 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Oversight via Partitioned Human Supervision
Oct 26, 2025As artificial intelligence (AI) systems approach and surpass expert human performance across a broad range of tasks, obtaining high-quality human supervision for evaluation and training becomes increasingly challenging. Our focus is on tasks that require deep knowledge and skills of multiple domains. Unfortunately, even the best human experts are knowledgeable only in a single narrow area, and will not be able to evaluate the correctness of advanced AI systems on such superhuman tasks. However, based on their narrow expertise, humans may provide a weak signal, i.e., a complementary label indicating an option that is incorrect. For example, a cardiologist could state that "this is not related to cardiology,'' even if they cannot identify the true disease. Based on this weak signal, we propose a scalable oversight framework that enables us to evaluate frontier AI systems without the need to prepare the ground truth. We derive an unbiased estimator of top-1 accuracy from complementary labels and quantify how many complementary labels are needed to match the variance of ordinary labels. We further introduce two estimators to combine scarce ordinary labels with abundant complementary labels. We provide finite-sample deviation guarantees for both complementary-only and the mixed estimators. Empirically, we show that we can evaluate the output of large language models without the ground truth, if we have complementary labels. We further show that we can train an AI system with such weak signals: we show how we can design an agentic AI system automatically that can perform better with this partitioned human supervision. Our code is available at https://github.com/R-Yin-217/Scalable-Oversight-via-Human-Partitioned-Supervision.
LLM Routing with Dueling Feedback
Oct 01, 2025We study LLM routing, the problem of selecting the best model for each query while balancing user satisfaction, model expertise, and inference cost. We formulate routing as contextual dueling bandits, learning from pairwise preference feedback rather than absolute scores, thereby yielding label-efficient and dynamic adaptation. Building on this formulation, we introduce Category-Calibrated Fine-Tuning (CCFT), a representation-learning method that derives model embeddings from offline data using contrastive fine-tuning with categorical weighting. These embeddings enable the practical instantiation of Feel-Good Thompson Sampling for Contextual Dueling Bandits (FGTS.CDB), a theoretically grounded posterior-sampling algorithm. We propose four variants of the categorical weighting that explicitly integrate model quality and cost, and we empirically evaluate the proposed methods on the RouterBench and MixInstruct datasets. Across both benchmarks, our methods achieve lower cumulative regret and faster convergence, with better robustness and performance-cost balance than strong baselines built with a general-purpose OpenAI embedding model.
EDINET-Bench: Evaluating LLMs on Complex Financial Tasks using Japanese Financial Statements
Jun 10, 2025



Financial analysis presents complex challenges that could leverage large language model (LLM) capabilities. However, the scarcity of challenging financial datasets, particularly for Japanese financial data, impedes academic innovation in financial analytics. As LLMs advance, this lack of accessible research resources increasingly hinders their development and evaluation in this specialized domain. To address this gap, we introduce EDINET-Bench, an open-source Japanese financial benchmark designed to evaluate the performance of LLMs on challenging financial tasks including accounting fraud detection, earnings forecasting, and industry prediction. EDINET-Bench is constructed by downloading annual reports from the past 10 years from Japan's Electronic Disclosure for Investors' NETwork (EDINET) and automatically assigning labels corresponding to each evaluation task. Our experiments reveal that even state-of-the-art LLMs struggle, performing only slightly better than logistic regression in binary classification for fraud detection and earnings forecasting. These results highlight significant challenges in applying LLMs to real-world financial applications and underscore the need for domain-specific adaptation. Our dataset, benchmark construction code, and evaluation code is publicly available to facilitate future research in finance with LLMs.
