 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning with Sparse Associative Memories
Apr 04, 2019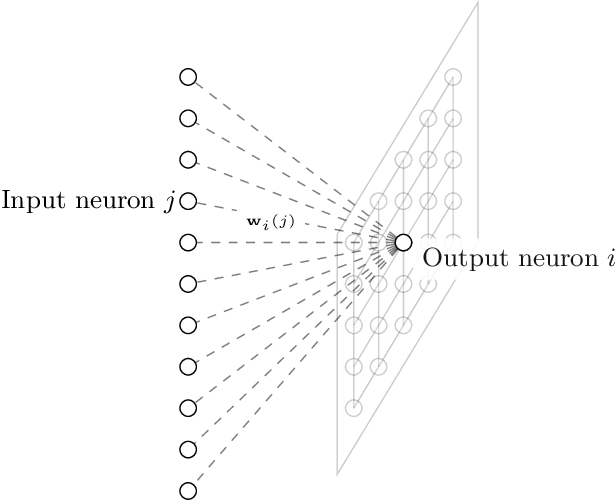
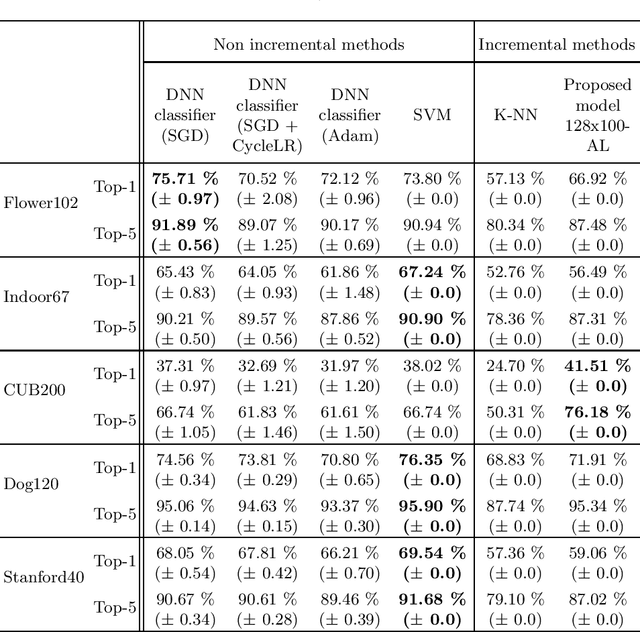
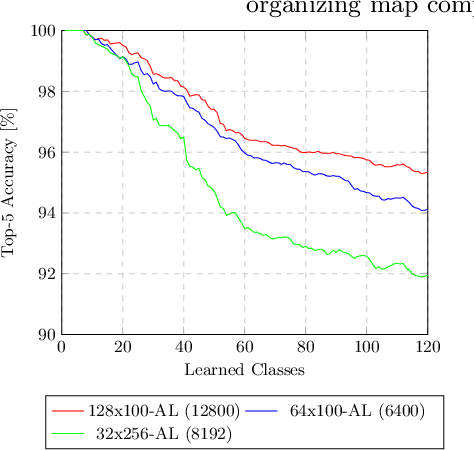
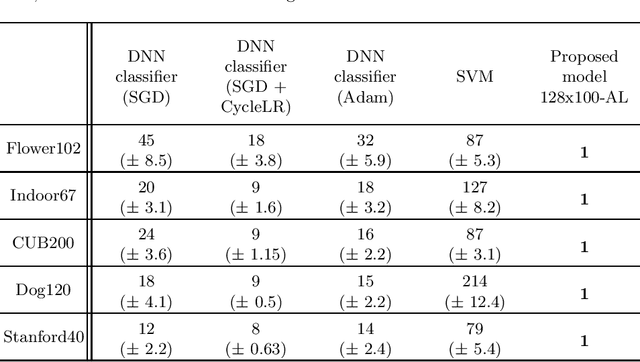
In this paper, we introduce a novel layer designed to be used as the output of pre-trained neural networks in the context of classification. Based on Associative Memories, this layer can help design Deep Neural Networks which support incremental learning and that can be (partially) trained in real time on embedded devices. Experiments on the ImageNet dataset and other different domain specific datasets show that it is possible to design more flexible and faster-to-train Neural Networks at the cost of a slight decrease in accuracy.
