 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRAVA-GNN: Betweenness Ranking Approximation Via Degree MAss Inspired Graph Neural Network
Feb 10, 2026Computing node importance in networks is a long-standing fundamental problem that has driven extensive study of various centrality measures. A particularly well-known centrality measure is betweenness centrality, which becomes computationally prohibitive on large-scale networks. Graph Neural Network (GNN) models have thus been proposed to predict node rankings according to their relative betweenness centrality. However, state-of-the-art methods fail to generalize to high-diameter graphs such as road networks. We propose BRAVA-GNN, a lightweight GNN architecture that leverages the empirically observed correlation linking betweenness centrality to degree-based quantities, in particular multi-hop degree mass. This correlation motivates the use of degree masses as size-invariant node features and synthetic training graphs that closely match the degree distributions of real networks. Furthermore, while previous work relies on scale-free synthetic graphs, we leverage the hyperbolic random graph model, which reproduces power-law exponents outside the scale-free regime, better capturing the structure of real-world graphs like road networks. This design enables BRAVA-GNN to generalize across diverse graph families while using 54x fewer parameters than the most lightweight existing GNN baseline. Extensive experiments on 19 real-world networks, spanning social, web, email, and road graphs, show that BRAVA-GNN achieves up to 214% improvement in Kendall-Tau correlation and up to 70x speedup in inference time over state-of-the-art GNN-based approaches, particularly on challenging road networks.
DEGNN: Dual Experts Graph Neural Network Handling Both Edge and Node Feature Noise
Apr 14, 2024Graph Neural Networks (GNNs) have achieved notable success in various applications over graph data. However, recent research has revealed that real-world graphs often contain noise, and GNNs are susceptible to noise in the graph. To address this issue, several Graph Structure Learning (GSL) models have been introduced. While GSL models are tailored to enhance robustness against edge noise through edge reconstruction, a significant limitation surfaces: their high reliance on node features. This inherent dependence amplifies their susceptibility to noise within node features. Recognizing this vulnerability, we present DEGNN, a novel GNN model designed to adeptly mitigate noise in both edges and node features. The core idea of DEGNN is to design two separate experts: an edge expert and a node feature expert. These experts utilize self-supervised learning techniques to produce modified edges and node features. Leveraging these modified representations, DEGNN subsequently addresses downstream tasks, ensuring robustness against noise present in both edges and node features of real-world graphs. Notably, the modification process can be trained end-to-end, empowering DEGNN to adjust dynamically and achieves optimal edge and node representations for specific tasks. Comprehensive experiments demonstrate DEGNN's efficacy in managing noise, both in original real-world graphs and in graphs with synthetic noise.
Future-Proofing Class Incremental Learning
Apr 04, 2024Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
Class-Incremental Learning using Diffusion Model for Distillation and Replay
Jun 30, 2023
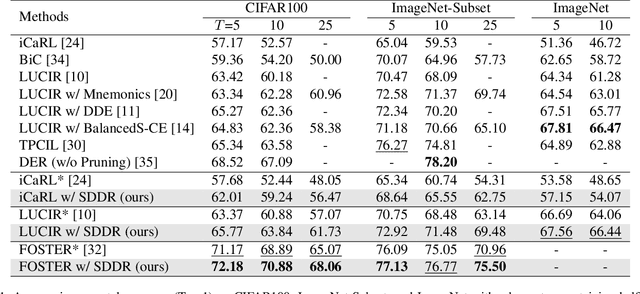
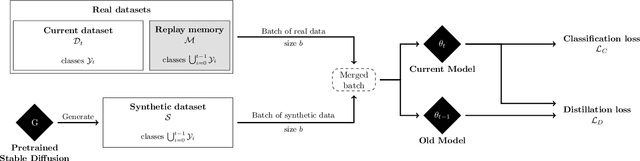
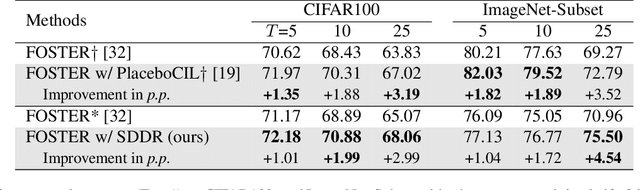
Class-incremental learning aims to learn new classes in an incremental fashion without forgetting the previously learned ones. Several research works have shown how additional data can be used by incremental models to help mitigate catastrophic forgetting. In this work, following the recent breakthrough in text-to-image generative models and their wide distribution, we propose the use of a pretrained Stable Diffusion model as a source of additional data for class-incremental learning. Compared to competitive methods that rely on external, often unlabeled, datasets of real images, our approach can generate synthetic samples belonging to the same classes as the previously encountered images. This allows us to use those additional data samples not only in the distillation loss but also for replay in the classification loss. Experiments on the competitive benchmarks CIFAR100, ImageNet-Subset, and ImageNet demonstrate how this new approach can be used to further improve the performance of state-of-the-art methods for class-incremental learning on large scale datasets.
