Synthesis Filter to a Neural Speech Synthesis System
Nov 21, 2022



This paper integrates a classic mel-cepstral synthesis filter into a modern neural speech synthesis system towards end-to-end controllable speech synthesis. Since the mel-cepstral synthesis filter is explicitly embedded in neural waveform models in the proposed system, both voice characteristics and the pitch of synthesized speech are highly controlled via a frequency warping parameter and fundamental frequency, respectively. We implement the mel-cepstral synthesis filter as a differentiable and GPU-friendly module to enable the acoustic and waveform models in the proposed system to be simultaneously optimized in an end-to-end manner. Experiments show that the proposed system improves speech quality from a baseline system maintaining controllability. The core PyTorch modules used in the experiments will be publicly available on GitHub.
End-to-End Text-to-Speech Based on Latent Representation of Speaking Styles Using Spontaneous Dialogue
Jun 24, 2022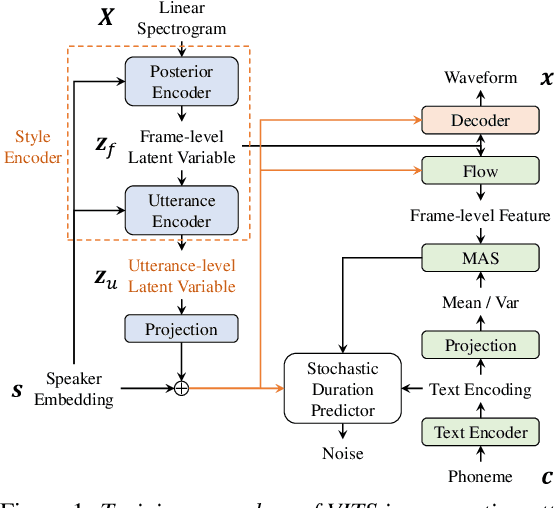
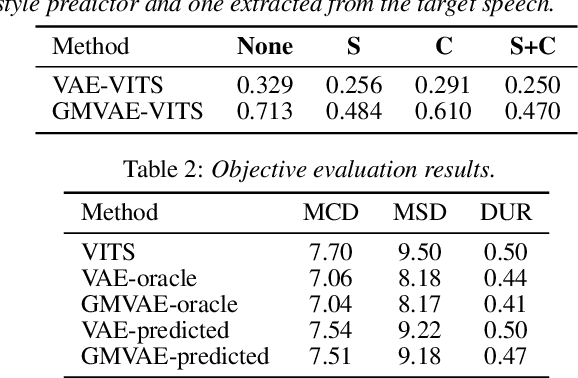
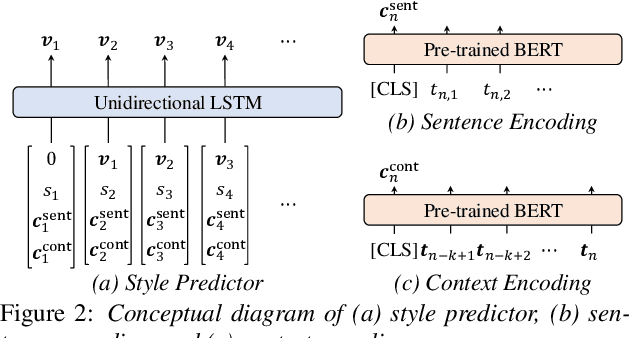
The recent text-to-speech (TTS) has achieved quality comparable to that of humans; however, its application in spoken dialogue has not been widely studied. This study aims to realize a TTS that closely resembles human dialogue. First, we record and transcribe actual spontaneous dialogues. Then, the proposed dialogue TTS is trained in two stages: first stage, variational autoencoder (VAE)-VITS or Gaussian mixture variational autoencoder (GMVAE)-VITS is trained, which introduces an utterance-level latent variable into variational inference with adversarial learning for end-to-end text-to-speech (VITS), a recently proposed end-to-end TTS model. A style encoder that extracts a latent speaking style representation from speech is trained jointly with TTS. In the second stage, a style predictor is trained to predict the speaking style to be synthesized from dialogue history. During inference, by passing the speaking style representation predicted by the style predictor to VAE/GMVAE-VITS, speech can be synthesized in a style appropriate to the context of the dialogue. Subjective evaluation results demonstrate that the proposed method outperforms the original VITS in terms of dialogue-level naturalness.
