 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture-Proofing Class Incremental Learning
Apr 04, 2024Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
Class-Incremental Learning using Diffusion Model for Distillation and Replay
Jun 30, 2023
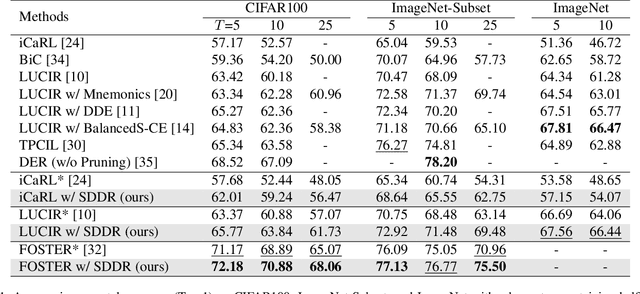
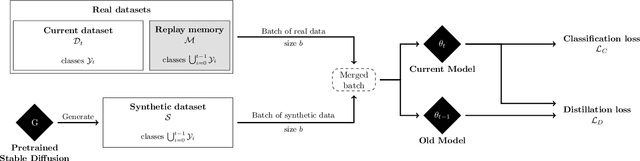
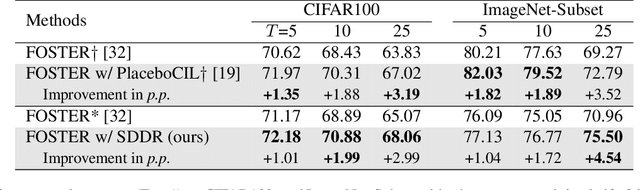
Class-incremental learning aims to learn new classes in an incremental fashion without forgetting the previously learned ones. Several research works have shown how additional data can be used by incremental models to help mitigate catastrophic forgetting. In this work, following the recent breakthrough in text-to-image generative models and their wide distribution, we propose the use of a pretrained Stable Diffusion model as a source of additional data for class-incremental learning. Compared to competitive methods that rely on external, often unlabeled, datasets of real images, our approach can generate synthetic samples belonging to the same classes as the previously encountered images. This allows us to use those additional data samples not only in the distillation loss but also for replay in the classification loss. Experiments on the competitive benchmarks CIFAR100, ImageNet-Subset, and ImageNet demonstrate how this new approach can be used to further improve the performance of state-of-the-art methods for class-incremental learning on large scale datasets.
Natural Image Reconstruction from fMRI using Deep Learning: A Survey
Oct 18, 2021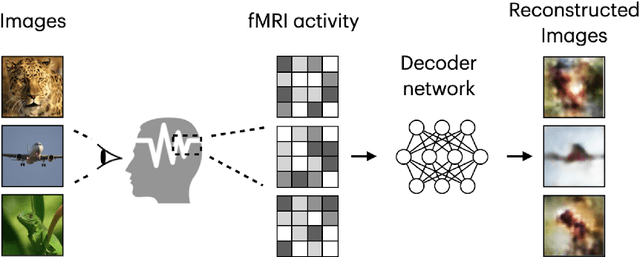


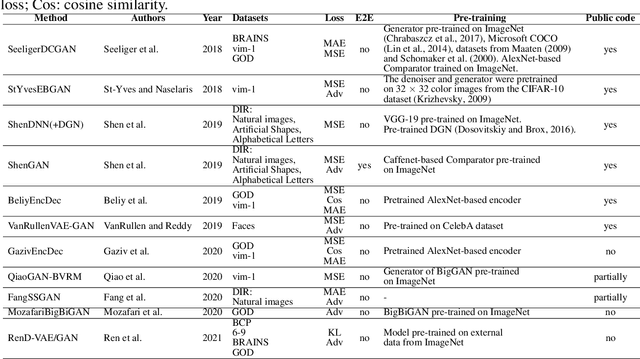
With the advent of brain imaging techniques and machine learning tools, much effort has been devoted to building computational models to capture the encoding of visual information in the human brain. One of the most challenging brain decoding tasks is the accurate reconstruction of the perceived natural images from brain activities measured by functional magnetic resonance imaging (fMRI). In this work, we survey the most recent deep learning methods for natural image reconstruction from fMRI. We examine these methods in terms of architectural design, benchmark datasets, and evaluation metrics and present a fair performance evaluation across standardized evaluation metrics. Finally, we discuss the strengths and limitations of existing studies and present potential future directions.
