 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Sequence-to-Sequence Speech Synthesis Using a Hidden Semi-Markov Model Based Structured Attention Mechanism
Paper and Code
Aug 31, 2021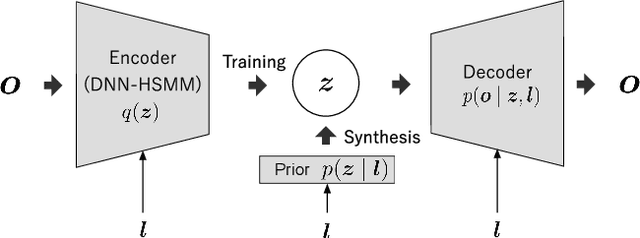
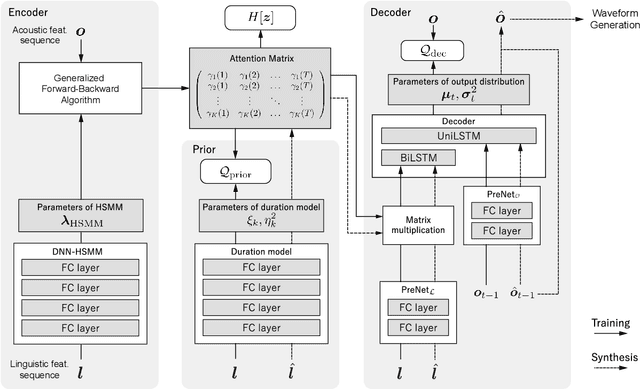
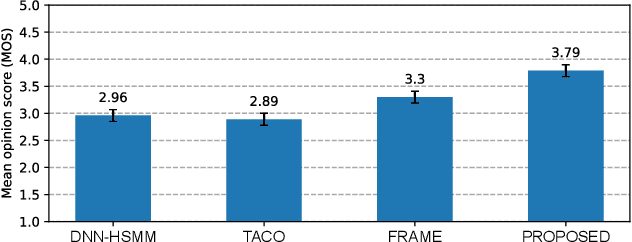
This paper proposes a novel Sequence-to-Sequence (Seq2Seq) model integrating the structure of Hidden Semi-Markov Models (HSMMs) into its attention mechanism. In speech synthesis, it has been shown that methods based on Seq2Seq models using deep neural networks can synthesize high quality speech under the appropriate conditions. However, several essential problems still have remained, i.e., requiring large amounts of training data due to an excessive degree for freedom in alignment (mapping function between two sequences), and the difficulty in handling duration due to the lack of explicit duration modeling. The proposed method defines a generative models to realize the simultaneous optimization of alignments and model parameters based on the Variational Auto-Encoder (VAE) framework, and provides monotonic alignments and explicit duration modeling based on the structure of HSMM. The proposed method can be regarded as an integration of Hidden Markov Model (HMM) based speech synthesis and deep learning based speech synthesis using Seq2Seq models, incorporating both the benefits. Subjective evaluation experiments showed that the proposed method obtained higher mean opinion scores than Tacotron 2 on relatively small amount of training data.