Neural Sequence-to-Sequence Speech Synthesis Using a Hidden Semi-Markov Model Based Structured Attention Mechanism
Aug 31, 2021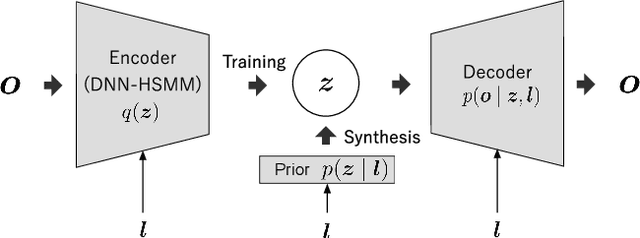
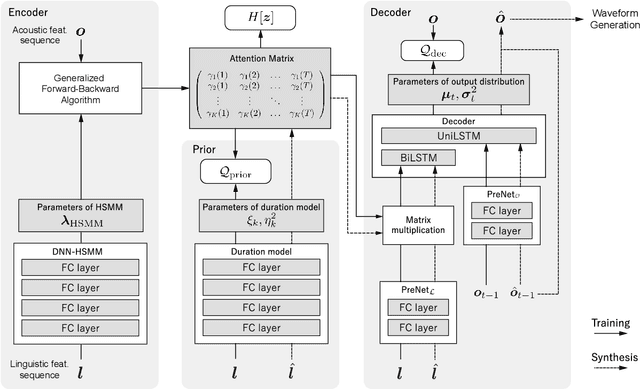
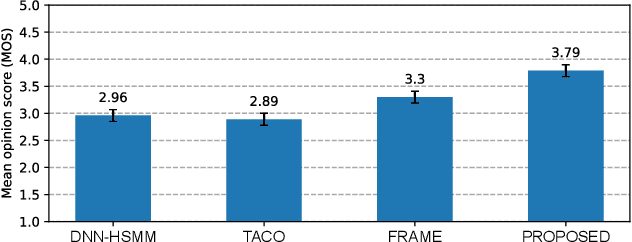
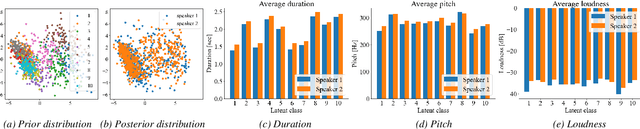
This paper proposes a novel Sequence-to-Sequence (Seq2Seq) model integrating the structure of Hidden Semi-Markov Models (HSMMs) into its attention mechanism. In speech synthesis, it has been shown that methods based on Seq2Seq models using deep neural networks can synthesize high quality speech under the appropriate conditions. However, several essential problems still have remained, i.e., requiring large amounts of training data due to an excessive degree for freedom in alignment (mapping function between two sequences), and the difficulty in handling duration due to the lack of explicit duration modeling. The proposed method defines a generative models to realize the simultaneous optimization of alignments and model parameters based on the Variational Auto-Encoder (VAE) framework, and provides monotonic alignments and explicit duration modeling based on the structure of HSMM. The proposed method can be regarded as an integration of Hidden Markov Model (HMM) based speech synthesis and deep learning based speech synthesis using Seq2Seq models, incorporating both the benefits. Subjective evaluation experiments showed that the proposed method obtained higher mean opinion scores than Tacotron 2 on relatively small amount of training data.
