 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Tabular Datasets through LLMs to Rapidly Explore Hypotheses about Real-World Entities
Paper and Code
Nov 27, 2024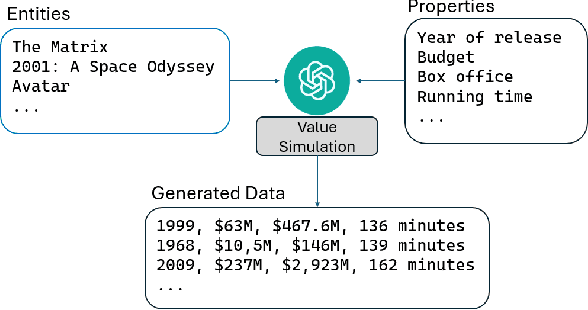
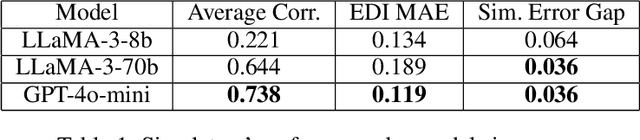


Do horror writers have worse childhoods than other writers? Though biographical details are known about many writers, quantitatively exploring such a qualitative hypothesis requires significant human effort, e.g. to sift through many biographies and interviews of writers and to iteratively search for quantitative features that reflect what is qualitatively of interest. This paper explores the potential to quickly prototype these kinds of hypotheses through (1) applying LLMs to estimate properties of concrete entities like specific people, companies, books, kinds of animals, and countries; (2) performing off-the-shelf analysis methods to reveal possible relationships among such properties (e.g. linear regression); and towards further automation, (3) applying LLMs to suggest the quantitative properties themselves that could help ground a particular qualitative hypothesis (e.g. number of adverse childhood events, in the context of the running example). The hope is to allow sifting through hypotheses more quickly through collaboration between human and machine. Our experiments highlight that indeed, LLMs can serve as useful estimators of tabular data about specific entities across a range of domains, and that such estimations improve with model scale. Further, initial experiments demonstrate the potential of LLMs to map a qualitative hypothesis of interest to relevant concrete variables that the LLM can then estimate. The conclusion is that LLMs offer intriguing potential to help illuminate scientifically interesting patterns latent within the internet-scale data they are trained upon.