 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Transformers Learn to Verify During Backtracking Search?
May 21, 2026Backtracking search underlies classical constraint solvers, planners, and theorem provers. Recent transformer-based reasoning systems explore search trees over their own intermediate steps. A common training recipe fits an autoregressive next-token loss on offline solver traces. The model's input at each step is a cumulative trace of all prior decisions. The optimal continue-or-backtrack predictor depends only on the current search state, since two trajectories reaching the same state admit the same viable continuations. We show that decoder-only transformers trained on cumulative traces fail this requirement in two ways: the trace can scatter state features across many positions (scattered retrieval), and the predictor can condition on the trajectory rather than the state (history entanglement). We address scattered retrieval with localization, a trace-level fix that rewrites each decision block to expose state features locally. We address history entanglement with Selective State Attention (SSA), a fixed attention mask that enforces state-based decisions structurally without modifying training data, objective, or parameters. We focus on reactive verification, after propagation has exposed a contradiction. We test SSA on 3-SAT, graph coloring, Blocks World, and backtracking parsing. On same-state pairs that differ only in prior history, SSA emits identical decisions while a cumulative-trained causal baseline does not. Our contribution is a diagnostic of transformer behavior on serialized trajectory data, paired with a structural fix. Pretrained language models that search over their own reasoning steps may face the same failure. Our analysis opens up inference-time context clearing as a candidate way to apply the same isolation without retraining.
A Foundation Model for Zero-Shot Logical Rule Induction
May 06, 2026Inductive Logic Programming (ILP) learns interpretable logical rules from data. Existing methods are transductive: their learned parameters are bound to specific predicates and require retraining for each new task. We introduce Neural Rule Inducer (NRI), a pretrained model for zero-shot rule induction. Rather than encoding literal identities, NRI represents literals using domain-agnostic statistical properties such as class-conditional rates, entropy, and co-occurrence, which generalize across variable identities and counts without retraining. The model consists of a statistical encoder and a parallel slot-based decoder. Parallel decoding preserves the permutation invariance of logical disjunction; an autoregressive decoder would instead impose an arbitrary clause order. Product T-norm relaxation makes rule execution differentiable, allowing end-to-end training on prediction accuracy alone. We evaluate NRI on rule recovery, robustness to label noise and spurious correlations, and zero-shot transfer to real-world benchmarks, and we believe this work opens up the possibility of foundation models for symbolic reasoning. Code and the reference checkpoint are available at https://github.com/phuayj/neural-rule-inducer.
Can We Test Consciousness Theories on AI? Ablations, Markers, and Robustness
Dec 22, 2025The search for reliable indicators of consciousness has fragmented into competing theoretical camps (Global Workspace Theory (GWT), Integrated Information Theory (IIT), and Higher-Order Theories (HOT)), each proposing distinct neural signatures. We adopt a synthetic neuro-phenomenology approach: constructing artificial agents that embody these mechanisms to test their functional consequences through precise architectural ablations impossible in biological systems. Across three experiments, we report dissociations suggesting these theories describe complementary functional layers rather than competing accounts. In Experiment 1, a no-rewire Self-Model lesion abolishes metacognitive calibration while preserving first-order task performance, yielding a synthetic blindsight analogue consistent with HOT predictions. In Experiment 2, workspace capacity proves causally necessary for information access: a complete workspace lesion produces qualitative collapse in access-related markers, while partial reductions show graded degradation, consistent with GWT's ignition framework. In Experiment 3, we uncover a broadcast-amplification effect: GWT-style broadcasting amplifies internal noise, creating extreme fragility. The B2 agent family is robust to the same latent perturbation; this robustness persists in a Self-Model-off / workspace-read control, cautioning against attributing the effect solely to $z_{\text{self}}$ compression. We also report an explicit negative result: raw perturbational complexity (PCI-A) decreases under the workspace bottleneck, cautioning against naive transfer of IIT-adjacent proxies to engineered agents. These results suggest a hierarchical design principle: GWT provides broadcast capacity, while HOT provides quality control. We emphasize that our agents are not conscious; they are reference implementations for testing functional predictions of consciousness theories.