Balanced Softmax Cross-Entropy for Incremental Learning
Mar 31, 2021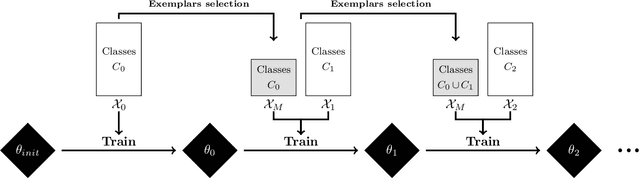
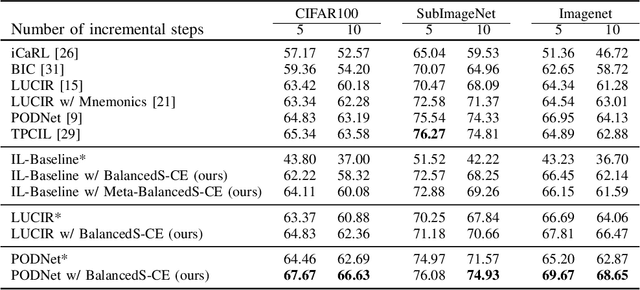
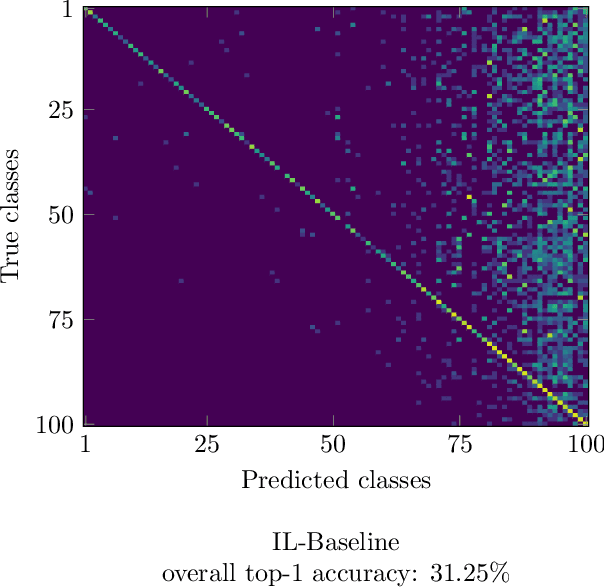
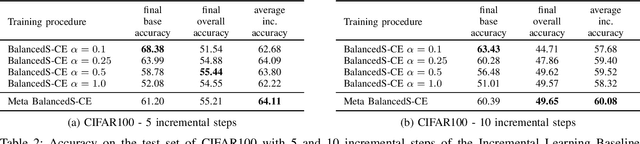
Deep neural networks are prone to catastrophic forgetting when incrementally trained on new classes or new tasks as adaptation to the new data leads to a drastic decrease of the performance on the old classes and tasks. By using a small memory for rehearsal and knowledge distillation, recent methods have proven to be effective to mitigate catastrophic forgetting. However due to the limited size of the memory, large imbalance between the amount of data available for the old and new classes still remains which results in a deterioration of the overall accuracy of the model. To address this problem, we propose the use of the Balanced Softmax Cross-Entropy loss and show that it can be combined with exiting methods for incremental learning to improve their performances while also decreasing the computational cost of the training procedure in some cases. Complete experiments on the competitive ImageNet, subImageNet and CIFAR100 datasets show states-of-the-art results.
CVPR 2020 Continual Learning in Computer Vision Competition: Approaches, Results, Current Challenges and Future Directions
Sep 14, 2020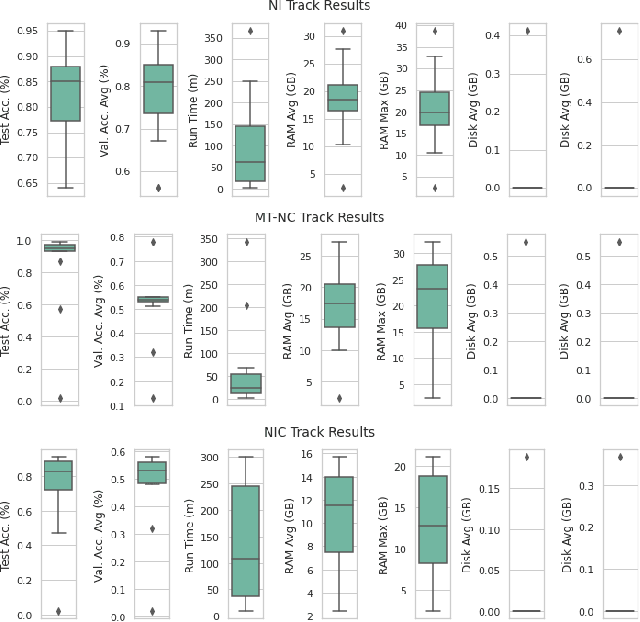

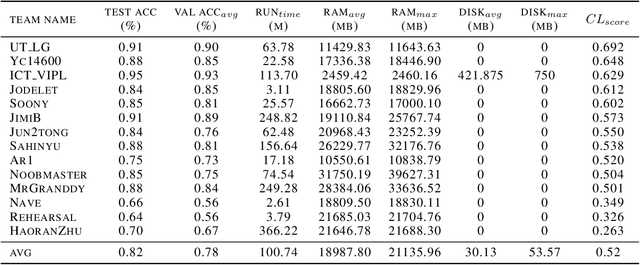
In the last few years, we have witnessed a renewed and fast-growing interest in continual learning with deep neural networks with the shared objective of making current AI systems more adaptive, efficient and autonomous. However, despite the significant and undoubted progress of the field in addressing the issue of catastrophic forgetting, benchmarking different continual learning approaches is a difficult task by itself. In fact, given the proliferation of different settings, training and evaluation protocols, metrics and nomenclature, it is often tricky to properly characterize a continual learning algorithm, relate it to other solutions and gauge its real-world applicability. The first Continual Learning in Computer Vision challenge held at CVPR in 2020 has been one of the first opportunities to evaluate different continual learning algorithms on a common hardware with a large set of shared evaluation metrics and 3 different settings based on the realistic CORe50 video benchmark. In this paper, we report the main results of the competition, which counted more than 79 teams registered, 11 finalists and 2300$ in prizes. We also summarize the winning approaches, current challenges and future research directions.
