 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Tone-Aware Explanations in Recommender Systems
May 08, 2024


In recommender systems, the presentation of explanations plays a crucial role in supporting users' decision-making processes. Although numerous existing studies have focused on the effects (transparency or persuasiveness) of explanation content, explanation expression is largely overlooked. Tone, such as formal and humorous, is directly linked to expressiveness and is an important element in human communication. However, studies on the impact of tone on explanations within the context of recommender systems are insufficient. Therefore, this study investigates the effect of explanation tones through an online user study from three aspects: perceived effects, domain differences, and user attributes. We create a dataset using a large language model to generate fictional items and explanations with various tones in the domain of movies, hotels, and home products. Collected data analysis reveals different perceived effects of tones depending on the domains. Moreover, user attributes such as age and personality traits are found to influence the impact of tone. This research underscores the critical role of tones in explanations within recommender systems, suggesting that attention to tone can enhance user experience.
Partial Wasserstein Covering
Jun 02, 2021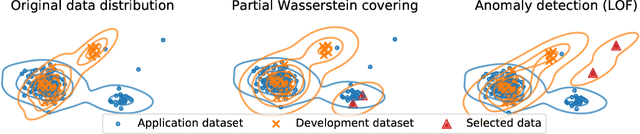
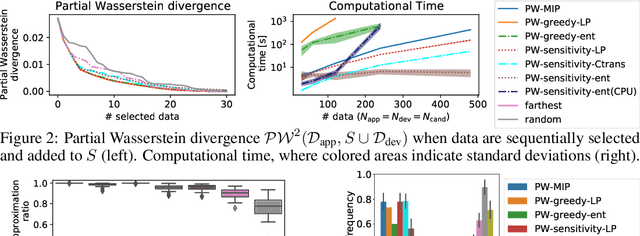
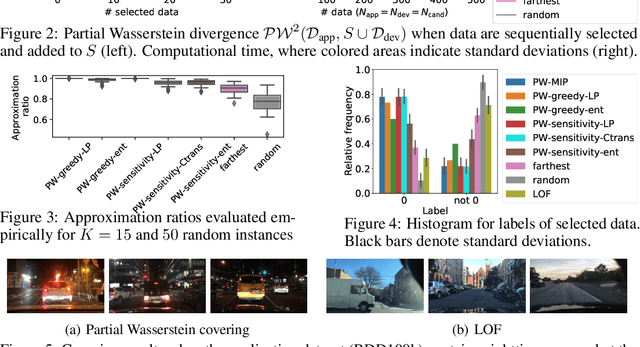
We consider a general task called partial Wasserstein covering with the goal of emulating a large dataset (e.g., application dataset) using a small dataset (e.g., development dataset) in terms of the empirical distribution by selecting a small subset from a candidate dataset and adding it to the small dataset. We model this task as a discrete optimization problem with partial Wasserstein divergence as an objective function. Although this problem is NP-hard, we prove that it has the submodular property, allowing us to use a greedy algorithm with a 0.63 approximation. However, the greedy algorithm is still inefficient because it requires linear programming for each objective function evaluation. To overcome this difficulty, we propose quasi-greedy algorithms for acceleration, which consist of a series of techniques such as sensitivity analysis based on strong duality and the so-called $C$-transform in the optimal transport field. Experimentally, we demonstrate that we can efficiently make two datasets similar in terms of partial Wasserstein divergence, including driving scene datasets.