 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMNI: Open-endedness via Models of human Notions of Interestingness
Paper and Code
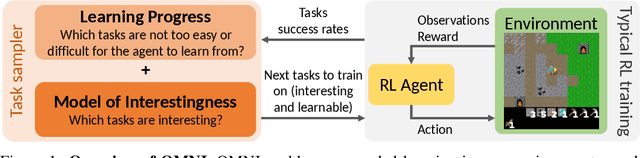

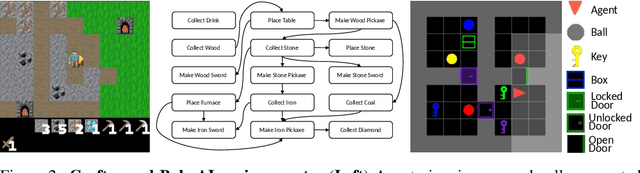
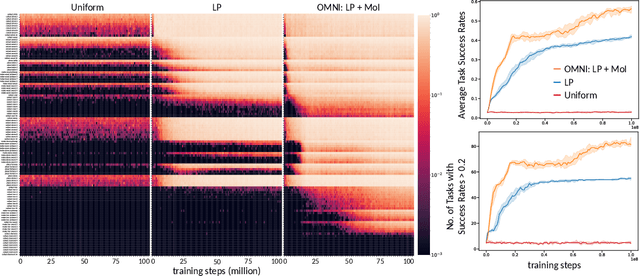
Open-ended algorithms aim to learn new, interesting behaviors forever. That requires a vast environment search space, but there are thus infinitely many possible tasks. Even after filtering for tasks the current agent can learn (i.e., learning progress), countless learnable yet uninteresting tasks remain (e.g., minor variations of previously learned tasks). An Achilles Heel of open-endedness research is the inability to quantify (and thus prioritize) tasks that are not just learnable, but also $\textit{interesting}$ (e.g., worthwhile and novel). We propose solving this problem by $\textit{Open-endedness via Models of human Notions of Interestingness}$ (OMNI). The insight is that we can utilize large (language) models (LMs) as a model of interestingness (MoI), because they $\textit{already}$ internalize human concepts of interestingness from training on vast amounts of human-generated data, where humans naturally write about what they find interesting or boring. We show that LM-based MoIs improve open-ended learning by focusing on tasks that are both learnable $\textit{and interesting}$, outperforming baselines based on uniform task sampling or learning progress alone. This approach has the potential to dramatically advance the ability to intelligently select which tasks to focus on next (i.e., auto-curricula), and could be seen as AI selecting its own next task to learn, facilitating self-improving AI and AI-Generating Algorithms.