Practical estimation of the optimal classification error with soft labels and calibration
May 27, 2025While the performance of machine learning systems has experienced significant improvement in recent years, relatively little attention has been paid to the fundamental question: to what extent can we improve our models? This paper provides a means of answering this question in the setting of binary classification, which is practical and theoretically supported. We extend a previous work that utilizes soft labels for estimating the Bayes error, the optimal error rate, in two important ways. First, we theoretically investigate the properties of the bias of the hard-label-based estimator discussed in the original work. We reveal that the decay rate of the bias is adaptive to how well the two class-conditional distributions are separated, and it can decay significantly faster than the previous result suggested as the number of hard labels per instance grows. Second, we tackle a more challenging problem setting: estimation with corrupted soft labels. One might be tempted to use calibrated soft labels instead of clean ones. However, we reveal that calibration guarantee is not enough, that is, even perfectly calibrated soft labels can result in a substantially inaccurate estimate. Then, we show that isotonic calibration can provide a statistically consistent estimator under an assumption weaker than that of the previous work. Our method is instance-free, i.e., we do not assume access to any input instances. This feature allows it to be adopted in practical scenarios where the instances are not available due to privacy issues. Experiments with synthetic and real-world datasets show the validity of our methods and theory.
How Can I Publish My LLM Benchmark Without Giving the True Answers Away?
May 23, 2025Publishing a large language model (LLM) benchmark on the Internet risks contaminating future LLMs: the benchmark may be unintentionally (or intentionally) used to train or select a model. A common mitigation is to keep the benchmark private and let participants submit their models or predictions to the organizers. However, this strategy will require trust in a single organization and still permits test-set overfitting through repeated queries. To overcome this issue, we propose a way to publish benchmarks without completely disclosing the ground-truth answers to the questions, while still maintaining the ability to openly evaluate LLMs. Our main idea is to inject randomness to the answers by preparing several logically correct answers, and only include one of them as the solution in the benchmark. This reduces the best possible accuracy, i.e., Bayes accuracy, of the benchmark. Not only is this helpful to keep us from disclosing the ground truth, but this approach also offers a test for detecting data contamination. In principle, even fully capable models should not surpass the Bayes accuracy. If a model surpasses this ceiling despite this expectation, this is a strong signal of data contamination. We present experimental evidence that our method can detect data contamination accurately on a wide range of benchmarks, models, and training methodologies.
Learning with Complementary Labels Revisited: A Consistent Approach via Negative-Unlabeled Learning
Nov 27, 2023Complementary-label learning is a weakly supervised learning problem in which each training example is associated with one or multiple complementary labels indicating the classes to which it does not belong. Existing consistent approaches have relied on the uniform distribution assumption to model the generation of complementary labels, or on an ordinary-label training set to estimate the transition matrix. However, both conditions may not be satisfied in real-world scenarios. In this paper, we propose a novel complementary-label learning approach that does not rely on these conditions. We find that complementary-label learning can be expressed as a set of negative-unlabeled binary classification problems when using the one-versus-rest strategy. This observation allows us to propose a risk-consistent approach with theoretical guarantees. Furthermore, we introduce a risk correction approach to address overfitting problems when using complex models. We also prove the statistical consistency and convergence rate of the corrected risk estimator. Extensive experimental results on both synthetic and real-world benchmark datasets validate the superiority of our proposed approach over state-of-the-art methods.
Flooding Regularization for Stable Training of Generative Adversarial Networks
Nov 01, 2023Generative Adversarial Networks (GANs) have shown remarkable performance in image generation. However, GAN training suffers from the problem of instability. One of the main approaches to address this problem is to modify the loss function, often using regularization terms in addition to changing the type of adversarial losses. This paper focuses on directly regularizing the adversarial loss function. We propose a method that applies flooding, an overfitting suppression method in supervised learning, to GANs to directly prevent the discriminator's loss from becoming excessively low. Flooding requires tuning the flood level, but when applied to GANs, we propose that the appropriate range of flood level settings is determined by the adversarial loss function, supported by theoretical analysis of GANs using the binary cross entropy loss. We experimentally verify that flooding stabilizes GAN training and can be combined with other stabilization techniques. We also reveal that by restricting the discriminator's loss to be no greater than flood level, the training proceeds stably even when the flood level is somewhat high.