Modularity Optimization as a Training Criterion for Graph Neural Networks
Jun 30, 2022Graph convolution is a recent scalable method for performing deep feature learning on attributed graphs by aggregating local node information over multiple layers. Such layers only consider attribute information of node neighbors in the forward model and do not incorporate knowledge of global network structure in the learning task. In particular, the modularity function provides a convenient source of information about the community structure of networks. In this work we investigate the effect on the quality of learned representations by the incorporation of community structure preservation objectives of networks in the graph convolutional model. We incorporate the objectives in two ways, through an explicit regularization term in the cost function in the output layer and as an additional loss term computed via an auxiliary layer. We report the effect of community structure preserving terms in the graph convolutional architectures. Experimental evaluation on two attributed bibilographic networks showed that the incorporation of the community-preserving objective improves semi-supervised node classification accuracy in the sparse label regime.
* CompleNet 2018
Leaping Through Time with Gradient-based Adaptation for Recommendation
Dec 28, 2021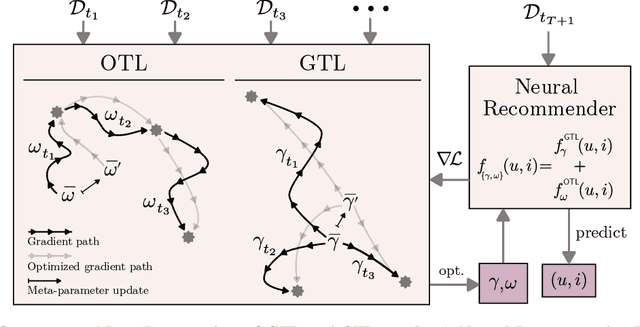
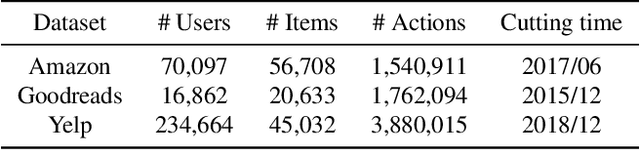
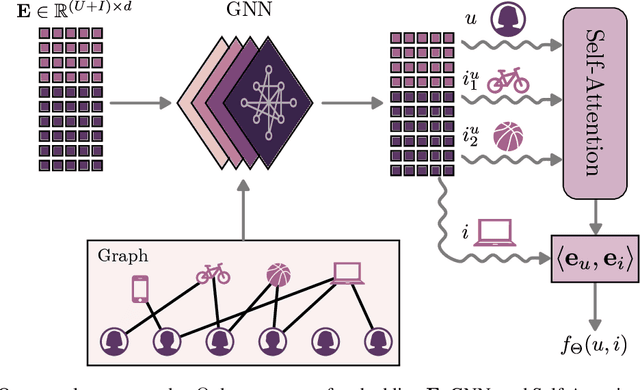
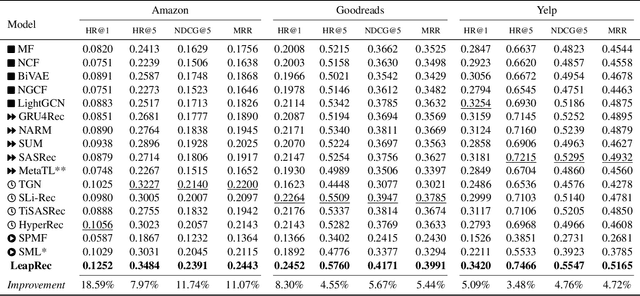
Modern recommender systems are required to adapt to the change in user preferences and item popularity. Such a problem is known as the temporal dynamics problem, and it is one of the main challenges in recommender system modeling. Different from the popular recurrent modeling approach, we propose a new solution named LeapRec to the temporal dynamic problem by using trajectory-based meta-learning to model time dependencies. LeapRec characterizes temporal dynamics by two complement components named global time leap (GTL) and ordered time leap (OTL). By design, GTL learns long-term patterns by finding the shortest learning path across unordered temporal data. Cooperatively, OTL learns short-term patterns by considering the sequential nature of the temporal data. Our experimental results show that LeapRec consistently outperforms the state-of-the-art methods on several datasets and recommendation metrics. Furthermore, we provide an empirical study of the interaction between GTL and OTL, showing the effects of long- and short-term modeling.
