 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy paraphrases in learning word representations with a lexicon
Paper and Code
Sep 08, 2017
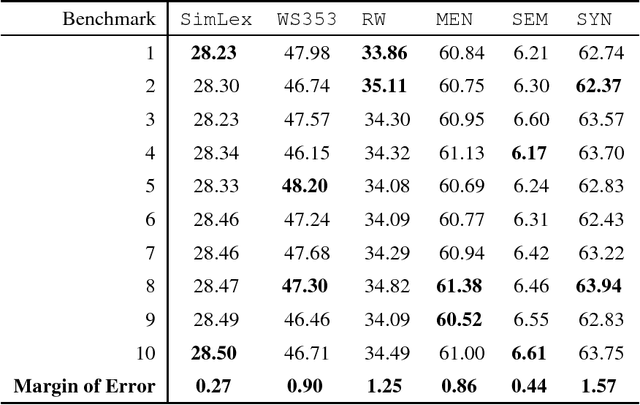
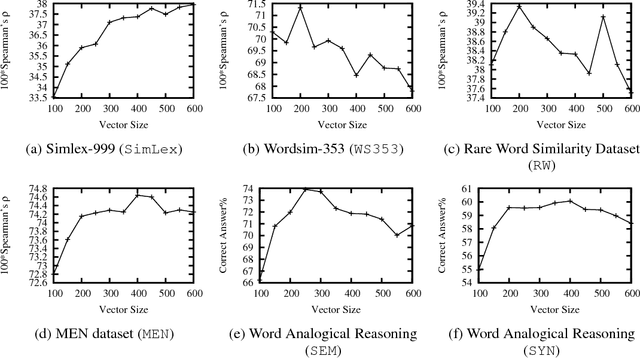

A synonym of a polysemous word is usually only the paraphrase of one sense among many. When lexicons are used to improve vector-space word representations, such paraphrases are unreliable and bring noise to the vector-space. The prior works use a coefficient to adjust the overall learning of the lexicons. They regard the paraphrases equally. In this paper, we propose a novel approach that regards the paraphrases diversely to alleviate the adverse effects of polysemy. We annotate each paraphrase with a degree of reliability. The paraphrases are randomly eliminated according to the degrees when our model learns word representations. In this way, our approach drops the unreliable paraphrases, keeping more reliable paraphrases at the same time. The experimental results show that the proposed method improves the word vectors. Our approach is an attempt to address the polysemy problem keeping one vector per word. It makes the approach easier to use than the conventional methods that estimate multiple vectors for a word. Our approach also outperforms the prior works in the experiments.