Is the Performance of My Deep Network Too Good to Be True? A Direct Approach to Estimating the Bayes Error in Binary Classification
Feb 01, 2022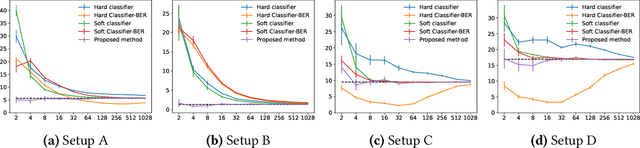

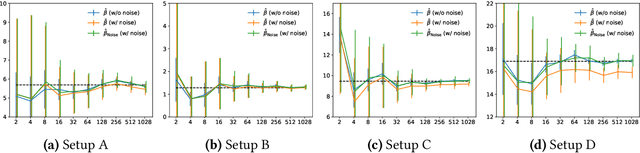

There is a fundamental limitation in the prediction performance that a machine learning model can achieve due to the inevitable uncertainty of the prediction target. In classification problems, this can be characterized by the Bayes error, which is the best achievable error with any classifier. The Bayes error can be used as a criterion to evaluate classifiers with state-of-the-art performance and can be used to detect test set overfitting. We propose a simple and direct Bayes error estimator, where we just take the mean of the labels that show \emph{uncertainty} of the classes. Our flexible approach enables us to perform Bayes error estimation even for weakly supervised data. In contrast to others, our method is model-free and even instance-free. Moreover, it has no hyperparameters and gives a more accurate estimate of the Bayes error than classifier-based baselines. Experiments using our method suggest that a recently proposed classifier, the Vision Transformer, may have already reached the Bayes error for certain benchmark datasets.
LocalDrop: A Hybrid Regularization for Deep Neural Networks
Mar 01, 2021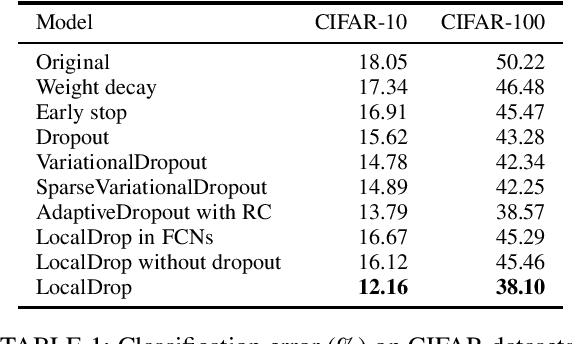
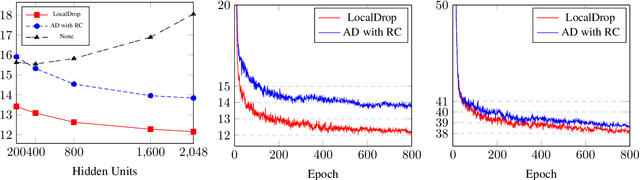
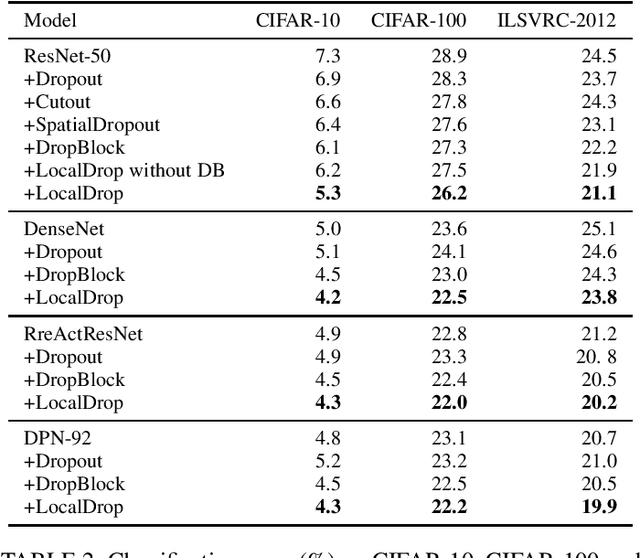
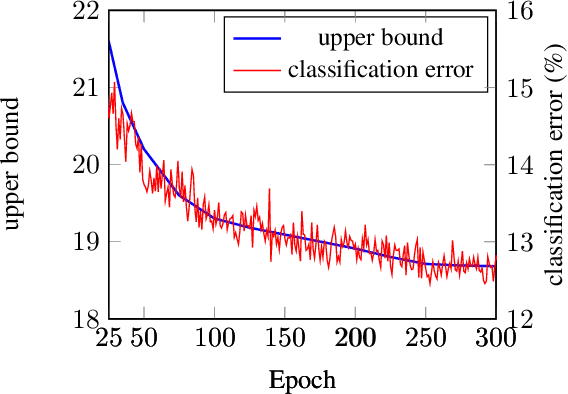
In neural networks, developing regularization algorithms to settle overfitting is one of the major study areas. We propose a new approach for the regularization of neural networks by the local Rademacher complexity called LocalDrop. A new regularization function for both fully-connected networks (FCNs) and convolutional neural networks (CNNs), including drop rates and weight matrices, has been developed based on the proposed upper bound of the local Rademacher complexity by the strict mathematical