 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Classification from Positive-Confidence Data
Paper and Code
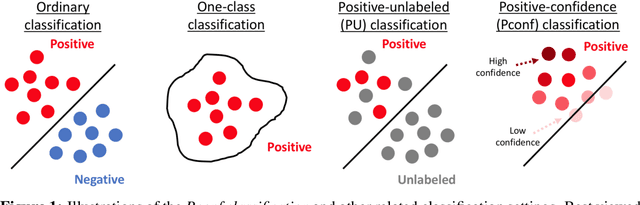



Reducing labeling costs in supervised learning is a critical issue in many practical machine learning applications. In this paper, we consider positive-confidence (Pconf) classification, the problem of training a binary classifier only from positive data equipped with confidence. Pconf classification can be regarded as a discriminative extension of one-class classification (which is aimed at "describing" the positive class by clustering-related methods), with ability to tune hyper-parameters for "classifying" positive and negative samples. Pconf classification is also related to positive-unlabeled (PU) classification (which uses hard-labeled positive data and unlabeled data), but the difference is that it enables us to avoid estimating the class priors, which is a critical bottleneck in typical PU classification methods. For the Pconf classification problem, we provide a simple empirical risk minimization framework and give a formulation for linear-in-parameter models that can be implemented easily and computationally efficiently. We also theoretically establish the consistency and estimation error bound for Pconf classification, and demonstrate the practical usefulness of the proposed method for deep neural networks through experiments.