 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Diversity through AI Feedback
Oct 31, 2023



In many text-generation problems, users may prefer not only a single response, but a diverse range of high-quality outputs from which to choose. Quality-diversity (QD) search algorithms aim at such outcomes, by continually improving and diversifying a population of candidates. However, the applicability of QD to qualitative domains, like creative writing, has been limited by the difficulty of algorithmically specifying measures of quality and diversity. Interestingly, recent developments in language models (LMs) have enabled guiding search through AI feedback, wherein LMs are prompted in natural language to evaluate qualitative aspects of text. Leveraging this development, we introduce Quality-Diversity through AI Feedback (QDAIF), wherein an evolutionary algorithm applies LMs to both generate variation and evaluate the quality and diversity of candidate text. When assessed on creative writing domains, QDAIF covers more of a specified search space with high-quality samples than do non-QD controls. Further, human evaluation of QDAIF-generated creative texts validates reasonable agreement between AI and human evaluation. Our results thus highlight the potential of AI feedback to guide open-ended search for creative and original solutions, providing a recipe that seemingly generalizes to many domains and modalities. In this way, QDAIF is a step towards AI systems that can independently search, diversify, evaluate, and improve, which are among the core skills underlying human society's capacity for innovation.
OMNI: Open-endedness via Models of human Notions of Interestingness
Jun 02, 2023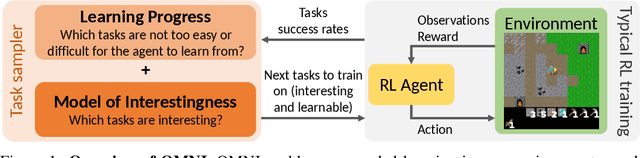

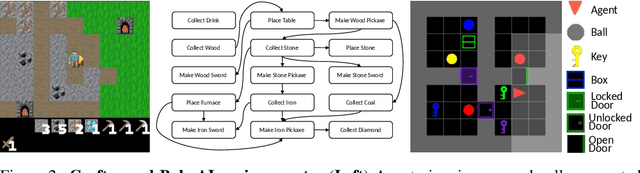
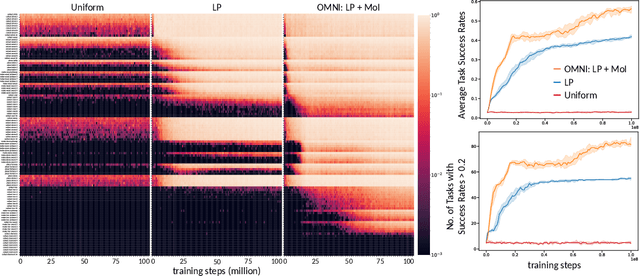
Open-ended algorithms aim to learn new, interesting behaviors forever. That requires a vast environment search space, but there are thus infinitely many possible tasks. Even after filtering for tasks the current agent can learn (i.e., learning progress), countless learnable yet uninteresting tasks remain (e.g., minor variations of previously learned tasks). An Achilles Heel of open-endedness research is the inability to quantify (and thus prioritize) tasks that are not just learnable, but also $\textit{interesting}$ (e.g., worthwhile and novel). We propose solving this problem by $\textit{Open-endedness via Models of human Notions of Interestingness}$ (OMNI). The insight is that we can utilize large (language) models (LMs) as a model of interestingness (MoI), because they $\textit{already}$ internalize human concepts of interestingness from training on vast amounts of human-generated data, where humans naturally write about what they find interesting or boring. We show that LM-based MoIs improve open-ended learning by focusing on tasks that are both learnable $\textit{and interesting}$, outperforming baselines based on uniform task sampling or learning progress alone. This approach has the potential to dramatically advance the ability to intelligently select which tasks to focus on next (i.e., auto-curricula), and could be seen as AI selecting its own next task to learn, facilitating self-improving AI and AI-Generating Algorithms.