Fuzzy paraphrases in learning word representations with a lexicon
Sep 08, 2017
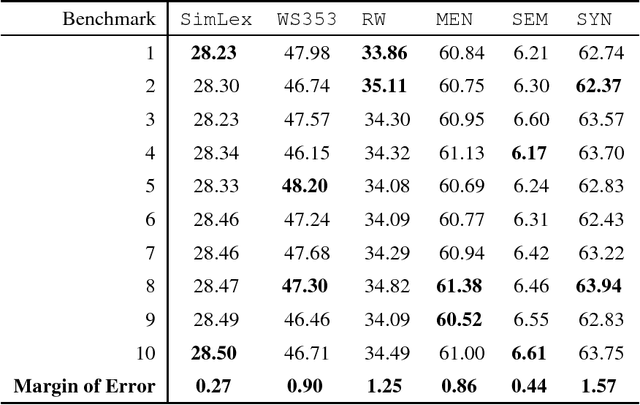
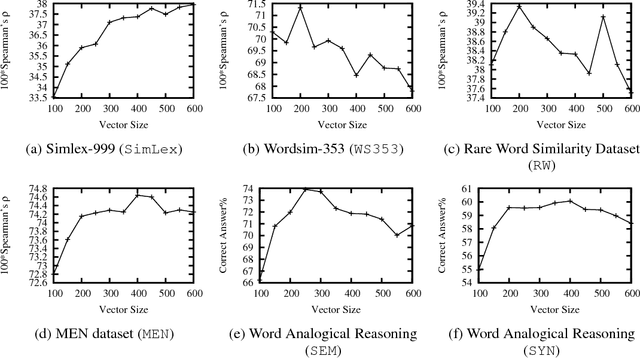

A synonym of a polysemous word is usually only the paraphrase of one sense among many. When lexicons are used to improve vector-space word representations, such paraphrases are unreliable and bring noise to the vector-space. The prior works use a coefficient to adjust the overall learning of the lexicons. They regard the paraphrases equally. In this paper, we propose a novel approach that regards the paraphrases diversely to alleviate the adverse effects of polysemy. We annotate each paraphrase with a degree of reliability. The paraphrases are randomly eliminated according to the degrees when our model learns word representations. In this way, our approach drops the unreliable paraphrases, keeping more reliable paraphrases at the same time. The experimental results show that the proposed method improves the word vectors. Our approach is an attempt to address the polysemy problem keeping one vector per word. It makes the approach easier to use than the conventional methods that estimate multiple vectors for a word. Our approach also outperforms the prior works in the experiments.
Radical-level Ideograph Encoder for RNN-based Sentiment Analysis of Chinese and Japanese
Aug 10, 2017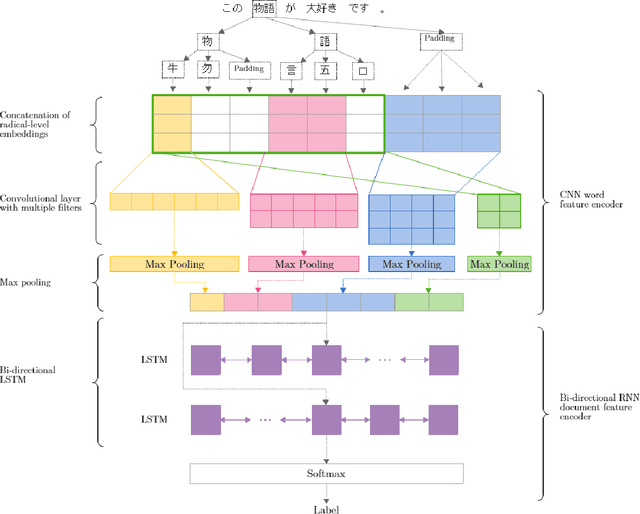

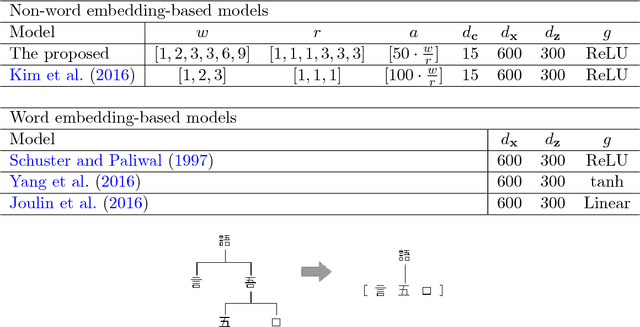
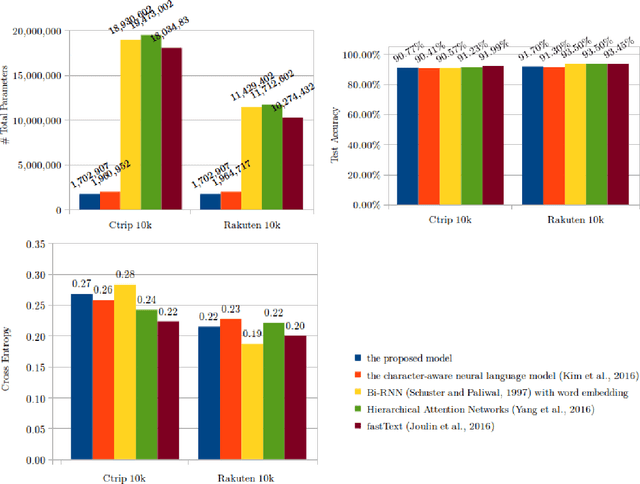
The character vocabulary can be very large in non-alphabetic languages such as Chinese and Japanese, which makes neural network models huge to process such languages. We explored a model for sentiment classification that takes the embeddings of the radicals of the Chinese characters, i.e, hanzi of Chinese and kanji of Japanese. Our model is composed of a CNN word feature encoder and a bi-directional RNN