Simplifying approach to Node Classification in Graph Neural Networks
Nov 12, 2021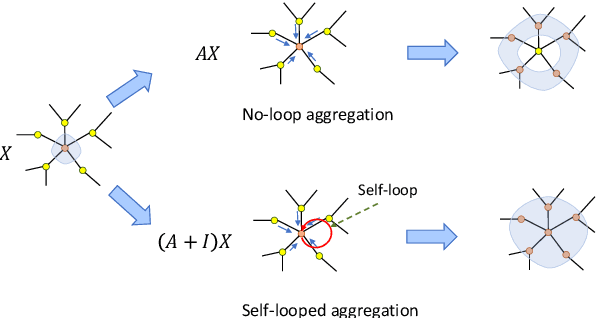
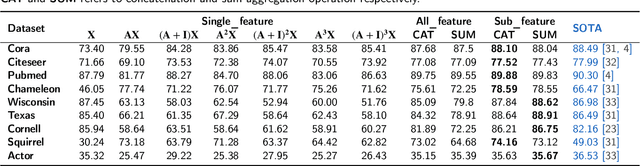
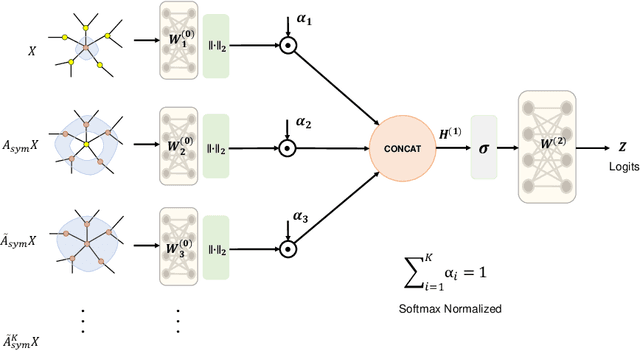
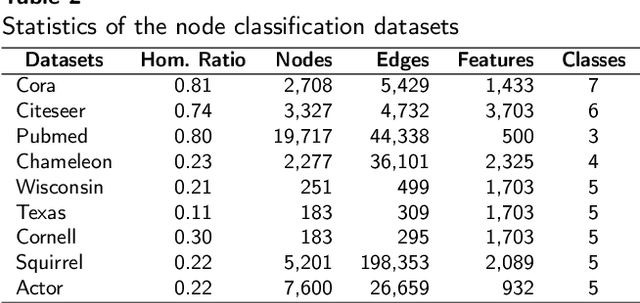
Graph Neural Networks have become one of the indispensable tools to learn from graph-structured data, and their usefulness has been shown in wide variety of tasks. In recent years, there have been tremendous improvements in architecture design, resulting in better performance on various prediction tasks. In general, these neural architectures combine node feature aggregation and feature transformation using learnable weight matrix in the same layer. This makes it challenging to analyze the importance of node features aggregated from various hops and the expressiveness of the neural network layers. As different graph datasets show varying levels of homophily and heterophily in features and class label distribution, it becomes essential to understand which features are important for the prediction tasks without any prior information. In this work, we decouple the node feature aggregation step and depth of graph neural network, and empirically analyze how different aggregated features play a role in prediction performance. We show that not all features generated via aggregation steps are useful, and often using these less informative features can be detrimental to the performance of the GNN model. Through our experiments, we show that learning certain subsets of these features can lead to better performance on wide variety of datasets. We propose to use softmax as a regularizer and "soft-selector" of features aggregated from neighbors at different hop distances; and L2-Normalization over GNN layers. Combining these techniques, we present a simple and shallow model, Feature Selection Graph Neural Network (FSGNN), and show empirically that the proposed model achieves comparable or even higher accuracy than state-of-the-art GNN models in nine benchmark datasets for the node classification task, with remarkable improvements up to 51.1%.