deduction. The analyses of dropout in FCNs and DropBlock in CNNs with keep rate matrices in different layers are also included in the complexity analyses. With the new regularization function, we establish a two-stage procedure to obtain the optimal keep rate matrix and weight matrix to realize the whole training model. Extensive experiments have been conducted to demonstrate the effectiveness of LocalDrop in different models by comparing it with several algorithms and the effects of different hyperparameters on the final performances.
Do We Need Zero Training Loss After Achieving Zero Training Error?
Feb 20, 2020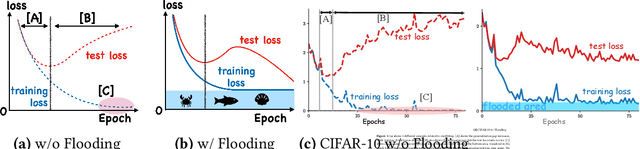
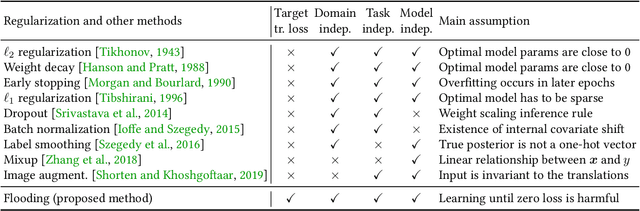
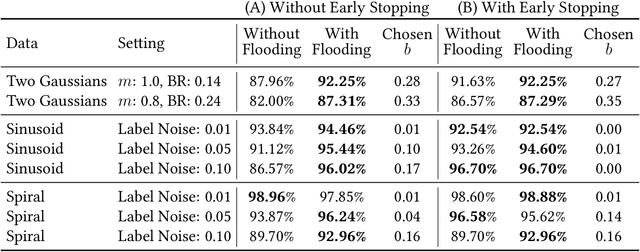
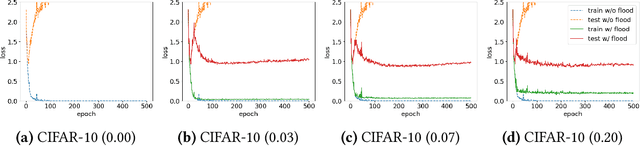
Overparameterized deep networks have the capacity to memorize training data with zero training error. Even after memorization, the training loss continues to approach zero, making the model overconfident and the test performance degraded. Since existing regularizers do not directly aim to avoid zero training loss, they often fail to maintain a moderate level of training loss, ending up with a too small or too large loss. We propose a direct solution called flooding that intentionally prevents further reduction of the training loss when it reaches a reasonably small value, which we call the flooding level. Our approach makes the loss float around the flooding level by doing mini-batched gradient descent as usual but gradient ascent if the training loss is below the flooding level. This can be implemented with one line of code, and is compatible with any stochastic optimizer and other regularizers. With flooding, the model will continue to "random walk" with the same non-zero training loss, and we expect it to drift into an area with a flat loss landscape that leads to better generalization. We experimentally show that flooding improves performance and as a byproduct, induces a double descent curve of the test loss.