document feature encoder. The results achieved are on par with the character embedding-based models, and close to the state-of-the-art word embedding-based models, with 90% smaller vocabulary, and at least 13% and 80% fewer parameters than the character embedding-based models and word embedding-based models respectively. The results suggest that the radical embedding-based approach is cost-effective for machine learning on Chinese and Japanese.
Improve Lexicon-based Word Embeddings By Word Sense Disambiguation
Jul 24, 2017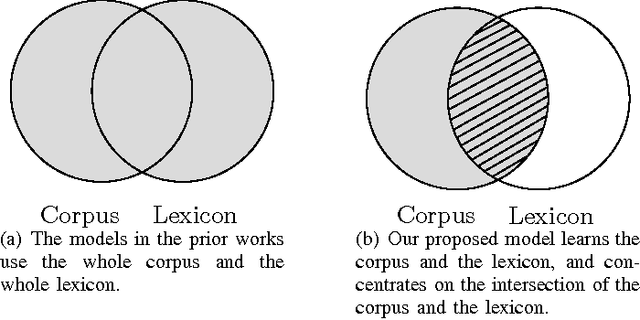
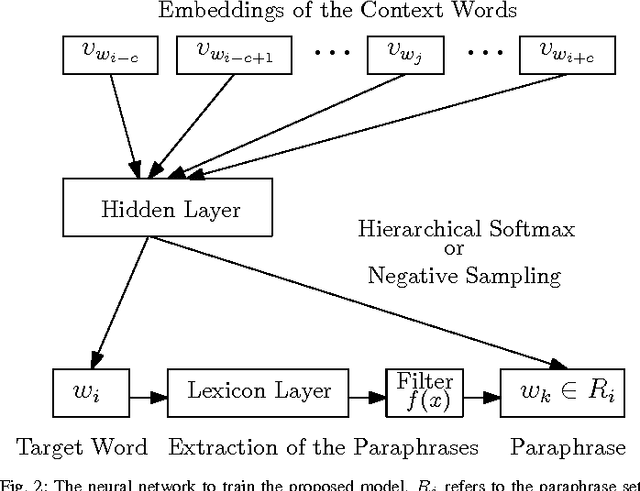
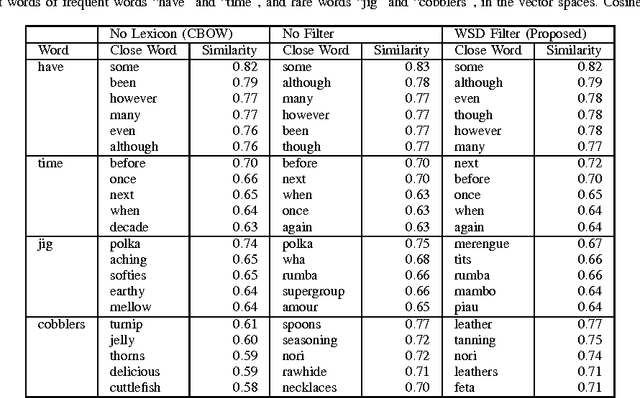

There have been some works that learn a lexicon together with the corpus to improve the word embeddings. However, they either model the lexicon separately but update the neural networks for both the corpus and the lexicon by the same likelihood, or minimize the distance between all of the synonym pairs in the lexicon. Such methods do not consider the relatedness and difference of the corpus and the lexicon, and may not be the best optimized. In this paper, we propose a novel method that considers the relatedness and difference of the corpus and the lexicon. It trains word embeddings by learning the corpus to predicate a word and its corresponding synonym under the context at the same time. For polysemous words, we use a word sense disambiguation filter to eliminate the synonyms that have different meanings for the context. To evaluate the proposed method, we compare the performance of the word embeddings trained by our proposed model, the control groups without the filter or the lexicon, and the prior works in the word similarity tasks and text classification task. The experimental results show that the proposed model provides better embeddings for polysemous words and improves the performance for text classification.
