 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Curvature Smoothing with Stein's Identity for Efficient Score Matching
Dec 05, 2024



The training of score-based diffusion models (SDMs) is based on score matching. The challenge of score matching is that it includes a computationally expensive Jacobian trace. While several methods have been proposed to avoid this computation, each has drawbacks, such as instability during training and approximating the learning as learning a denoising vector field rather than a true score. We propose a novel score matching variant, local curvature smoothing with Stein's identity (LCSS). The LCSS bypasses the Jacobian trace by applying Stein's identity, enabling regularization effectiveness and efficient computation. We show that LCSS surpasses existing methods in sample generation performance and matches the performance of denoising score matching, widely adopted by most SDMs, in evaluations such as FID, Inception score, and bits per dimension. Furthermore, we show that LCSS enables realistic image generation even at a high resolution of $1024 \times 1024$.
Understanding Likelihood of Normalizing Flow and Image Complexity through the Lens of Out-of-Distribution Detection
Feb 16, 2024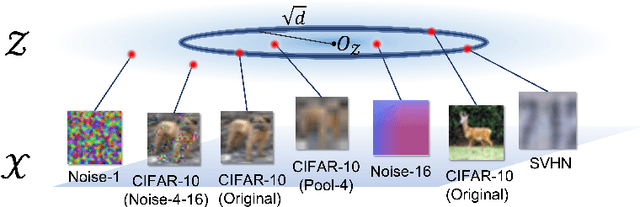
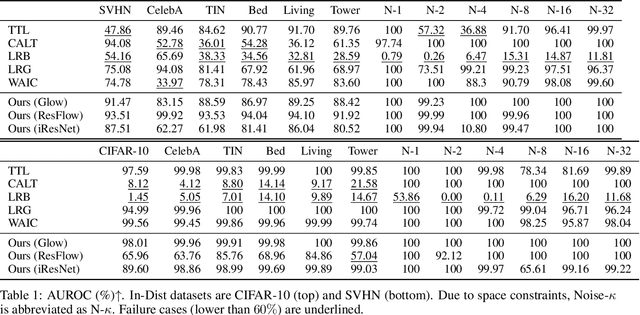

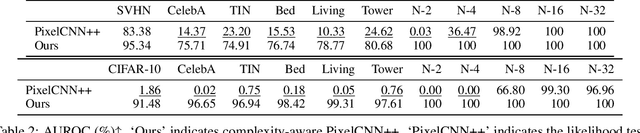
Out-of-distribution (OOD) detection is crucial to safety-critical machine learning applications and has been extensively studied. While recent studies have predominantly focused on classifier-based methods, research on deep generative model (DGM)-based methods have lagged relatively. This disparity may be attributed to a perplexing phenomenon: DGMs often assign higher likelihoods to unknown OOD inputs than to their known training data. This paper focuses on explaining the underlying mechanism of this phenomenon. We propose a hypothesis that less complex images concentrate in high-density regions in the latent space, resulting in a higher likelihood assignment in the Normalizing Flow (NF). We experimentally demonstrate its validity for five NF architectures, concluding that their likelihood is untrustworthy. Additionally, we show that this problem can be alleviated by treating image complexity as an independent variable. Finally, we provide evidence of the potential applicability of our hypothesis in another DGM, PixelCNN++.
Out-of-Distribution Detection with Reconstruction Error and Typicality-based Penalty
Dec 24, 2022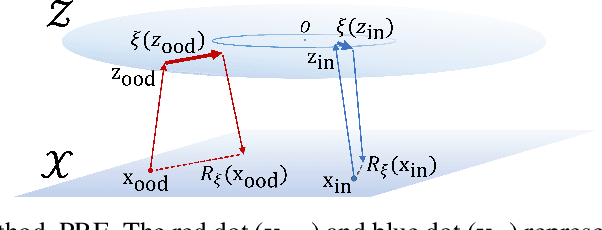
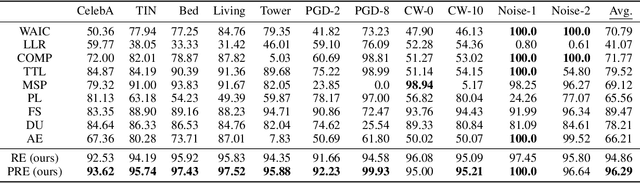
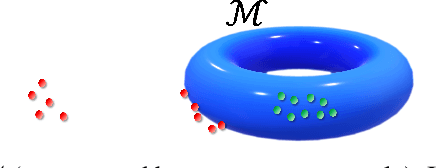
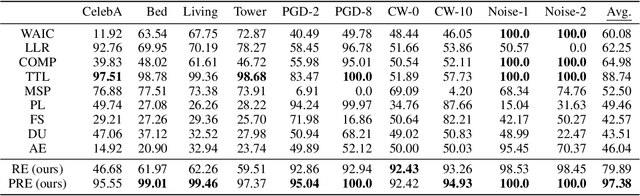
The task of out-of-distribution (OOD) detection is vital to realize safe and reliable operation for real-world applications. After the failure of likelihood-based detection in high dimensions had been shown, approaches based on the \emph{typical set} have been attracting attention; however, they still have not achieved satisfactory performance. Beginning by presenting the failure case of the typicality-based approach, we propose a new reconstruction error-based approach that employs normalizing flow (NF). We further introduce a typicality-based penalty, and by incorporating it into the reconstruction error in NF, we propose a new OOD detection method, penalized reconstruction error (PRE). Because the PRE detects test inputs that lie off the in-distribution manifold, it effectively detects adversarial examples as well as OOD examples. We show the effectiveness of our method through the evaluation using natural image datasets, CIFAR-10, TinyImageNet, and ILSVRC2012.
Regularization with Latent Space Virtual Adversarial Training
Nov 26, 2020


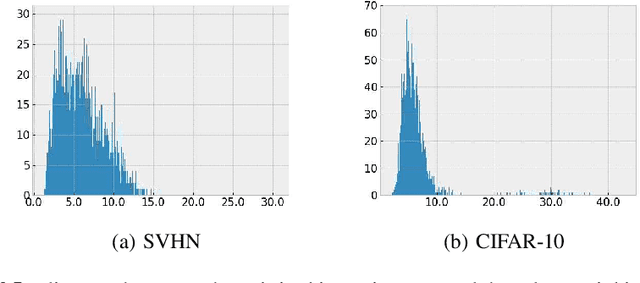
Virtual Adversarial Training (VAT) has shown impressive results among recently developed regularization methods called consistency regularization. VAT utilizes adversarial samples, generated by injecting perturbation in the input space, for training and thereby enhances the generalization ability of a classifier. However, such adversarial samples can be generated only within a very small area around the input data point, which limits the adversarial effectiveness of such samples. To address this problem we propose LVAT (Latent space VAT), which injects perturbation in the latent space instead of the input space. LVAT can generate adversarial samples flexibly, resulting in more adverse effects and thus more effective regularization. The latent space is built by a generative model, and in this paper, we examine two different type of models: variational auto-encoder and normalizing flow, specifically Glow. We evaluated the performance of our method in both supervised and semi-supervised learning scenarios for an image classification task using SVHN and CIFAR-10 datasets. In our evaluation, we found that our method outperforms VAT and other state-of-the-art methods.