 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSLM: Parallel Generation of Text and Speech with LLMs for Low-Latency Spoken Dialogue Systems
Jun 18, 2024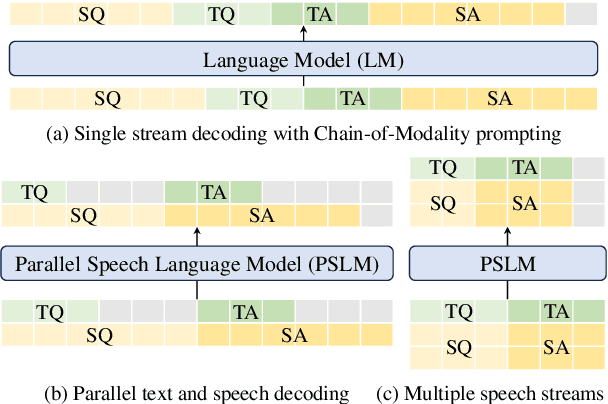
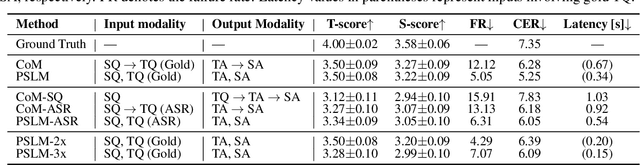
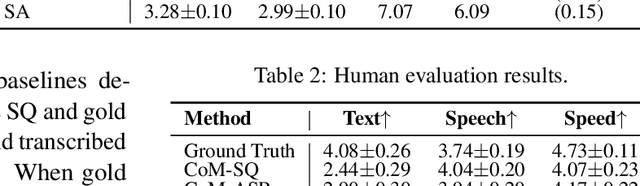
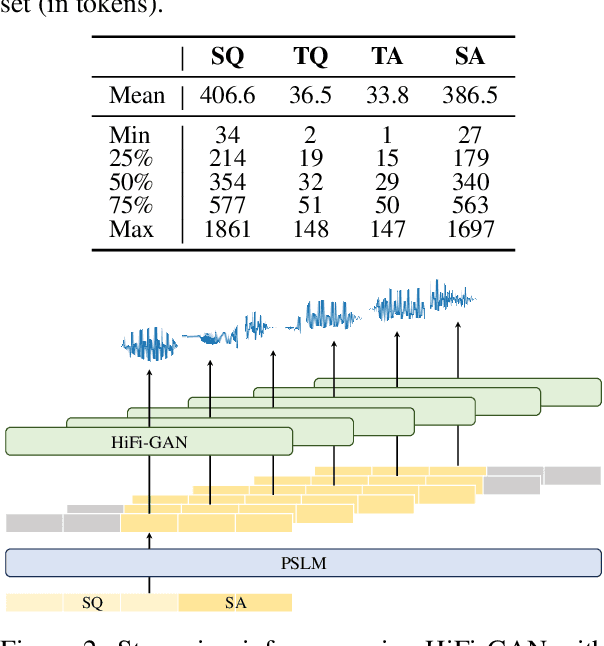
Multimodal language models that process both text and speech have a potential for applications in spoken dialogue systems. However, current models face two major challenges in response generation latency: (1) generating a spoken response requires the prior generation of a written response, and (2) speech sequences are significantly longer than text sequences. This study addresses these issues by extending the input and output sequences of the language model to support the parallel generation of text and speech. Our experiments on spoken question answering tasks demonstrate that our approach improves latency while maintaining the quality of response content. Additionally, we show that latency can be further reduced by generating speech in multiple sequences. Demo samples are available at https://rinnakk.github.io/research/publications/PSLM.
