 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Iterative Label Refinement via Robust Unlabeled Learning
Feb 18, 2025Recent advances in large language models (LLMs) have yielded impressive performance on various tasks, yet they often depend on high-quality feedback that can be costly. Self-refinement methods attempt to leverage LLMs' internal evaluation mechanisms with minimal human supervision; however, these approaches frequently suffer from inherent biases and overconfidence, especially in domains where the models lack sufficient internal knowledge, resulting in performance degradation. As an initial step toward enhancing self-refinement for broader applications, we introduce an iterative refinement pipeline that employs the Unlabeled-Unlabeled learning framework to improve LLM-generated pseudo-labels for classification tasks. By exploiting two unlabeled datasets with differing positive class ratios, our approach iteratively denoises and refines the initial pseudo-labels, thereby mitigating the adverse effects of internal biases with minimal human supervision. Evaluations on diverse datasets, including low-resource language corpora, patent classifications, and protein structure categorizations, demonstrate that our method consistently outperforms both initial LLM's classification performance and the self-refinement approaches by cutting-edge models (e.g., GPT-4o and DeepSeek-R1).
A Generalized Model for Multidimensional Intransitivity
Sep 28, 2024Intransitivity is a critical issue in pairwise preference modeling. It refers to the intransitive pairwise preferences between a group of players or objects that potentially form a cyclic preference chain and has been long discussed in social choice theory in the context of the dominance relationship. However, such multifaceted intransitivity between players and the corresponding player representations in high dimensions is difficult to capture. In this paper, we propose a probabilistic model that jointly learns each player's d-dimensional representation (d>1) and a dataset-specific metric space that systematically captures the distance metric in Rd over the embedding space. Interestingly, by imposing additional constraints in the metric space, our proposed model degenerates to former models used in intransitive representation learning. Moreover, we present an extensive quantitative investigation of the vast existence of intransitive relationships between objects in various real-world benchmark datasets. To our knowledge, this investigation is the first of this type. The predictive performance of our proposed method on different real-world datasets, including social choice, election, and online game datasets, shows that our proposed method outperforms several competing methods in terms of prediction accuracy.
Impact of Tone-Aware Explanations in Recommender Systems
May 08, 2024


In recommender systems, the presentation of explanations plays a crucial role in supporting users' decision-making processes. Although numerous existing studies have focused on the effects (transparency or persuasiveness) of explanation content, explanation expression is largely overlooked. Tone, such as formal and humorous, is directly linked to expressiveness and is an important element in human communication. However, studies on the impact of tone on explanations within the context of recommender systems are insufficient. Therefore, this study investigates the effect of explanation tones through an online user study from three aspects: perceived effects, domain differences, and user attributes. We create a dataset using a large language model to generate fictional items and explanations with various tones in the domain of movies, hotels, and home products. Collected data analysis reveals different perceived effects of tones depending on the domains. Moreover, user attributes such as age and personality traits are found to influence the impact of tone. This research underscores the critical role of tones in explanations within recommender systems, suggesting that attention to tone can enhance user experience.
SwipeGANSpace: Swipe-to-Compare Image Generation via Efficient Latent Space Exploration
Apr 30, 2024Generating preferred images using generative adversarial networks (GANs) is challenging owing to the high-dimensional nature of latent space. In this study, we propose a novel approach that uses simple user-swipe interactions to generate preferred images for users. To effectively explore the latent space with only swipe interactions, we apply principal component analysis to the latent space of the StyleGAN, creating meaningful subspaces. We use a multi-armed bandit algorithm to decide the dimensions to explore, focusing on the preferences of the user. Experiments show that our method is more efficient in generating preferred images than the baseline methods. Furthermore, changes in preferred images during image generation or the display of entirely different image styles were observed to provide new inspirations, subsequently altering user preferences. This highlights the dynamic nature of user preferences, which our proposed approach recognizes and enhances.