Alleviating Overfitting for Polysemous Words for Word Representation Estimation Using Lexicons
Mar 09, 2017
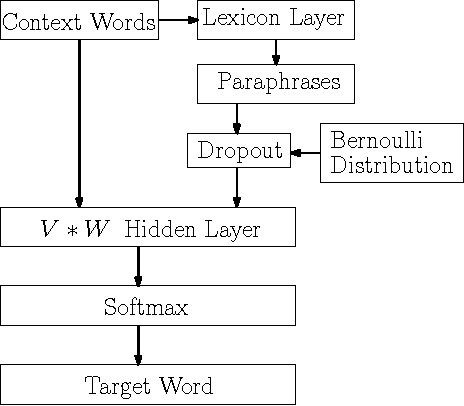
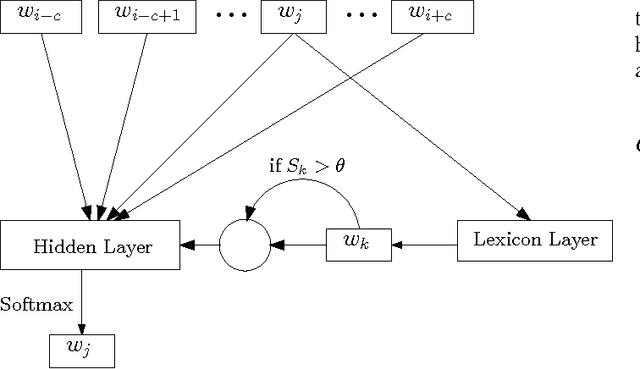
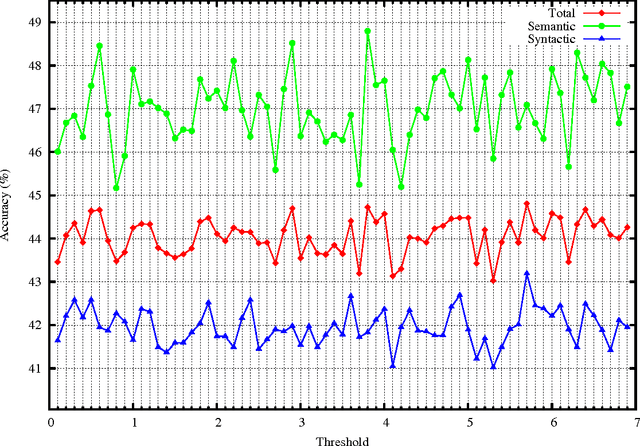
Though there are some works on improving distributed word representations using lexicons, the improper overfitting of the words that have multiple meanings is a remaining issue deteriorating the learning when lexicons are used, which needs to be solved. An alternative method is to allocate a vector per sense instead of a vector per word. However, the word representations estimated in the former way are not as easy to use as the latter one. Our previous work uses a probabilistic method to alleviate the overfitting, but it is not robust with a small corpus. In this paper, we propose a new neural network to estimate distributed word representations using a lexicon and a corpus. We add a lexicon layer in the continuous bag-of-words model and a threshold node after the output of the lexicon layer. The threshold rejects the unreliable outputs of the lexicon layer that are less likely to be the same with their inputs. In this way, it alleviates the overfitting of the polysemous words. The proposed neural network can be trained using negative sampling, which maximizing the log probabilities of target words given the context words, by distinguishing the target words from random noises. We compare the proposed neural network with the continuous bag-of-words model, the other works improving it, and the previous works estimating distributed word representations using both a lexicon and a corpus. The experimental results show that the proposed neural network is more efficient and balanced for both semantic tasks and syntactic tasks than the previous works, and robust to the size of the corpus.