 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetAL: Active Semi-Supervised Learning on Graphs via Meta Learning
Jul 22, 2020
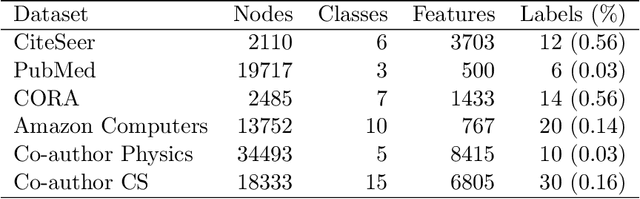
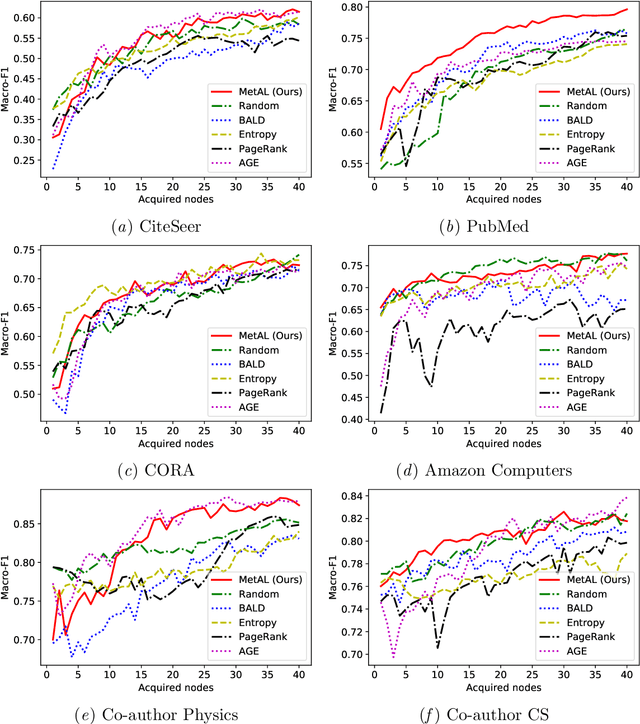

The objective of active learning (AL) is to train classification models with less number of labeled instances by selecting only the most informative instances for labeling. The AL algorithms designed for other data types such as images and text do not perform well on graph-structured data. Although a few heuristics-based AL algorithms have been proposed for graphs, a principled approach is lacking. In this paper, we propose MetAL, an AL approach that selects unlabeled instances that directly improve the future performance of a classification model. For a semi-supervised learning problem, we formulate the AL task as a bilevel optimization problem. Based on recent work in meta-learning, we use the meta-gradients to approximate the impact of retraining the model with any unlabeled instance on the model performance. Using multiple graph datasets belonging to different domains, we demonstrate that MetAL efficiently outperforms existing state-of-the-art AL algorithms.
GraphNVP: An Invertible Flow Model for Generating Molecular Graphs
May 28, 2019
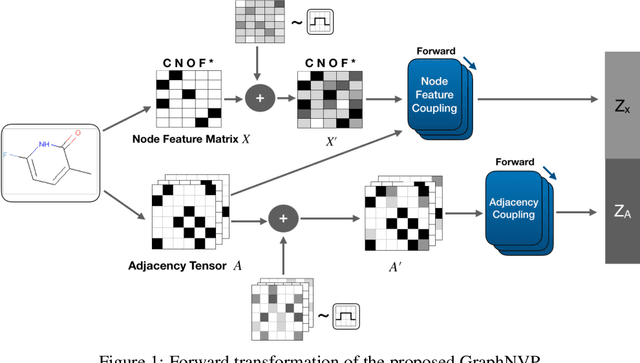
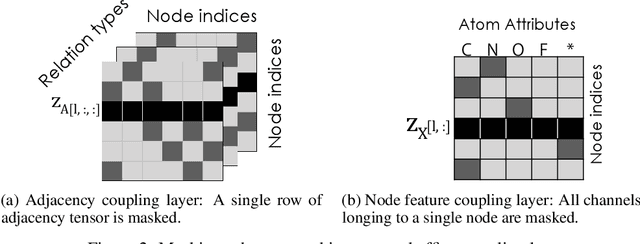
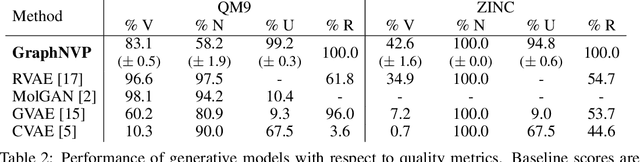
We propose GraphNVP, the first invertible, normalizing flow-based molecular graph generation model. We decompose the generation of a graph into two steps: generation of (i) an adjacency tensor and (ii) node attributes. This decomposition yields the exact likelihood maximization on graph-structured data, combined with two novel reversible flows. We empirically demonstrate that our model efficiently generates valid molecular graphs with almost no duplicated molecules. In addition, we observe that the learned latent space can be used to generate molecules with desired chemical properties.
Exploring Partially Observed Networks with Nonparametric Bandits
Apr 19, 2018



Real-world networks such as social and communication networks are too large to be observed entirely. Such networks are often partially observed such that network size, network topology, and nodes of the original network are unknown. In this paper we formalize the Adaptive Graph Exploring problem. We assume that we are given an incomplete snapshot of a large network and additional nodes can be discovered by querying nodes in the currently observed network. The goal of this problem is to maximize the number of observed nodes within a given query budget. Querying which set of nodes maximizes the size of the observed network? We formulate this problem as an exploration-exploitation problem and propose a novel nonparametric multi-arm bandit (MAB) algorithm for identifying which nodes to be queried. Our contributions include: (1) $i$KNN-UCB, a novel nonparametric MAB algorithm, applies $k$-nearest neighbor UCB to the setting when the arms are presented in a vector space, (2) provide theoretical guarantee that $i$KNN-UCB algorithm has sublinear regret, and (3) applying $i$KNN-UCB algorithm on synthetic networks and real-world networks from different domains, we show that our method discovers up to 40% more nodes compared to existing baselines.