Variable Assignment Invariant Neural Networks for Learning Logic Programs
Aug 20, 2024Learning from interpretation transition (LFIT) is a framework for learning rules from observed state transitions. LFIT has been implemented in purely symbolic algorithms, but they are unable to deal with noise or generalize to unobserved transitions. Rule extraction based neural network methods suffer from overfitting, while more general implementation that categorize rules suffer from combinatorial explosion. In this paper, we introduce a technique to leverage variable permutation invariance inherent in symbolic domains. Our technique ensures that the permutation and the naming of the variables would not affect the results. We demonstrate the effectiveness and the scalability of this method with various experiments. Our code is publicly available at https://github.com/phuayj/delta-lfit-2
DEGNN: Dual Experts Graph Neural Network Handling Both Edge and Node Feature Noise
Apr 14, 2024Graph Neural Networks (GNNs) have achieved notable success in various applications over graph data. However, recent research has revealed that real-world graphs often contain noise, and GNNs are susceptible to noise in the graph. To address this issue, several Graph Structure Learning (GSL) models have been introduced. While GSL models are tailored to enhance robustness against edge noise through edge reconstruction, a significant limitation surfaces: their high reliance on node features. This inherent dependence amplifies their susceptibility to noise within node features. Recognizing this vulnerability, we present DEGNN, a novel GNN model designed to adeptly mitigate noise in both edges and node features. The core idea of DEGNN is to design two separate experts: an edge expert and a node feature expert. These experts utilize self-supervised learning techniques to produce modified edges and node features. Leveraging these modified representations, DEGNN subsequently addresses downstream tasks, ensuring robustness against noise present in both edges and node features of real-world graphs. Notably, the modification process can be trained end-to-end, empowering DEGNN to adjust dynamically and achieves optimal edge and node representations for specific tasks. Comprehensive experiments demonstrate DEGNN's efficacy in managing noise, both in original real-world graphs and in graphs with synthetic noise.
Future-Proofing Class Incremental Learning
Apr 04, 2024Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
Class-Incremental Learning using Diffusion Model for Distillation and Replay
Jun 30, 2023
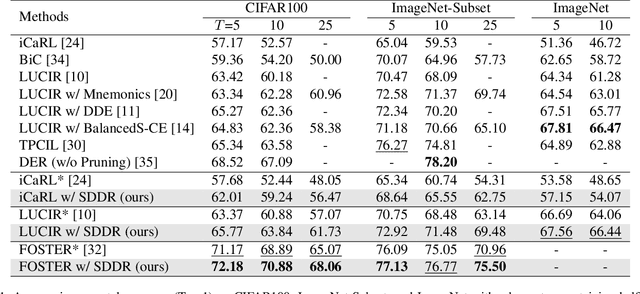
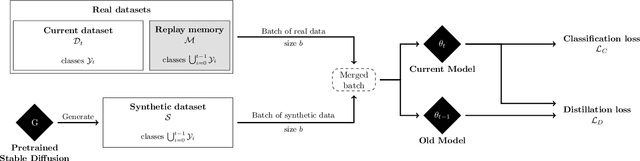
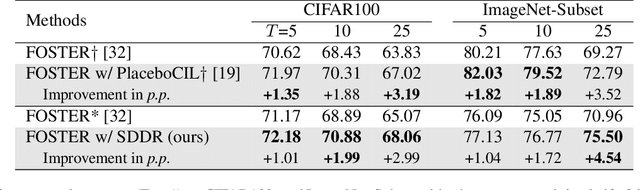
Class-incremental learning aims to learn new classes in an incremental fashion without forgetting the previously learned ones. Several research works have shown how additional data can be used by incremental models to help mitigate catastrophic forgetting. In this work, following the recent breakthrough in text-to-image generative models and their wide distribution, we propose the use of a pretrained Stable Diffusion model as a source of additional data for class-incremental learning. Compared to competitive methods that rely on external, often unlabeled, datasets of real images, our approach can generate synthetic samples belonging to the same classes as the previously encountered images. This allows us to use those additional data samples not only in the distillation loss but also for replay in the classification loss. Experiments on the competitive benchmarks CIFAR100, ImageNet-Subset, and ImageNet demonstrate how this new approach can be used to further improve the performance of state-of-the-art methods for class-incremental learning on large scale datasets.