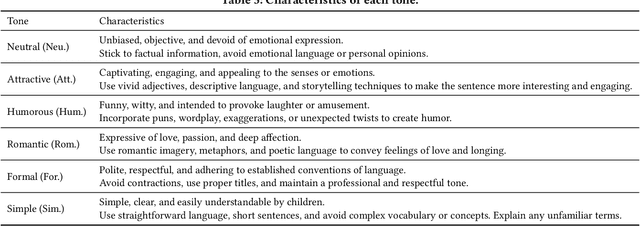
An experimental framework for designing document structure for users' decision making -- An empirical study of recipes
May 02, 2023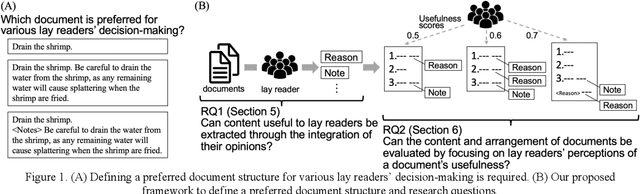

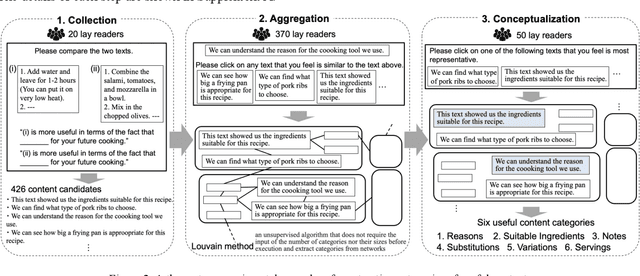
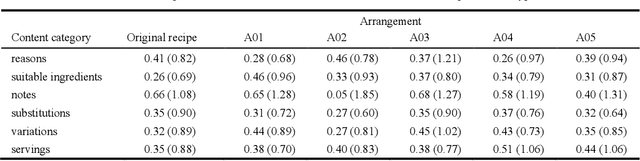
Textual documents need to be of good quality to ensure effective asynchronous communication in remote areas, especially during the COVID-19 pandemic. However, defining a preferred document structure (content and arrangement) for improving lay readers' decision-making is challenging. First, the types of useful content for various readers cannot be determined simply by gathering expert knowledge. Second, methodologies to evaluate the document's usefulness from the user's perspective have not been established. This study proposed the experimental framework to identify useful contents of documents by aggregating lay readers' insights. This study used 200 online recipes as research subjects and recruited 1,340 amateur cooks as lay readers. The proposed framework identified six useful contents of recipes. Multi-level modeling then showed that among the six identified contents, suitable ingredients or notes arranged with a subheading at the end of each cooking step significantly increased recipes' usefulness. Our framework contributes to the communication design via documents.
HumanACGAN: conditional generative adversarial network with human-based auxiliary classifier and its evaluation in phoneme perception
Feb 08, 2021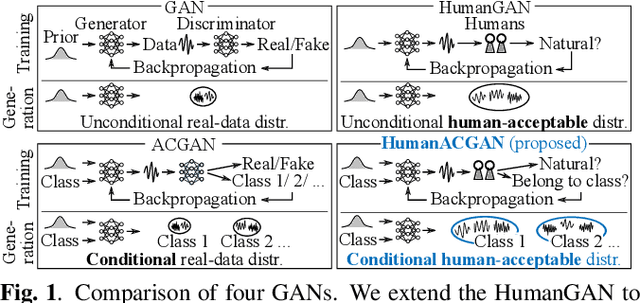
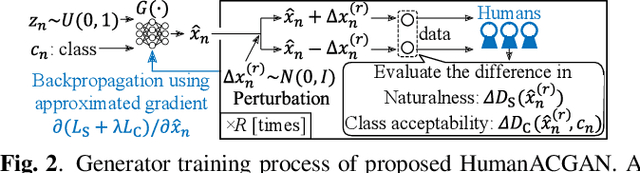

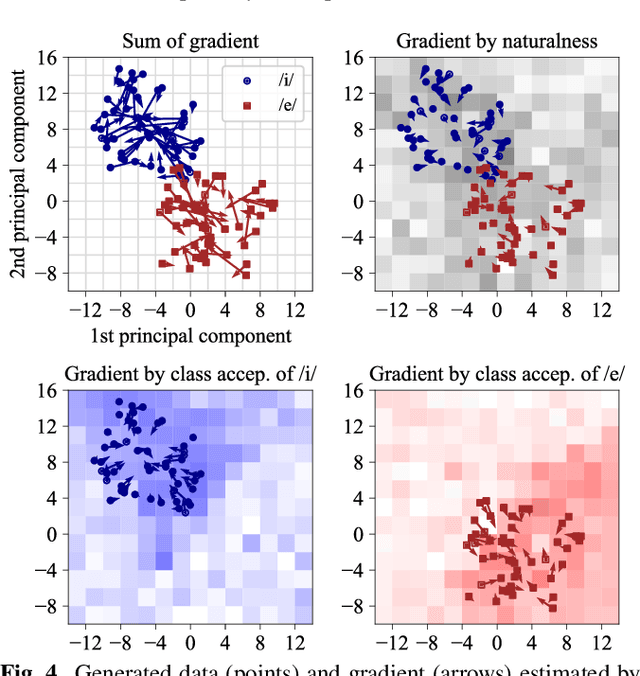
We propose a conditional generative adversarial network (GAN) incorporating humans' perceptual evaluations. A deep neural network (DNN)-based generator of a GAN can represent a real-data distribution accurately but can never represent a human-acceptable distribution, which are ranges of data in which humans accept the naturalness regardless of whether the data are real or not. A HumanGAN was proposed to model the human-acceptable distribution. A DNN-based generator is trained using a human-based discriminator, i.e., humans' perceptual evaluations, instead of the GAN's DNN-based discriminator. However, the HumanGAN cannot represent conditional distributions. This paper