Natural Image Reconstruction from fMRI using Deep Learning: A Survey
Oct 18, 2021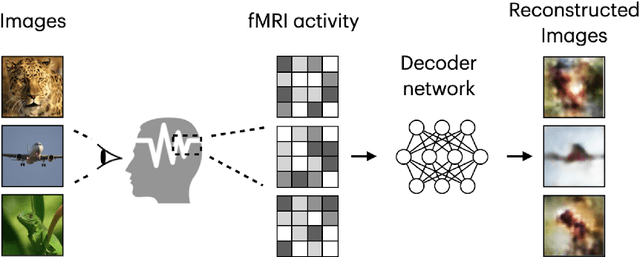


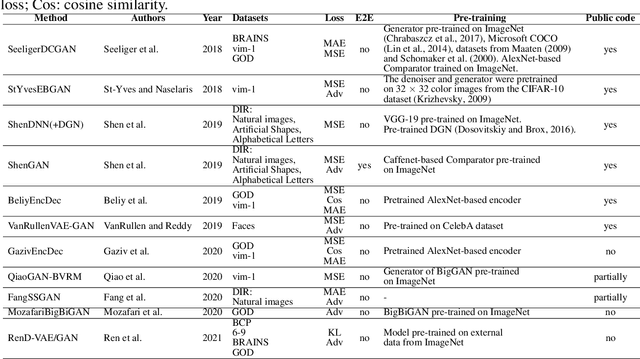
With the advent of brain imaging techniques and machine learning tools, much effort has been devoted to building computational models to capture the encoding of visual information in the human brain. One of the most challenging brain decoding tasks is the accurate reconstruction of the perceived natural images from brain activities measured by functional magnetic resonance imaging (fMRI). In this work, we survey the most recent deep learning methods for natural image reconstruction from fMRI. We examine these methods in terms of architectural design, benchmark datasets, and evaluation metrics and present a fair performance evaluation across standardized evaluation metrics. Finally, we discuss the strengths and limitations of existing studies and present potential future directions.
Cross-lingual Transfer for Text Classification with Dictionary-based Heterogeneous Graph
Sep 10, 2021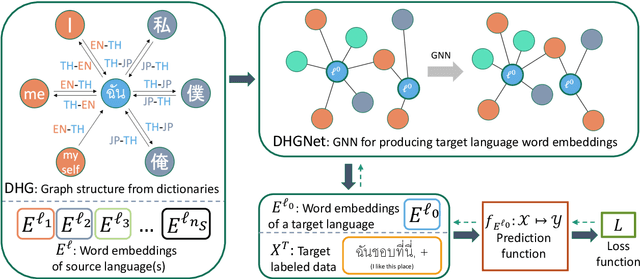
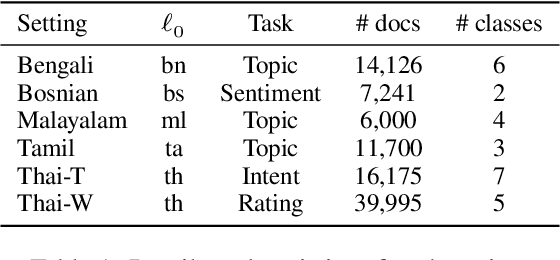
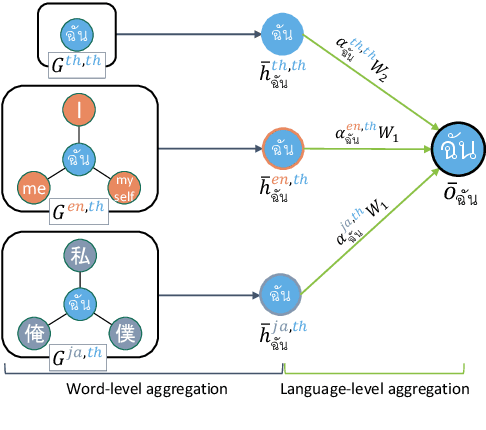
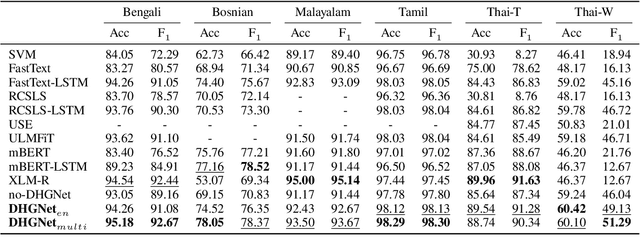
In cross-lingual text classification, it is required that task-specific training data in high-resource source languages are available, where the task is identical to that of a low-resource target language. However, collecting such training data can be infeasible because of the labeling cost, task characteristics, and privacy concerns. This paper proposes an alternative solution that uses only task-independent word embeddings of high-resource languages and bilingual dictionaries. First, we construct a dictionary-based heterogeneous graph (DHG) from bilingual dictionaries. This opens the possibility to use graph neural networks for cross-lingual transfer. The remaining challenge is the heterogeneity of DHG because multiple languages are considered. To address this challenge, we propose dictionary-based heterogeneous graph neural network (DHGNet) that effectively handles the heterogeneity of DHG by two-step aggregations, which are word-level and language-level aggregations. Experimental results demonstrate that our method outperforms pretrained models even though it does not access to large corpora. Furthermore, it can perform well even though dictionaries contain many incorrect translations. Its robustness allows the usage of a wider range of dictionaries such as an automatically constructed dictionary and crowdsourced dictionary, which are convenient for real-world applications.