Sinsy: A Deep Neural Network-Based Singing Voice Synthesis System
Aug 05, 2021


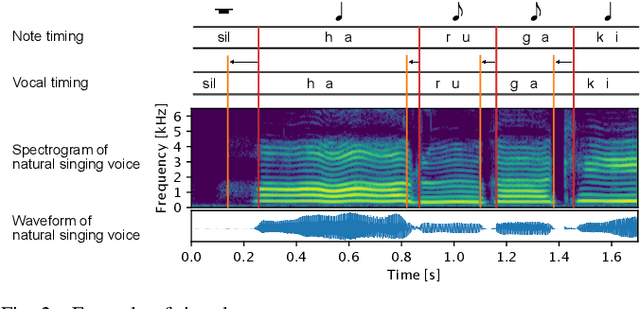
This paper presents Sinsy, a deep neural network (DNN)-based singing voice synthesis (SVS) system. In recent years, DNNs have been utilized in statistical parametric SVS systems, and DNN-based SVS systems have demonstrated better performance than conventional hidden Markov model-based ones. SVS systems are required to synthesize a singing voice with pitch and timing that strictly follow a given musical score. Additionally, singing expressions that are not described on the musical score, such as vibrato and timing fluctuations, should be reproduced. The proposed system is composed of four modules: a time-lag model, a duration model, an acoustic model, and a vocoder, and singing voices can be synthesized taking these characteristics of singing voices into account. To better model a singing voice, the proposed system incorporates improved approaches to modeling pitch and vibrato and better training criteria into the acoustic model. In addition, we incorporated PeriodNet, a non-autoregressive neural vocoder with robustness for the pitch, into our systems to generate a high-fidelity singing voice waveform. Moreover, we propose automatic pitch correction techniques for DNN-based SVS to synthesize singing voices with correct pitch even if the training data has out-of-tune phrases. Experimental results show our system can synthesize a singing voice with better timing, more natural vibrato, and correct pitch, and it can achieve better mean opinion scores in subjective evaluation tests.
PeriodNet: A non-autoregressive waveform generation model with a structure separating periodic and aperiodic components
Feb 15, 2021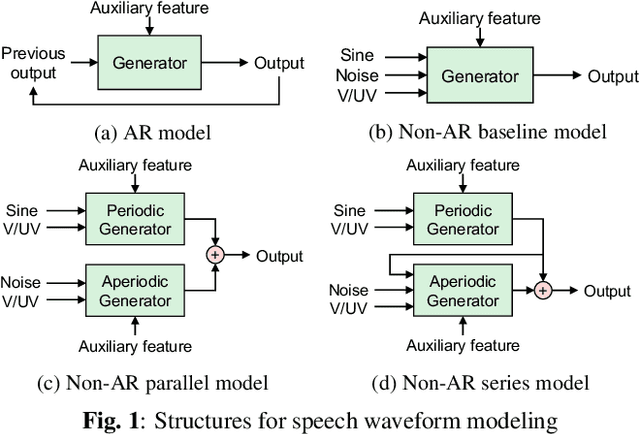
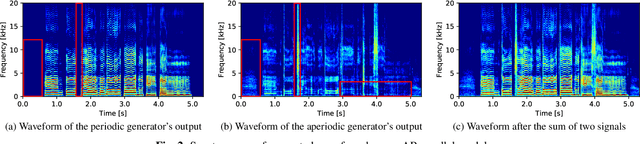
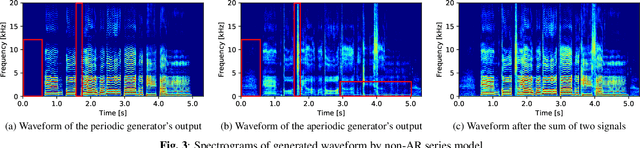
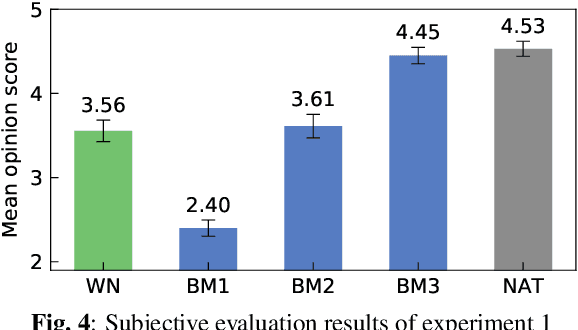
We propose PeriodNet, a non-autoregressive (non-AR) waveform generation model with a new model structure for modeling periodic and aperiodic components in speech waveforms. The non-AR waveform generation models can generate speech waveforms parallelly and can be used as a speech vocoder by conditioning an acoustic feature. Since a speech waveform contains periodic and aperiodic components, both components should be appropriately modeled to generate a high-quality speech waveform. However, it is difficult to decompose the components from a natural speech waveform in advance. To address this issue, we propose a parallel model and a series model structure separating periodic and aperiodic components. The features of our proposed models are that explicit periodic and aperiodic signals are taken as input, and external periodic/aperiodic decomposition is not needed in training. Experiments using a singing voice corpus show that our proposed structure improves the naturalness of the generated waveform. We also show that the speech waveforms with a pitch outside of the training data range can be generated with more naturalness.