proposes the HumanACGAN, a theoretical extension of the HumanGAN, to deal with conditional human-acceptable distributions. Our HumanACGAN trains a DNN-based conditional generator by regarding humans as not only a discriminator but also an auxiliary classifier. The generator is trained by deceiving the human-based discriminator that scores the unconditioned naturalness and the human-based classifier that scores the class-conditioned perceptual acceptability. The training can be executed using the backpropagation algorithm involving humans' perceptual evaluations. Our experimental results in phoneme perception demonstrate that our HumanACGAN can successfully train this conditional generator.
CrowDEA: Multi-view Idea Prioritization with Crowds
Aug 17, 2020

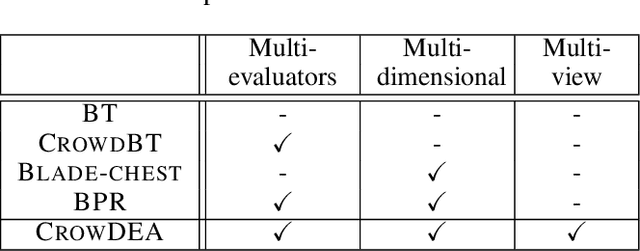
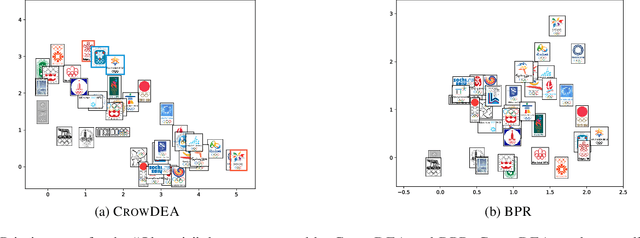
Given a set of ideas collected from crowds with regard to an open-ended question, how can we organize and prioritize them in order to determine the preferred ones based on preference comparisons by crowd evaluators? As there are diverse latent criteria for the value of an idea, multiple ideas can be considered as "the best". In addition, evaluators can have different preference criteria, and their comparison results often disagree. In this paper, we propose an analysis method for obtaining a subset of ideas, which we call frontier ideas, that are the best in terms of at least one latent evaluation criterion. We propose an approach, called CrowDEA, which estimates the embeddings of the ideas in the multiple-criteria preference space, the best viewpoint for each idea, and preference criterion for each evaluator, to obtain a set of frontier ideas. Experimental results using real datasets containing numerous ideas or designs demonstrate that the proposed approach can effectively prioritize ideas from multiple viewpoints, thereby detecting frontier ideas. The embeddings of ideas learned by the proposed approach provide a visualization that facilitates observation of the frontier ideas. In addition, the proposed approach prioritizes ideas from a wider variety of viewpoints, whereas the baselines tend to use to the same viewpoints; it can also handle various viewpoints and prioritize ideas in situations where only a limited number of evaluators or labels are available.