Improving Graph Neural Networks with Simple Architecture Design
May 17, 2021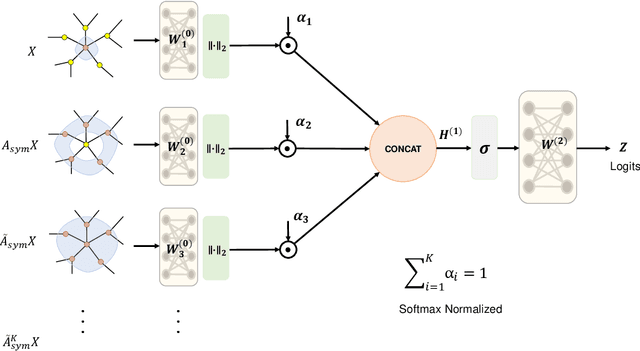
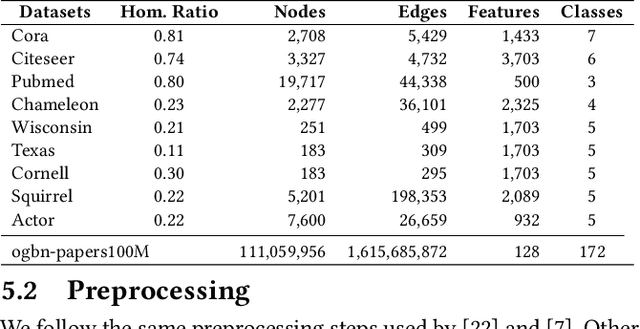
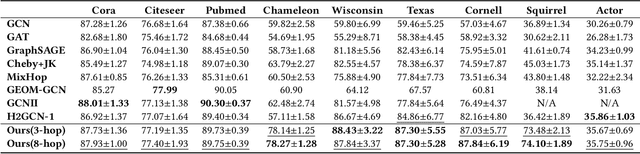

Graph Neural Networks have emerged as a useful tool to learn on the data by applying additional constraints based on the graph structure. These graphs are often created with assumed intrinsic relations between the entities. In recent years, there have been tremendous improvements in the architecture design, pushing the performance up in various prediction tasks. In general, these neural architectures combine layer depth and node feature aggregation steps. This makes it challenging to analyze the importance of features at various hops and the expressiveness of the neural network layers. As different graph datasets show varying levels of homophily and heterophily in features and class label distribution, it becomes essential to understand which features are important for the prediction tasks without any prior information. In this work, we decouple the node feature aggregation step and depth of graph neural network and introduce several key design strategies for graph neural networks. More specifically, we propose to use softmax as a regularizer and "Soft-Selector" of features aggregated from neighbors at different hop distances; and "Hop-Normalization" over GNN layers. Combining these techniques, we present a simple and shallow model, Feature Selection Graph Neural Network (FSGNN), and show empirically that the proposed model outperforms other state of the art GNN models and achieves up to 64% improvements in accuracy on node classification tasks. Moreover, analyzing the learned soft-selection parameters of the model provides a simple way to study the importance of features in the prediction tasks. Finally, we demonstrate with experiments that the model is scalable for large graphs with millions of nodes and billions of edges.