Transfer Learning with Sparse Associative Memories
Apr 04, 2019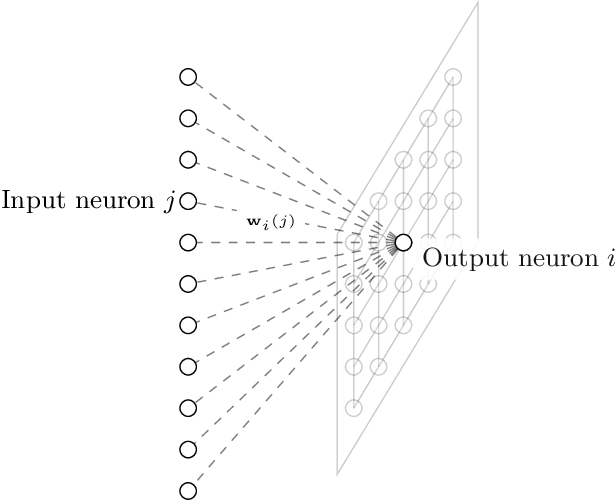
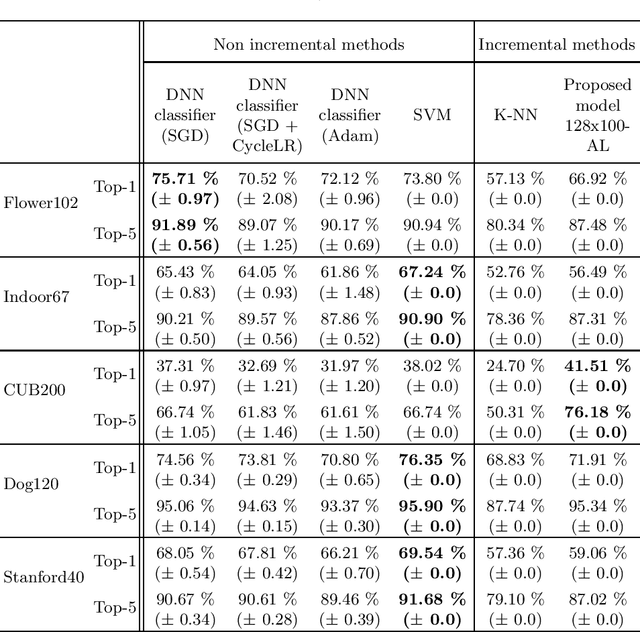
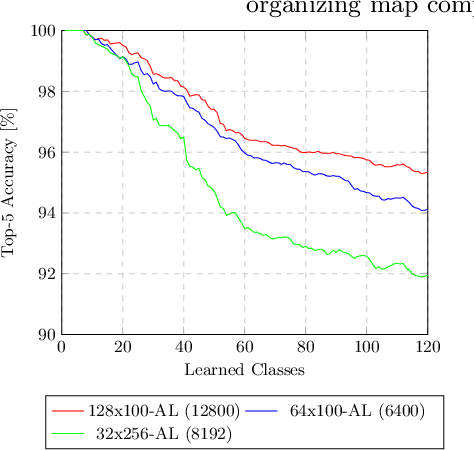
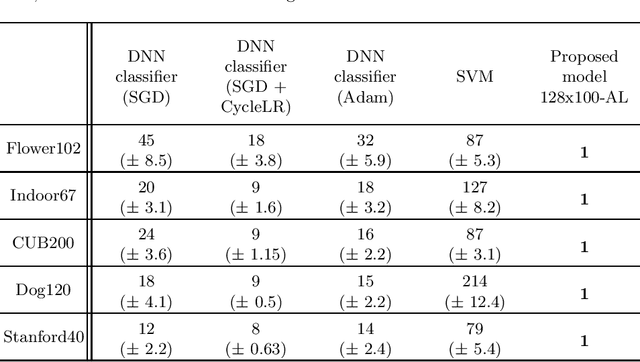
In this paper, we introduce a novel layer designed to be used as the output of pre-trained neural networks in the context of classification. Based on Associative Memories, this layer can help design Deep Neural Networks which support incremental learning and that can be (partially) trained in real time on embedded devices. Experiments on the ImageNet dataset and other different domain specific datasets show that it is possible to design more flexible and faster-to-train Neural Networks at the cost of a slight decrease in accuracy.