Release of Pre-Trained Models for the Japanese Language
Apr 02, 2024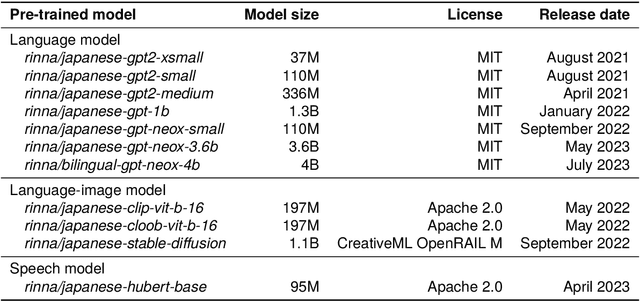

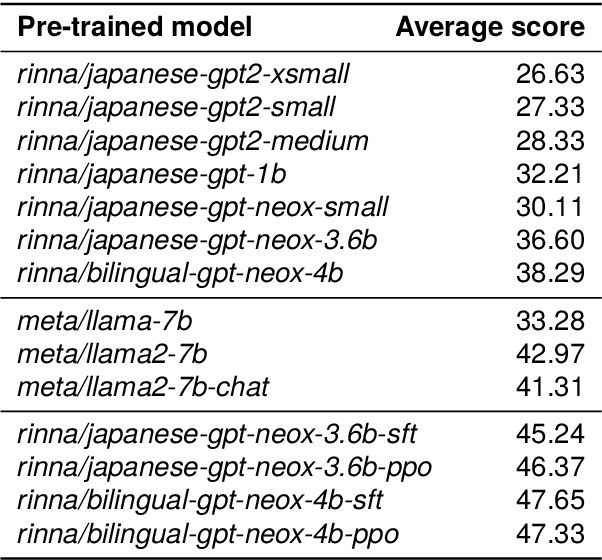
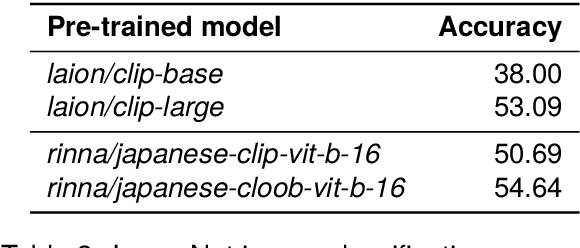
AI democratization aims to create a world in which the average person can utilize AI techniques. To achieve this goal, numerous research institutes have attempted to make their results accessible to the public. In particular, large pre-trained models trained on large-scale data have shown unprecedented potential, and their release has had a significant impact. However, most of the released models specialize in the English language, and thus, AI democratization in non-English-speaking communities is lagging significantly. To reduce this gap in AI access, we released Generative Pre-trained Transformer (GPT), Contrastive Language and Image Pre-training (CLIP), Stable Diffusion, and Hidden-unit Bidirectional Encoder Representations from Transformers (HuBERT) pre-trained in Japanese. By providing these models, users can freely interface with AI that aligns with Japanese cultural values and ensures the identity of Japanese culture, thus enhancing the democratization of AI. Additionally, experiments showed that pre-trained models specialized for Japanese can efficiently achieve high performance in Japanese tasks.
An Integration of Pre-Trained Speech and Language Models for End-to-End Speech Recognition
Dec 06, 2023



Advances in machine learning have made it possible to perform various text and speech processing tasks, including automatic speech recognition (ASR), in an end-to-end (E2E) manner. Since typical E2E approaches require large amounts of training data and resources, leveraging pre-trained foundation models instead of training from scratch is gaining attention. Although there have been attempts to use pre-trained speech and language models in ASR, most of them are limited to using either. This paper explores the potential of integrating a pre-trained speech representation model with a large language model (LLM) for E2E ASR. The proposed model enables E2E ASR by generating text tokens in an autoregressive manner via speech representations as speech prompts, taking advantage of the vast knowledge provided by the LLM. Furthermore, the proposed model can incorporate remarkable developments for LLM utilization, such as inference optimization and parameter-efficient domain adaptation. Experimental results show that the proposed model achieves performance comparable to modern E2E ASR models.