 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere-to-Unmask: Ground-Truth-Guided Unmasking Order Learning for Masked Diffusion Language Models
Feb 10, 2026Masked Diffusion Language Models (MDLMs) generate text by iteratively filling masked tokens, requiring two coupled decisions at each step: which positions to unmask (where-to-unmask) and which tokens to place (what-to-unmask). While standard MDLM training directly optimizes token prediction (what-to-unmask), inference-time unmasking orders (where-to-unmask) are typically determined by heuristic confidence measures or trained through reinforcement learning with costly on-policy rollouts. To address this, we introduce Gt-Margin, a position-wise score derived from ground-truth tokens, defined as the probability margin between the correct token and its strongest alternative. Gt-Margin yields an oracle unmasking order that prioritizes easier positions first under each partially masked state. We demonstrate that leveraging this oracle unmasking order significantly enhances final generation quality, particularly on logical reasoning benchmarks. Building on this insight, we train a supervised unmasking planner via learning-to-rank to imitate the oracle ordering from masked contexts. The resulting planner integrates into standard MDLM sampling to select where-to-unmask, improving reasoning accuracy without modifying the token prediction model.
Self Iterative Label Refinement via Robust Unlabeled Learning
Feb 18, 2025Recent advances in large language models (LLMs) have yielded impressive performance on various tasks, yet they often depend on high-quality feedback that can be costly. Self-refinement methods attempt to leverage LLMs' internal evaluation mechanisms with minimal human supervision; however, these approaches frequently suffer from inherent biases and overconfidence, especially in domains where the models lack sufficient internal knowledge, resulting in performance degradation. As an initial step toward enhancing self-refinement for broader applications, we introduce an iterative refinement pipeline that employs the Unlabeled-Unlabeled learning framework to improve LLM-generated pseudo-labels for classification tasks. By exploiting two unlabeled datasets with differing positive class ratios, our approach iteratively denoises and refines the initial pseudo-labels, thereby mitigating the adverse effects of internal biases with minimal human supervision. Evaluations on diverse datasets, including low-resource language corpora, patent classifications, and protein structure categorizations, demonstrate that our method consistently outperforms both initial LLM's classification performance and the self-refinement approaches by cutting-edge models (e.g., GPT-4o and DeepSeek-R1).
Counterfactual Fairness Filter for Fair-Delay Multi-Robot Navigation
May 19, 2023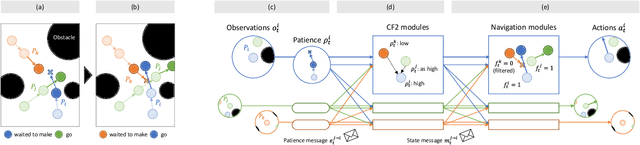
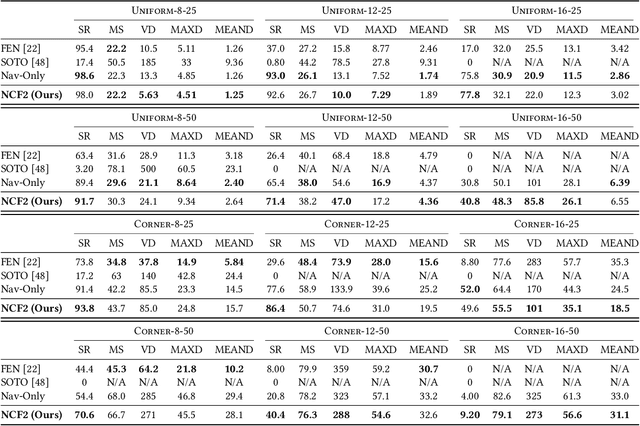
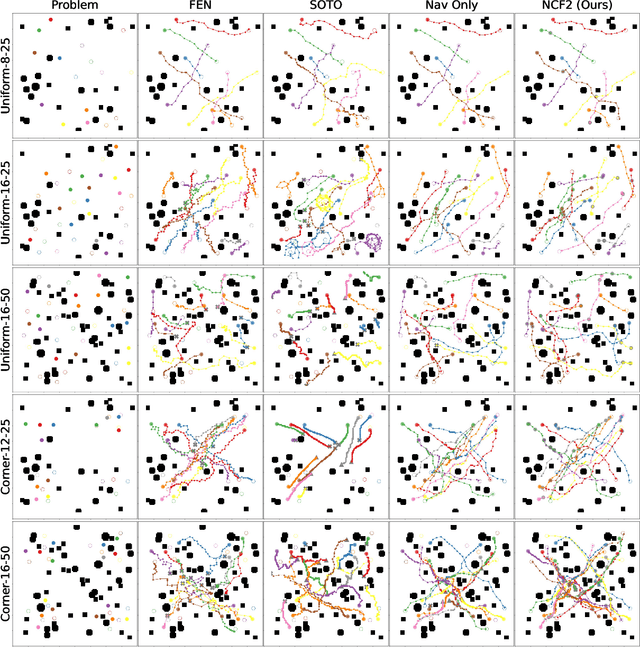
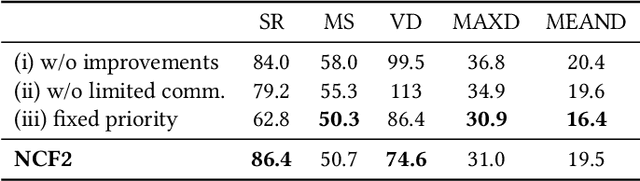