Iterative Machine Teaching without Teachers
Jun 27, 2020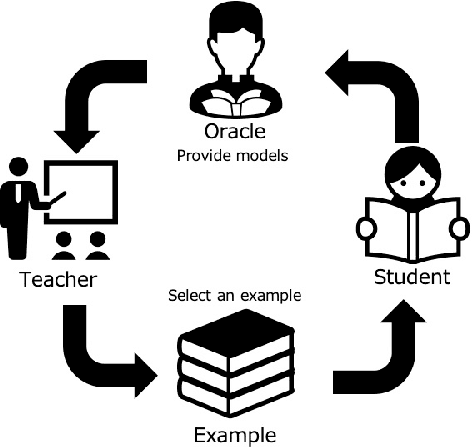
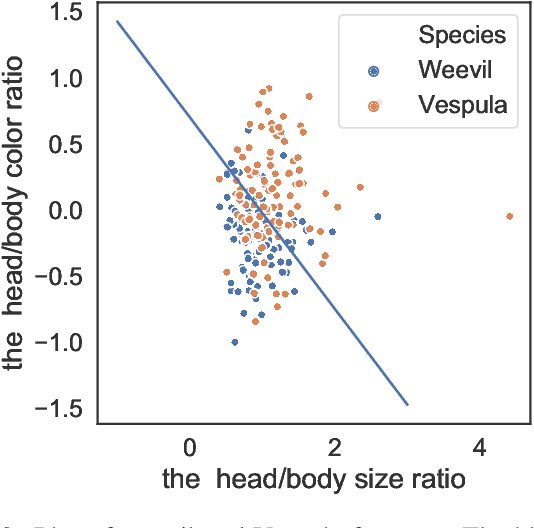
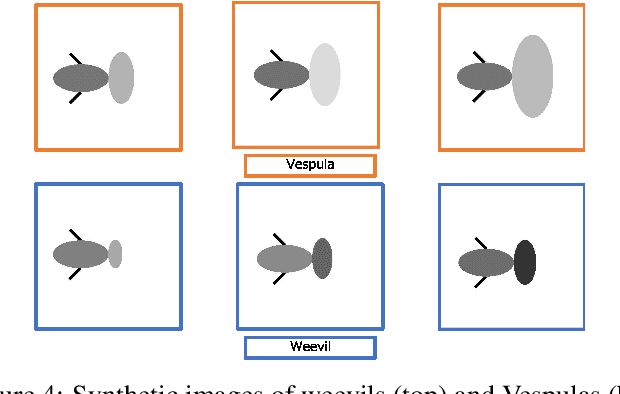
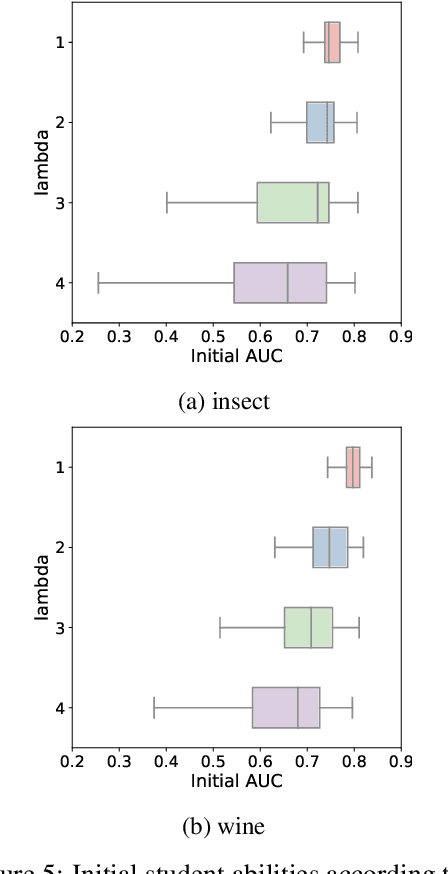
Iterative machine teaching is a method for selecting an optimal teaching example that enables a student to efficiently learn a target concept at each iteration. Existing studies on iterative machine teaching are based on supervised machine learning and assume that there are teachers who know the true answers of all teaching examples. In this study, we consider an unsupervised case where such teachers do not exist; that is, we cannot access the true answer of any teaching example. Students are given a teaching example at each iteration, but there is no guarantee if the corresponding label is correct. Recent studies on crowdsourcing have developed methods for estimating the true answers from crowdsourcing responses. In this study, we apply these to iterative machine teaching for estimating the true labels of teaching examples along with student models that are used for teaching. Our method supports the collaborative learning of students without teachers. The experimental results show that the teaching performance of our method is particularly effective for low-level students in particular.