Hierarchical Multi-Grained Generative Model for Expressive Speech Synthesis
Sep 17, 2020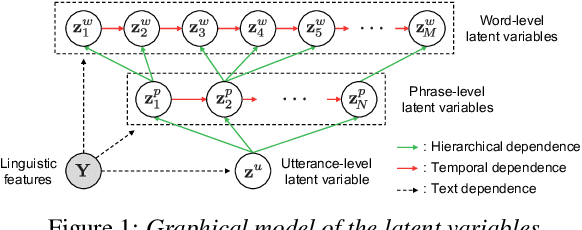


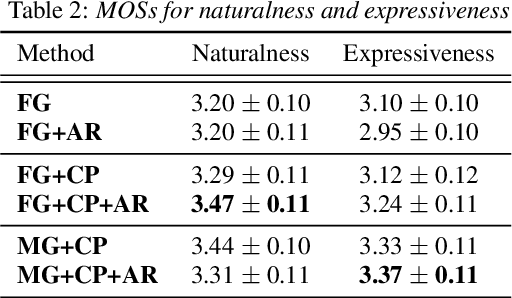
This paper proposes a hierarchical generative model with a multi-grained latent variable to synthesize expressive speech. In recent years, fine-grained latent variables are introduced into the text-to-speech synthesis that enable the fine control of the prosody and speaking styles of synthesized speech. However, the naturalness of speech degrades when these latent variables are obtained by sampling from the standard Gaussian prior. To solve this problem, we propose a novel framework for modeling the fine-grained latent variables, considering the dependence on an input text, a hierarchical linguistic structure, and a temporal structure of latent variables. This framework consists of a multi-grained variational autoencoder, a conditional prior, and a multi-level auto-regressive latent converter to obtain the different time-resolution latent variables and sample the finer-level latent variables from the coarser-level ones by taking into account the input text. Experimental results indicate an appropriate method of sampling fine-grained latent variables without the reference signal at the synthesis stage. Our proposed framework also provides the controllability of speaking style in an entire utterance.