Multi-robot navigation is the task of finding trajectories for a team of robotic agents to reach their destinations as quickly as possible without collisions. In this work, we introduce a new problem: fair-delay multi-robot navigation, which aims not only to enable such efficient, safe travels but also to equalize the travel delays among agents in terms of actual trajectories as compared to the best possible trajectories. The learning of a navigation policy to achieve this objective requires resolving a nontrivial credit assignment problem with robotic agents having continuous action spaces. Hence, we developed a new algorithm called Navigation with Counterfactual Fairness Filter (NCF2). With NCF2, each agent performs counterfactual inference on whether it can advance toward its goal or should stay still to let other agents go. Doing so allows us to effectively address the aforementioned credit assignment problem and improve fairness regarding travel delays while maintaining high efficiency and safety. Our extensive experimental results in several challenging multi-robot navigation environments demonstrate the greater effectiveness of NCF2 as compared to state-of-the-art fairness-aware multi-agent reinforcement learning methods. Our demo videos and code are available on the project webpage: https://omron-sinicx.github.io/ncf2/
Sequential Bayesian experimental designs via reinforcement learning
Feb 14, 2022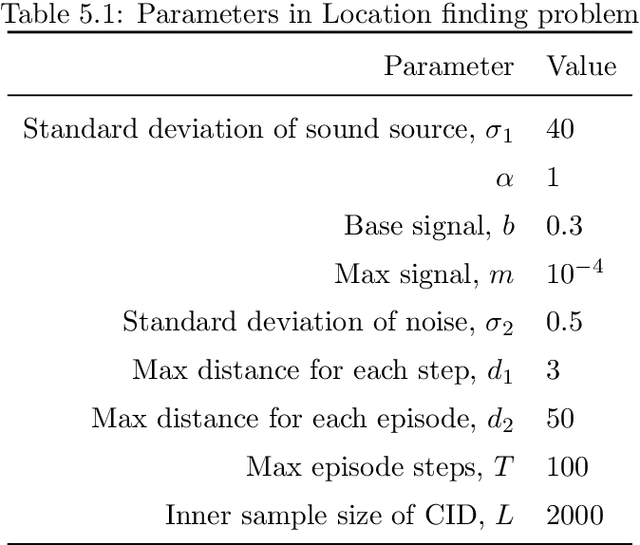
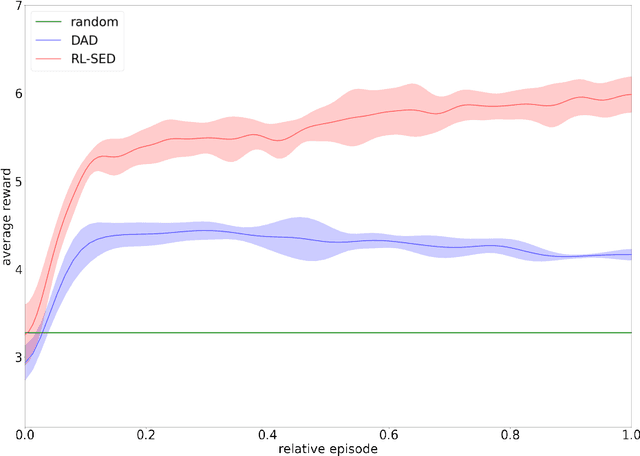
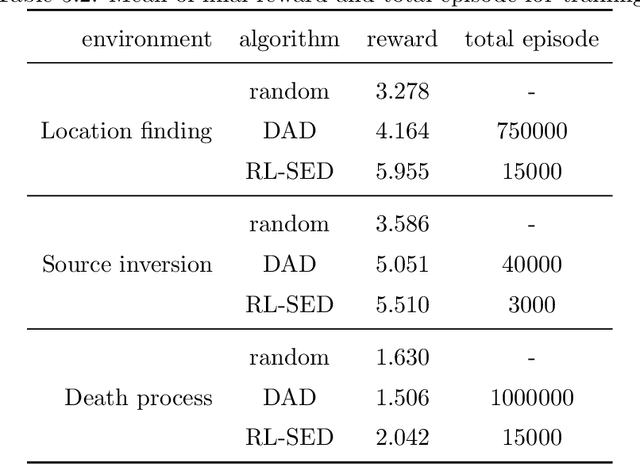
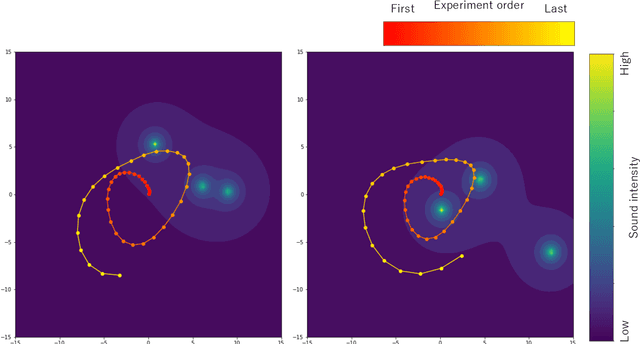
Bayesian experimental design (BED) has been used as a method for conducting efficient experiments based on Bayesian inference. The existing methods, however, mostly focus on maximizing the expected information gain (EIG); the cost of experiments and sample efficiency are often not taken into account. In order to address this issue and enhance practical applicability of BED, we provide a new approach Sequential Experimental Design via Reinforcement Learning to construct BED in a sequential manner by applying reinforcement learning in this paper. Here, reinforcement learning is a branch of machine learning in which an agent learns a policy to maximize its reward by interacting with the environment. The characteristics of interacting with the environment are similar to the sequential experiment, and reinforcement learning is indeed a method that excels at sequential decision making. By proposing a new real-world-oriented experimental environment, our approach aims to maximize the EIG while keeping the cost of experiments and sample efficiency in mind simultaneously. We conduct numerical experiments for three different examples. It is confirmed that our method outperforms the existing methods in various indices such as the EIG and sampling efficiency, indicating that our proposed method and experimental environment can make a significant contribution to application of BED to the real world.