HumanGAN: generative adversarial network with human-based discriminator and its evaluation in speech perception modeling
Sep 25, 2019

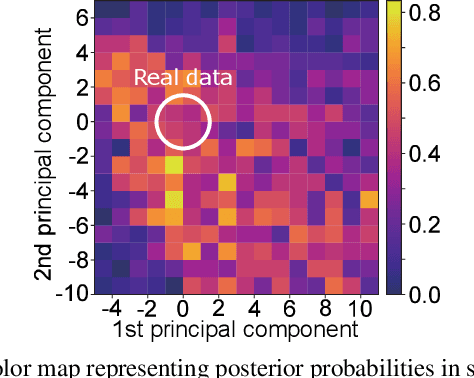

We propose the HumanGAN, a generative adversarial network (GAN) incorporating human perception as a discriminator. A basic GAN trains a generator to represent a real-data distribution by fooling the discriminator that distinguishes real and generated data. Therefore, the basic GAN cannot represent the outside of a real-data distribution. In the case of speech perception, humans can recognize not only human voices but also processed (i.e., a non-existent human) voices as human voice. Such a human-acceptable distribution is typically wider than a real-data one and cannot be modeled by the basic GAN. To model the human-acceptable distribution, we formulate a backpropagation-based generator training algorithm by regarding human perception as a black-boxed discriminator. The training efficiently iterates generator training by using a computer and discrimination by crowdsourcing. We evaluate our HumanGAN in speech naturalness modeling and demonstrate that it can represent a human-acceptable distribution that is wider than a real-data distribution.
BayesGrad: Explaining Predictions of Graph Convolutional Networks
Jul 04, 2018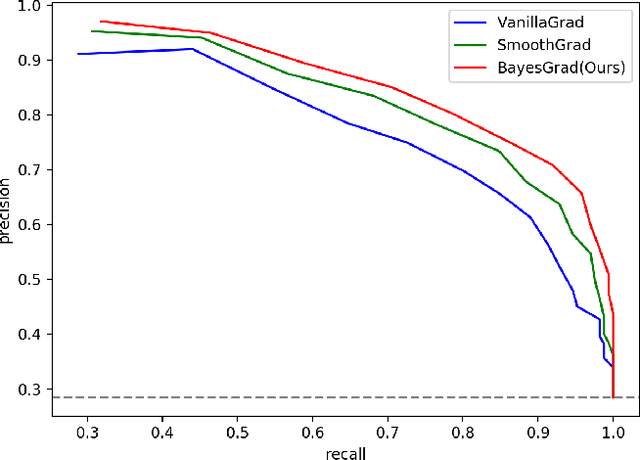
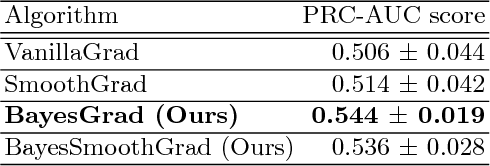
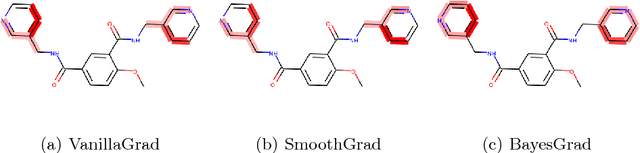
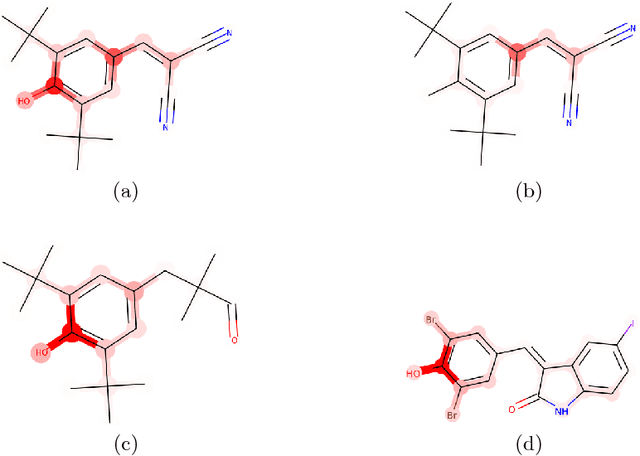
Recent advances in graph convolutional networks have significantly improved the performance of chemical predictions, raising a new research question: "how do we explain the predictions of graph convolutional networks?" A possible approach to answer this question is to visualize evidence substructures responsible for the predictions. For chemical property prediction tasks, the sample size of the training data is often small and/or a label imbalance problem occurs, where a few samples belong to a single class and the majority of samples belong to the other classes. This can lead to uncertainty related to the learned parameters of the machine learning model. To address this uncertainty, we propose BayesGrad, utilizing the Bayesian predictive distribution, to define the importance of each node in an input graph, which is computed efficiently using the dropout technique. We demonstrate that BayesGrad successfully visualizes the substructures responsible for the label prediction in the artificial experiment, even when the sample size is small. Furthermore, we use a real dataset to evaluate the effectiveness of the visualization. The basic idea of BayesGrad is not limited to graph-structured data and can be applied to other data types.