Fast and High-Quality Singing Voice Synthesis System based on Convolutional Neural Networks
Oct 24, 2019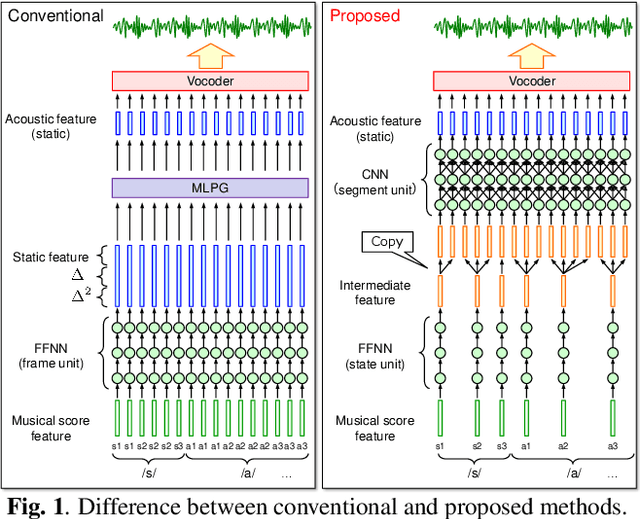
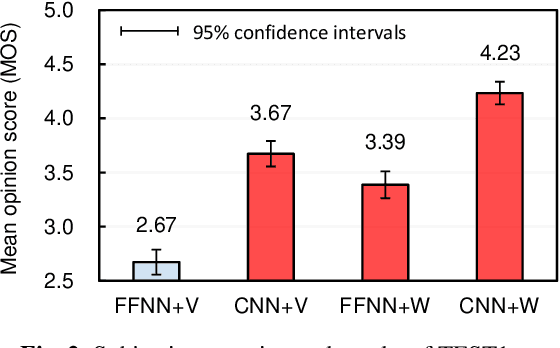
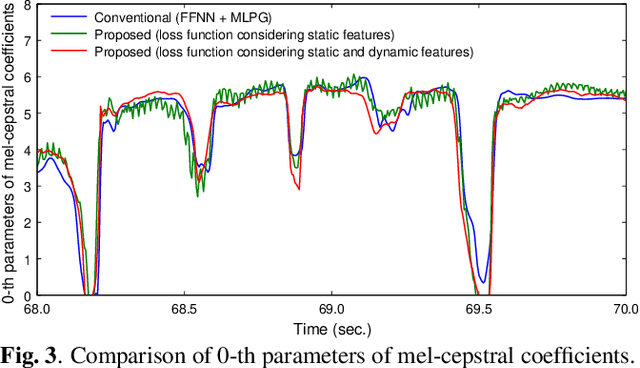
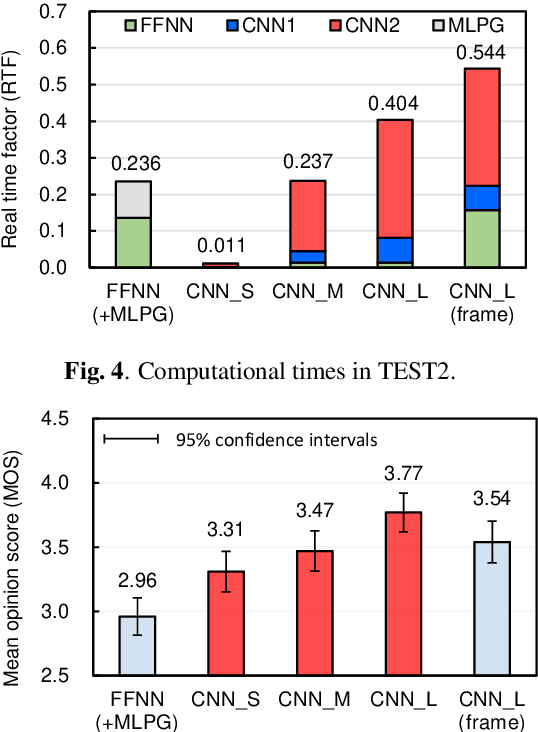
The present paper describes singing voice synthesis based on convolutional neural networks (CNNs). Singing voice synthesis systems based on deep neural networks (DNNs) are currently being proposed and are improving the naturalness of synthesized singing voices. As singing voices represent a rich form of expression, a powerful technique to model them accurately is required. In the proposed technique, long-term dependencies of singing voices are modeled by CNNs. An acoustic feature sequence is generated for each segment that consists of long-term frames, and a natural trajectory is obtained without the parameter generation algorithm. Furthermore, a computational complexity reduction technique, which drives the DNNs in different time units depending on type of musical score features, is proposed. Experimental results show that the proposed method can synthesize natural sounding singing voices much faster than the conventional method.