 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDINET-Bench: Evaluating LLMs on Complex Financial Tasks using Japanese Financial Statements
Jun 10, 2025



Financial analysis presents complex challenges that could leverage large language model (LLM) capabilities. However, the scarcity of challenging financial datasets, particularly for Japanese financial data, impedes academic innovation in financial analytics. As LLMs advance, this lack of accessible research resources increasingly hinders their development and evaluation in this specialized domain. To address this gap, we introduce EDINET-Bench, an open-source Japanese financial benchmark designed to evaluate the performance of LLMs on challenging financial tasks including accounting fraud detection, earnings forecasting, and industry prediction. EDINET-Bench is constructed by downloading annual reports from the past 10 years from Japan's Electronic Disclosure for Investors' NETwork (EDINET) and automatically assigning labels corresponding to each evaluation task. Our experiments reveal that even state-of-the-art LLMs struggle, performing only slightly better than logistic regression in binary classification for fraud detection and earnings forecasting. These results highlight significant challenges in applying LLMs to real-world financial applications and underscore the need for domain-specific adaptation. Our dataset, benchmark construction code, and evaluation code is publicly available to facilitate future research in finance with LLMs.
PLaMo-100B: A Ground-Up Language Model Designed for Japanese Proficiency
Oct 10, 2024



We introduce PLaMo-100B, a large-scale language model designed for Japanese proficiency. The model was trained from scratch using 2 trillion tokens, with architecture such as QK Normalization and Z-Loss to ensure training stability during the training process. Post-training techniques, including Supervised Fine-Tuning and Direct Preference Optimization, were applied to refine the model's performance. Benchmark evaluations suggest that PLaMo-100B performs well, particularly in Japanese-specific tasks, achieving results that are competitive with frontier models like GPT-4.
GraphNVP: An Invertible Flow Model for Generating Molecular Graphs
May 28, 2019
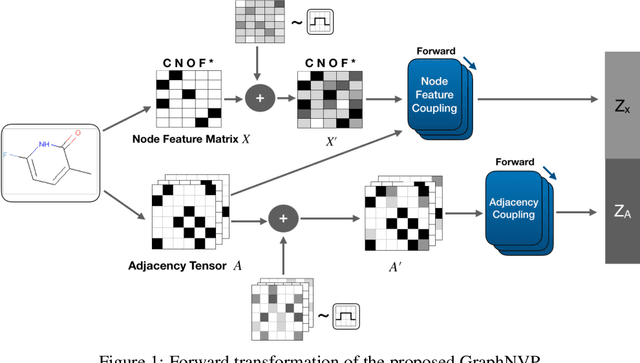
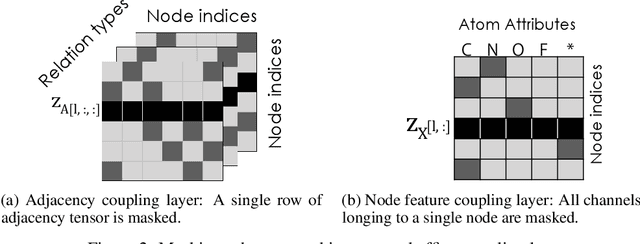
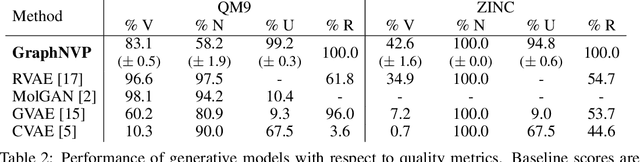
We propose GraphNVP, the first invertible, normalizing flow-based molecular graph generation model. We decompose the generation of a graph into two steps: generation of (i) an adjacency tensor and (ii) node attributes. This decomposition yields the exact likelihood maximization on graph-structured data, combined with two novel reversible flows. We empirically demonstrate that our model efficiently generates valid molecular graphs with almost no duplicated molecules. In addition, we observe that the learned latent space can be used to generate molecules with desired chemical properties.
BayesGrad: Explaining Predictions of Graph Convolutional Networks
Jul 04, 2018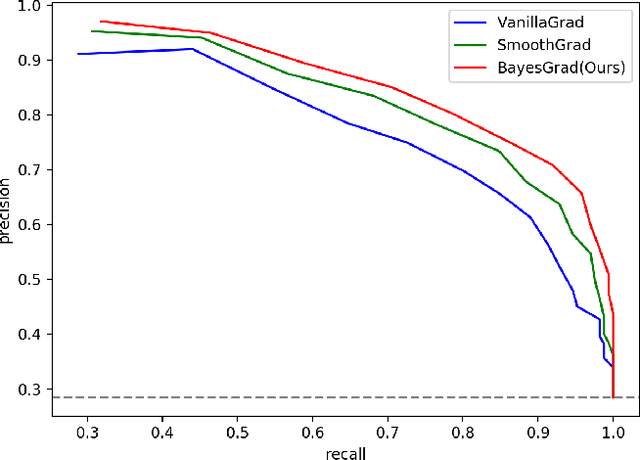
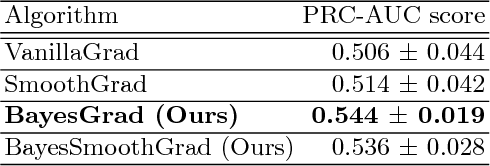
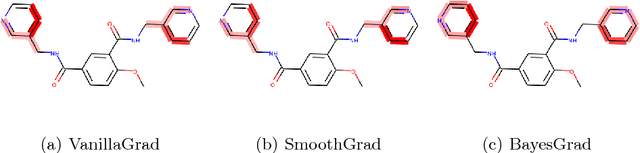
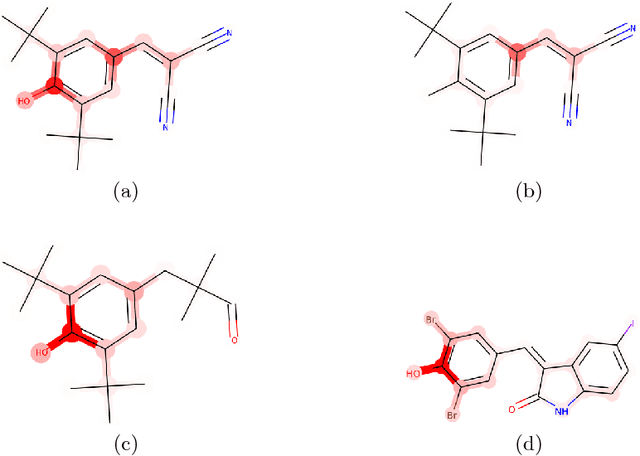
Recent advances in graph convolutional networks have significantly improved the performance of chemical predictions, raising a new research question: "how do we explain the predictions of graph convolutional networks?" A possible approach to answer this question is to visualize evidence substructures responsible for the predictions. For chemical property prediction tasks, the sample size of the training data is often small and/or a label imbalance problem occurs, where a few samples belong to a single class and the majority of samples belong to the other classes. This can lead to uncertainty related to the learned parameters of the machine learning model. To address this uncertainty, we propose BayesGrad, utilizing the Bayesian predictive distribution, to define the importance of each node in an input graph, which is computed efficiently using the dropout technique. We demonstrate that BayesGrad successfully visualizes the substructures responsible for the label prediction in the artificial experiment, even when the sample size is small. Furthermore, we use a real dataset to evaluate the effectiveness of the visualization. The basic idea of BayesGrad is not limited to graph-structured data and can be applied to other data types.